
字符编码
是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
编码表的由来:计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表。这就是编码表。
常见的编码表:
- ASCII:美国标准信息交换码。用一个字节的 7 位可以表示。
- ISO8859-1:拉丁码表,欧洲码表。用一个字节的 8 位表示。
- GB2312:中国的中文编码表。最多两个字节编码所有字符。
- GBK:中国的中文编码表升级,融合了更多的中文文字符号。最多两个字节编码。
- Unicode:国际标准码,融合了目前人类使用的所有字符。为每个字符分配唯一的字符码。所有的文字都用两个字节来表示。
- UTF-8:变长的编码方式,可用 1 ~ 4 个字节来表示一个字符。
在 Unicode 出现之前,所有的字符集都是和具体编码方案绑定在一起的,即字符集 ≈ 编码方式,都是直接将字符和最终字节流绑定死了。
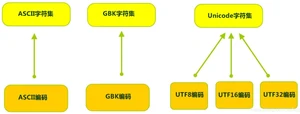
- GBK 等双字节编码方式,用最高位是 1 或 0 表示两个字节和一个字java号码基础类型节。
- Unicode 不完美,这里就有三个问题,一个是,我们已经知道,英文字母只用一个字节表示就够了,第二个问题是如何才能区别 Unicode 和 ASCII,计算机怎么知道是两个字节表示一个符号,而不是分别表示两个符号呢?第三个,如果和 GBK 等双字节编码方式一样,用最高位是 1 或 0 表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符。Unicode 在很长一段时间内无法推广,直到互联网的出现。
- 面向传输的 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8 就是每次 8 个位传输数据,而 UTF-16 就是每次 16 个位。这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
- Unicode 只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的 Unicode 编码是 UTF-8 和 UTF-16。

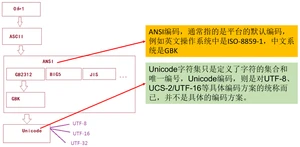
计算机中储存的信息都是用二进制数表示的,而能在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为 。
- 比如说,按照 A 规则存储,同样按照 A 规则解析,那么就能显示正确的文本符号。反之,按照 A 规则存储,再按照 B 规则解析,就会导致乱码现象。
- 编码: 字符串 ---> 字节数组。
- 解码: 字节数组 ---> 字符串。
- 启示:客户端/浏览器端 <------> 后台(Java,GO,Python,Node.js,php...) <------> 数据库,要求前前后后使用的字符集要统一,都使用 UTF-8,这样才不会乱码。
File 类
路径分隔符
:
- 路径中的每级目录之间用一个路径分隔符隔开。
- 路径分隔符和系统有关:
- Windows 和 DOS 系统默认使用来表示。
- UNIX 和 URL 使用来表示。
- Java 程序支持跨平台运行,因此路径分隔符要慎用。为了解决这个隐患,File 类提供了一个常量,能够根据操作系统,动态的提供分隔符。
- 示例:
File 定义
类:文件和文件目录路径的抽象表示形式,与平台无关。
- File 主要表示类似与,前者是文件夹(directory),后者则是文件(file),而 File 类就是操作这两者的类。
File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
- File 跟流无关,File 类不能对文件进行读和写,也就是输入和输出。
想要在 Java 程序中表示一个真实存在的文件或目录,那么必须有一个 File 对象,但是 Java 程序中的一个 File 对象,可能不对应一个真实存在的文件或目录。
File 构造方法
File 常用的构造方法:
- :以 pathname 为路径创建 File 对象,可以是绝对路径或者相对路径,如果 pathname 是相对路径,则默认的当前路径在系统属性 user.dir 中存储。
- :是一个固定的路径,从盘符开始。
- :是相对于某个位置开始。
- IDEA 中的路径说明,main() 和 Test 中,相对路径不一样:
- :以 parent 为父路径,child 为子路径创建 File 对象。
- :根据一个父 File 对象和子文件路径创建 File 对象。
File 基础信息
获取 File 基础信息的方法:
- :获取绝对路径。
- :获取路径。
- :获取名称。
- :获取上层文件目录路径。若无,返回 null。
- :获取文件长度,即:字节数。不能获取目录的长度。
- :获取最后一次的修改时间,毫秒值。
- :获取指定目录下的所有文件或者文件目录的名称数组,如果指定目录不存在,返回 null。
