

世界上只有两种物质:高效率和低效率;世界上只有两种人:高效率的人和低效率的人。——萧伯纳
同理,世界上只有两种代码:高效代码和低效代码;世界上只有两种人:编写高效代码的人和编写低效代码的人。如何编写高效代码,是每个研发团队都面临的一个重大问题。所以,作者根据实际经验,查阅了大量资料,总结了"Java高效代码50例",让每一个Java程序员都能编写出"高效代码"。
1.常量&变量
1.1.直接赋值常量值,禁止声明新对象
直接赋值常量值,只是创建了一个对象引用,而这个对象引用指向常量值。
反例:

正例:

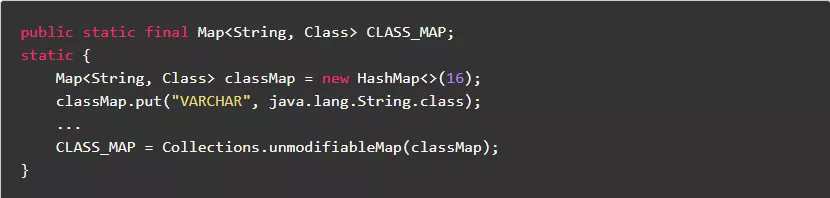
1.2.当成员变量值无需改变时,尽量定义为静态常量
在类的每个对象实例中,每个成员变量都有一份副本,而成员静态常量只有一份实例。
反例:

正例:

1.3.尽量使用基本数据类型,避免自动装箱和拆箱
Java 中的基本数据类型double、float、long、int、short、char、boolean,分别对应包装类Double、Float、Long、Integer、Short、Character、Boolean。
JVM支持基本类型与对应包装类的自动转换,被称为自动装箱和拆箱。装箱和拆箱都是需要CPU和内存资源的,所以应尽量避免使用自动装箱和拆箱。
反例:

正例:

1.4.如果变量的初值会被覆盖,就没有必要给变量赋初值
反例:
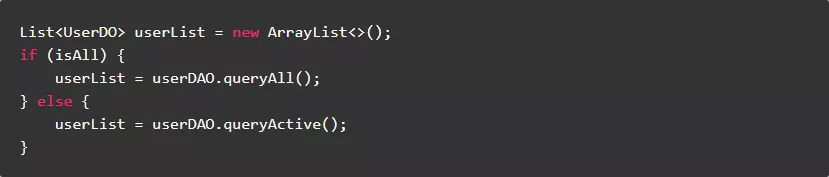
正例:
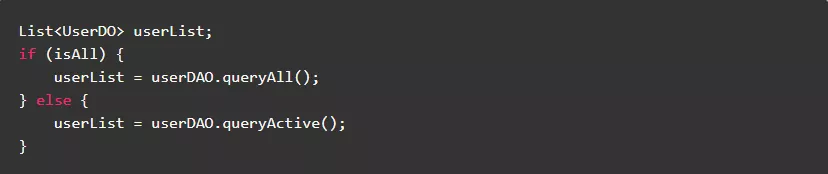
1.5.尽量使用函数内的基本类型临时变量
在函数内,基本类型的参数和临时变量都保存在栈(Stack)中,访问速度较快;对象类型的参数和临时变量的引用都保存在栈(Stack)中,内容都保存在堆(Heap)中,访问速度较慢。在类中,任何类型的成员变量都保存在堆(Heap)中,访问速度较慢。
反例:
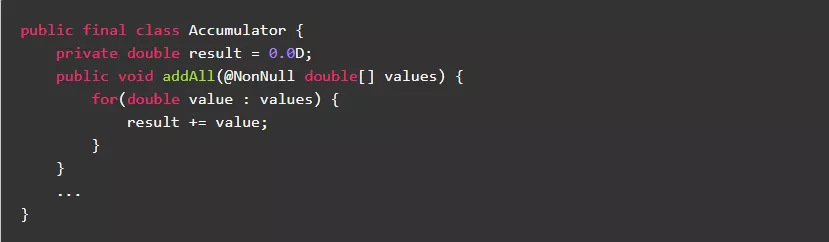
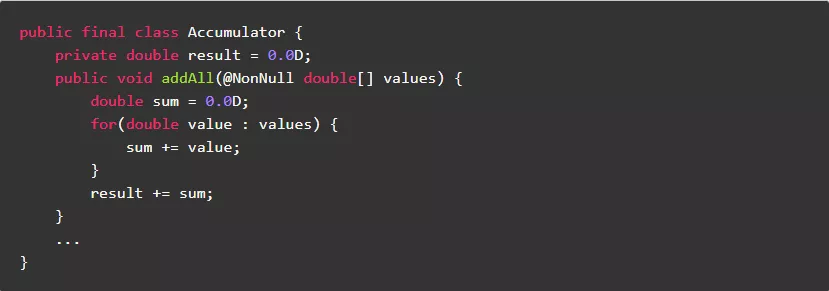
1.6.尽量不要在循环体外定义变量
在老版JDK中,建议“尽量不要在循环体内定义变量”,但是在新版的JDK中已经做了优化。通过对编译后的字节码分析,变量定义在循环体外和循环体内没有本质的区别,运行效率基本上是一样的。反而,根据“ 局部变量作用域最小化 ”原则,变量定义在循环体内更科学更便于维护,避免了延长大对象生命周期导致延缓回收问题 。
反例:
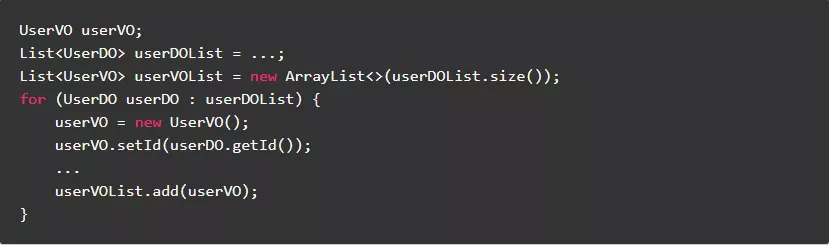
正例:
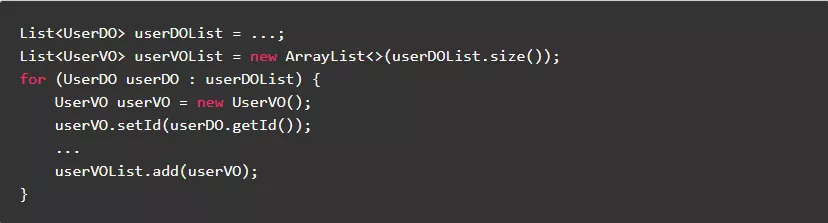
1.7.不可变的静态常量,尽量使用非线程安全类
不可变的静态常量,虽然需要支持多线程访问,也可以使用非线程安全类。
反例:
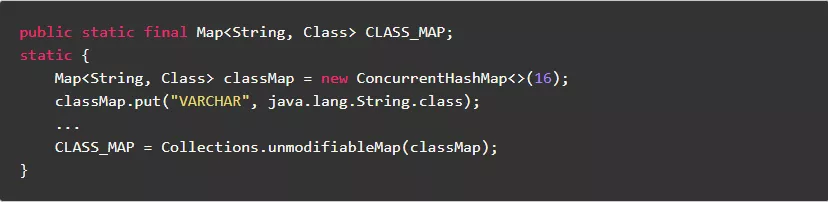
正例:
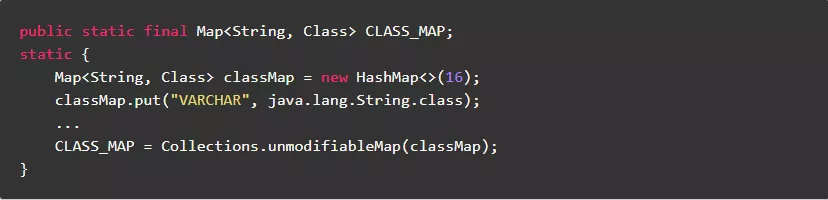
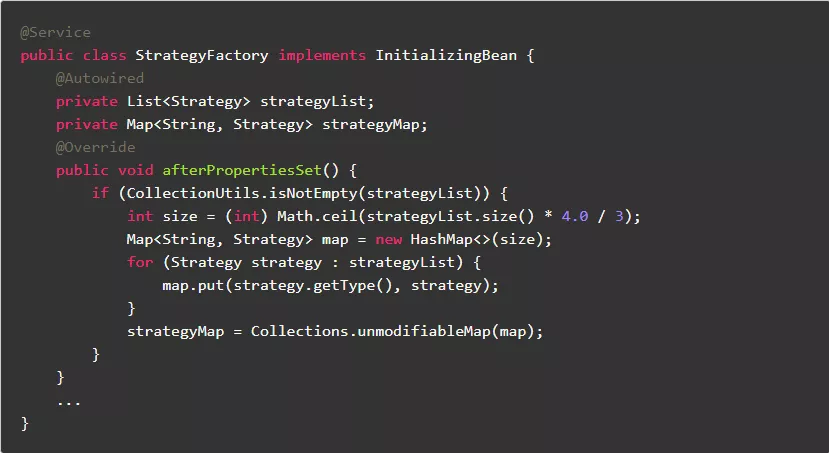
1.8.不可变的成员变量,尽量使用非线程安全类
不可变的成员变量,虽然需要支持多线程访问,也可以使用非线程安全类。
反例:
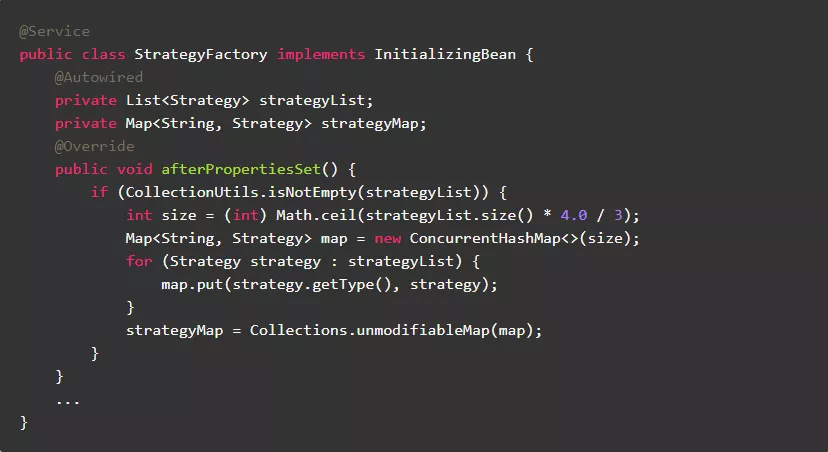
正例:
2.对象&类
2.1.禁止使用JSON转化对象
JSON提供把对象转化为JSON字符串、把JSON字符串转为对象的功能,于是被某些人用来转化对象。这种对象转化方式,虽然在功能上没有问题,但是在性能上却存在问题。
反例:

正例:
java基础进制优化