- :获取指定目录下的所有文件或者文件目录的 File 数组,如果指定目录不存在,返回 null。
- :指定文件过滤器。
- :指定文件过滤器。
- :指定文件过滤器。
File 重命名
File 重命名的方法:
- :把文件重命名为指定的文件路径。以为例:要想保证返回 true,需要 file1 在硬盘中是存在的,且 file2 在硬盘中不能存在。
File 判断
判断 File 相关信息的方法:
- :判断是否存在。
- :判断是否是文件目录。
- :判断是否是文件。
- :判断是否可读。
- :判断是否可写。
- :判断是否隐藏。
File 创建
创建 File 的方法:
- :创建文件。若文件不存在,则创建一个新的空文件并返回 true;若文件存在,则不创建文件并返回 false。
- :创建文件目录。如果此文件目录存在,则不创建;如果此文件目录的上层目录不存在,也不创建。
- :创建文件目录。如果上层文件目录不存在,也一并创建。
- 如果创建文件或者文件目录时,没有写盘符路径,那么,默认在项目路径下。
File 删除
删除 File 的方法:
- :删除文件或者文件夹。
- Java 中的删除不走回收站。要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录,即。
File 遍历
文件夹下所有文件以及子文件:
NIO.2 中 Path 、Paths 、Files
是从 Java 1.4 版本开始引入的一套新的 I/O API,可以替代标准的 Java I/O API。NIO 与原来的 I/O 有同样的作用和目的,但是使用的方式完全不同,NIO 支持面向缓冲区的(I/O是面向流的)、基于通道的 I/O 操作,NIO 也会以更加高效的方式进行文件的读写操作。
Java API 中提供了两套 NIO,一套是针对标准输入输出 NIO,另一套就是网络编程 NIO。
- |-----
- |----- :处理本地文件。
- |----- :TCP 网络编程的客户端的 Channel。
- |----- :TCP 网络编程的服务器端的 Channel。
- |----- :UDP 网络编程中发送端和接收端的 Channel。
- |----- :处理本地文件。
随着 JDK 7 的发布,Java 对 NIO 进行了极大的扩展,增强了对文件处理和文件系统特性的支持,以至于我们称他们为 NIO.2。因为 NIO 提供的一些功能,NIO 已经成为文件处理中越来越重要的部分。
早期的 Java 只提供了一个 File 类来访问文件系统,但 File 类的功能比较有限,所提供的方法性能也不高。而且,大多数方法在出错时仅返回失败,并不会提供异常信息。
NIO. 2 为了弥补这种不足,引入了 Path 接口,代表一个平台无关的平台路径,描述了目录结构中文件的位置。Path 可以看成是 File 类的升级版本,实际引用的资源也可以不存在。
在以前 I/O 操作是类似如下写法的:
但在 JDK 7 中,我们可以这样写:
同时,NIO.2 在包下还提供了 Files、Paths 工具类,Files 包含了大量静态的工具方法来操作文件;Paths 则包含了两个返回 Path 的静态工厂方法。
Paths 类提供的获取 Path 对象的方法:
- :用于将多个字符串串连成路径。
- :返回指定 uri 对应的 Path 路径。
Path 类常用方法:
- :返回调用 Path 对象的字符串表示形式。
- :判断是否以 path 路径开始。
- :判断是否以 path 路径结束。
- :判断是否是绝对路径。
- :返回 Path 对象包含整个路径,不包含 Path 对象指定的文件路径。
- :返回调用 Path 对象的根路径。
- :返回与调用 Path 对象关联的文件名。
- :返回 Path 根目录后面元素的数量。
- :返回指定索引位置 idx 的路径名称。
- :作为绝对路径返回调用 Path 对象。
- :合并两个路径,返回合并后的路径对应的 Path 对象。
- :将 Path 转化为 File 类的对象。File 类转化为 Path 对象的方法是:。
:用于操作文件或目录的工具类。常用方法:
- :文件的复制。
- :创建一个目录。
- :创建一个文件。
- :删除一个文件/目录,如果不存在,执行报错。
- :Path 对应的文件/目录如果存在,执行删除。
- :将 src 移动到 dest 位置。
- :返回 path 指定文件的大小。
- :判断文件是否存在。
- :判断是否是目录。
- :判断是否是文件。
- :判断是否是隐藏文件。
- :判断文件是否可读。
- :判断文件是否可写。
- :判断文件是否不存在。
- :获取与指定文件的连接,how 指定打开方式。
- :打开 path 指定的目录。
- :获取 InputStream 对象。
- :获取 OutputStream 对象。
FileUtils 工具类
Maven 引入依赖:
复制功能:
遍历文件夹和文件的每一行:
I/O 流
I/O 的原理
是 Input/Output 的缩写, I/O 技术是非常实用的技术,用于处理设备之间的。如读/写文件,网络通讯等。
- Java 程序中,对于数据的输入/输出操作以的方式进行。
- 包下提供了各种 "流" 类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。
:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
:将程序(内存)数据输出到磁盘、光盘等外部存储设备中。
I/O 的分类
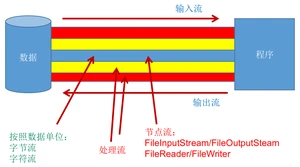
按操作不同分为:字节流(8 bit),字符流(16 bit)。
- :以字节为单位,读写数据的流。
- :以字符为单位,读写数据的流。
按数据流的不同分为:输入流,输出流。
- :把数据从其他设备上读取到内存中的流。
- :把数据从内存中写出到其他设备上的流。
按流的的不同分为:节点流,处理流。
- :直接从数据源或目的地读写数据。也叫文件流。

- :不直接连接到数据源或目的地,而是连接在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能。

Java 的 I/O 流共涉及 40 多个类,实际上非常规则,都是从如下派生的。同时,由这四个类派生出来的子类名称都是以其父类名作为子类名后缀:

I/O 流体系:
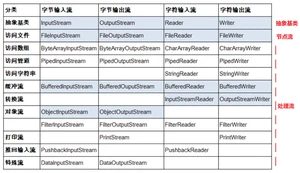
I/O 的四个抽象基类
InputStream & Reader
- InputStream 的典型实现:FileInputStream。
- FileInputStream:用于读取非文本数据的原始字节流。
- Reader 的典型实现:FileReader。
- FileReader:用于读取文本数据的字符流。
InputStream
InputStream 的方法:
- :从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。
- :从输入流中将最多个字节的数据读入一个 byte 数组中。以整数形式返回实际读取的字节数。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。
- :将输入流中最多 len 个数据字节读入 byte 数组。尝试读取 len 个字节,但读取的字节也可能小于该值。以整数形式返回实际读取的字节数。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。
- :关闭输入流并释放与该流关联的所有系统资源。
Reader
Reader 的方法:
- :读取单个字符。作为整数读取的字符,范围在 0 到 65535 之间(0x00-0xffff)(2 个字节的 Unicode 码),如果已到达流的末尾,则返回 -1。
- :将字符读入数组。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。
- :将字符读入数组的某一部分。存到数组 cbuf 中,从 off 处开始存储,最多读 len 个字符。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。
- :关闭此输入流并释放与该流关联的所有系统资源。
OutputStream & Writer
- OutputStream 的典型实现:FileOutStream。
- FileOutputStream:用于写出非文本数据的原始字节流。
- Writer 的典型实现:FileWriter。
- FileWriter:用于写出文本数据的字符流。
OutputStream
OutputStream 的方法:
- :将指定的字节写入此输出流。write 的常规协定是:向输出流写入一个字节。要写入的字节是参数 b 的八个低位。b 的 24 个高位将被忽略,即写入 0 ~ 255 范围的。
- :将 b.length() 个字节从指定的 byte 数组写入此输出流。write(b) 的常规协定是:应该与调用 write(b, 0, b.length) 的效果完全相同。
- :将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。
- :刷新此输出流并强制写出所有缓冲的输出字节,调用此方法指示应将这些字节立即写入它们预期的目标。
- :关闭此输出流并释放与该流关联的所有系统资源。
Writer
Writer 的方法:
- :写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。 即写入 0 到 65535 之间的 Unicode 码。
- :写入字符数组。
- :写入字符数组的某一部分。从 off 开始,写入 len 个字符。
- :写入字符串。
- :写入字符串的某一部分。
- :刷新该流的缓冲,则立即将它们写入预期目标。
- :关闭此输出流并释放与该流关联的所有系统资源。
节点流(或文件流)
读取文件流程:
- 实例化 File 类的对象,指明要操作的文件。
- 提供具体的流对象。
- 数据的读入。
- 流的关闭操作。
写入文件流程:
- 实例化 File 类的对象,指明写出到的文件。
- 提供具体的流对象。
- 数据的写入。
- 流的关闭操作。
注意事项:
- 定义文件路径时,可以用 / 或者 。
- 在读取文件时,必须保证该文件已存在,否则报异常。
- 对于(.jpg,.mp3,.mp4,.avi,.rmvb,.doc,.ppt 等),使用处理。如果使用字节流操作文本文件,在输出到控制台时,可能会出现乱码。
- 对于(.txt,.java,.c,.cpp 等),使用处理。
FileInputStream 和 FileOutputStream
在写入一个文件时,如果使用构造器,则目录下有同名文件将被覆盖。如果使用构造器,则目录下的同名文件不会被覆盖,而是在文件内容末尾追加内容。
FileReader 和 FileWriter
处理流
缓冲流
为了提高数据读写的速度,Java API 提供了带缓冲功能的流类,在使用这些流类时,会创建一个内部缓冲区数组,。
缓冲流要 "套接" 在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
- 和
- :创建一个新的缓冲输入流,注意参数类型为 InputStream。
- : 创建一个新的缓冲输出流,注意参数类型为 OutputStream。
- 和
- :创建一个新的缓冲输入流,注意参数类型为 Reader。
- : 创建一个新的缓冲输出流,注意参数类型为 Writer。
当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区。
当使用 BufferedInputStream 读取字节文件时,BufferedInputStream 会一次性从文件中读取 8192 个字节(8Kb)存在缓冲区中,直到缓冲区装满了,才重新从文件中读取下一个 8192 个字节数组。
向流中写入字节时,不会直接写到文件,先写到缓冲区中直到缓冲区写满,BufferedOutputStream 才会把缓冲区中的数据一次性写到文件里。使用可以强制将缓冲区的内容全部写入输出流。
- 的使用:手动将 buffer 中内容写入文件。
- 如果使用带缓冲区的流对象的,不但会关闭流,还会在关闭流之前刷新缓冲区,但关闭流后不能再写出。
流程示意图:
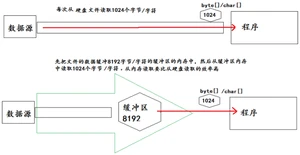
实现非文本文件及文本文件的复制:
实现图片加密:
获取文本上每个字符出现的次数:
转换流
- 字节流中的数据都是字符时,转成字符流操作更高效。
- 很多时候我们使用转换流来处理文件乱码问题,实现编码和解码的功能。
Java API 提供了两个转换流:
-
- :创建一个使用默认字符集的字符流。
- :创建一个指定字符集的字符流。
-
- :创建一个使用默认字符集的字符流。
- :创建一个指定字符集的字符流。
InputStreamReader:
- 实现将字节的输入流按指定字符集转换为字符的输入流。
- 需要和 InputStream 套接。
- 构造器
-
- 比如:,指定字符集为 gbk。
-
OutputStreamWriter:
- 实现将字符的输出流按指定字符集转换为字节的输出流。
- 需要和 OutputStream 套接。
- 构造器
使用 InputStreamReader 解码时,使用的字符集取决于 OutputStreamWriter 编码时使用的字符集。
流程示意图:
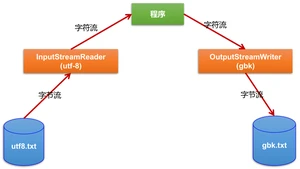

转换流的编码应用:
- 可以将字符按指定编码格式存储。
- 可以对文本数据按指定编码格式来解读。
- 指定编码表的动作由构造器完成。
为了达到最高效率,可以考虑在 BufferedReader 内包装 InputStreamReader:
示例:
标准输入、输出流
和分别代表了系统标准的输入和输出设备。
- 默认输入设备是:键盘,输出设备是:显示器。
- 的类型是 InputStream。
- 的类型是 PrintStream,其是 OutputStream 的子类 FilterOutputStream 的子类。
重定向:通过 System 类的和对默认设备进行改变。
示例:
模拟 Scanner:
打印流
实现将基本数据类型的数据格式转化为字符串输出。
打印流:和。
- 提供了一系列重载的和,用于多种数据类型的输出。
- PrintStream 和 PrintWriter 的输出不会抛出 IOException 异常。
- PrintStream 和 PrintWriter 有自动 flush 功能。
- PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter 类。
- System.out 返回的是 PrintStream 的实例。
把标准输出流(控制台输出)改成文件:
数据流
为了方便地操作 Java 语言的基本数据类型和 String 类型的数据,可以使用数据流。(不能操作内存中的对象)
数据流有两个类:分别用于读取和写出基本数据类型、String类的数据。
- 和。
- 分别套接在 InputStream 和 和 OutputStream 子类的流上。
- 用 DataOutputStream 输出的文件需要用 DataInputStream 来读取。
- DataInputStream 读取不同类型的数据的顺序,要与当初 DataOutputStream 写入文件时,保存的数据的顺序一致。
DataInputStream 中的方法:
- ,
- ,
- ,
- ,
- ,
DataOutputStream 中的方法:
- 将上述的方法的 read 改为相应的 write 即可。
将内存中的字符串、基本数据类型的变量写出到文件中,再读取到内存中:
对象流
和:用于存储和读取基本数据类型数据或对象的处理流。它的强大之处就是可以把 Java 中的对象写入到数据源中,也能把对象从数据源中还原回来。
- 一般情况下,会把对象转换为 Json 字符串,然后进行序列化和反序列化操作,而不是直接操作对象。
序列化:用 ObjectOutputStream 类保存基本类型数据或对象的机制。
反序列化:用 ObjectInputStream 类读取基本类型数据或对象的机制。
ObjectOutputStream 和 ObjectInputStream 不能序列化 static 和 transient 修饰的成员变量。
- 在序列化一个类的对象时,如果类中含有 static 和 transient 修饰的成员变量,则在反序列化时,这些成员变量的值会变成默认值,而不是序列化时这个对象赋予的值。比如,Person 类含有一个 static 修饰的 String name 属性,序列化时,对象把 name 赋值为张三,在反序列化时,name 会变为 null。

对象序列化机制允许把内存中的 Java 对象转换成平台无关的二进制流(),从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。当其它程序获取了这种二进制流,就可以恢复成原来的 Java 对象()。
- 序列化的好处在于可将任何实现了 Serializable 接口的对象转化为,使其在保存和传输时可被还原。
- 序列化是 RMI(Remote Method Invoke – 远程方法调用)过程的参数和返回值都必须实现的机制,而 RMI 是 JavaEE 的基础,因此序列化机制是 JavaEE 平台的基础。
- 如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一。否则,会抛出 NotSerializableException 异常。
- Externalizable
- 凡是实现 Serializable 接口的类都有一个表示序列化版本标识符的静态变量:
- serialVersionUID 用来表明类的不同版本间的兼容性。 简言之,其目的是以序列化对象进行版本控制,有关各版本反序列化时是否兼容。
- 如果类没有显示定义这个静态常量,它的值是 Java 运行时环境根据类的内部细节自动生成的。此时,若类的实例变量做了修改,serialVersionUID 可能发生变化,则再对修改之前被序列化的类进行反序列化操作时,会操作失败。因此,建议显式声明 serialVersionUID。
- 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的 serialVersionUID;在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的 serialVersionUID。
- 当序列化了一个类实例后,后续可能更改一个字段或添加一个字段。如果不设置 serialVersionUID,所做的任何更改都将导致无法反序化旧有实例,并在反序列化时抛出一个异常;如果你添加了 serialVersionUID,在反序列旧有实例时,新添加或更改的字段值将设为初始化值(对象为 null,基本类型为相应的初始默认值),字段被删除将不设置。
简单来说,Java 的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即 InvalidCastException。
若某个类实现了 Serializable 接口,该类的对象就是可序列化的:
- 创建一个 ObjectOutputStream。
- : 创建一个指定 OutputStream 的 ObjectOutputStream。
- 调用 ObjectOutputStream 对象的输出可序列化对象。
- 注意写出一次,操作一次。
反序列化:
- 创建一个 ObjectInputStream。
- : 创建一个指定 InputStream 的 ObjectInputStream。
- 调用读取流中的对象。
强调:如果某个类的属性不是基本数据类型或 String 类型,而是另一个引用类型,那么这个引用类型必须是可序列化的,否则拥有该类型的 Field 的类也不能序列化。
- 默认情况下,基本数据类型是可序列化的。String 实现了 Serializable 接口。
流程示意图:

示例:
面试题:谈谈你对接口的理解,我们知道它用于序列化,是空方法接口,还有其它认识吗?
- 实现了 Serializable 接口的对象,可将它们转换成一系列字节,并可在以后完全恢复回原来的样子。 这一过程亦可通过网络进行。这意味着序列化机制能自动补偿操作系统间的差异。换句话说,可以先在 Windows 机器上创建一个对象,对其序列化,然后通过网络发给一台 Unix 机器,然后在那里准确无误地重新 "装配"。不必关心数据在不同机器上如何表示,也不必关心字节的顺序或者其他任何细节。
- 由于大部分作为参数的类如 String 、Integer 等都实现了接口,也可以利用多态的性质,作为参数使接口更灵活。
随机存取文件流
声明在包下,但直接继承于类。并且它实现了 DataInput、DataOutput 这两个接口,也就意味着这个类既可以读也可以写。
RandomAccessFile 类支持的方式,程序可以直接跳到文件的任意地方来读、写文件。
- 支持只访问文件的部分内容。
- 可以向已存在的文件后追加内容。
RandomAccessFile 对象包含一个,用以标示当前读写处的位置。RandomAccessFile 类对象可以自由移动记录指针:
- :获取文件记录指针的当前位置。
- :将文件记录指针定位到 pos 位置。
构造器:
创建 RandomAccessFile 类实例需要指定一个 mode 参数,该参数指定 RandomAccessFile 的访问模式:
- r:以只读方式打开。
- rw:打开以便读取和写入。
- rwd:打开以便读取和写入;同步文件内容的更新。
- rws:打开以便读取和写入;同步文件内容和元数据的更新。
- JDK 1.6 上面写的每次 write 数据时,rw 模式,数据不会立即写到硬盘中,而 rwd 模式,数据会被立即写入硬盘。如果写数据过程发生异常,rwd 模式中已被 write 的数据会被保存到硬盘,而 rw 模式的数据会全部丢失。
- 如果模式为只读 r,则不会创建文件,而是会去读取一个已经存在的文件,如果读取的文件不存在则会出现异常。 如果模式为读写 rw,如果文件不存在则会去创建文件,如果存在则不会创建。
RandomAccessFile 的应用:我们可以用 RandomAccessFile 这个类,来实现一个多线程断点下载的功能,用过下载工具的朋友们都知道,下载前都会建立两个临时文件,一个是与被下载文件大小相同的空文件,另一个是记录文件指针的位置文件,每次暂停的时候,都会保存上一次的指针,然后断点下载的时候,会继续从上一次的地方下载,从而实现断点下载或上传的功能,有兴趣的朋友们可以自己实现下。
示例:
I/O 流的关闭
一个流绑定了一个文件句柄(或网络端口),如果流不关闭,该文件(或端口)将始终处于被锁定(不能读取、写入、删除和重命名)状态,导致占用大量系统资源却没有释放,因此,必须要关闭流。
同时,在程序中打开的文件 I/O 资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以,需要显式关闭文件 I/O 资源。
try-catch-finally
语法格式:
- 流一定要在 finally 语句中关闭,防止出现异常,导致无法关闭。
- 流关闭时,需要注意关闭的顺序,先声明的流后关闭。
try-catch-resources
:是 Java 7 中引入的一种异常处理机制,用于自动关闭实现了接口(在 Java 7 中)或接口(在 Java 7 之前就存在,AutoCloseable 是 Closeable 的子接口)的资源。这些资源通常包括文件流(如 FileInputStream、FileOutputStream)、数据库连接(如 Connection)、网络连接等。
传统的资源管理在异常处理时可能会比较复杂,需要在 finally 块中手动关闭资源,以确保资源被正确释放,防止资源泄漏。而 try-catch-resources 简化了这个过程,它能够自动关闭资源,即使在 try 块中发生了异常。
语法格式:
原文链接
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/20535.html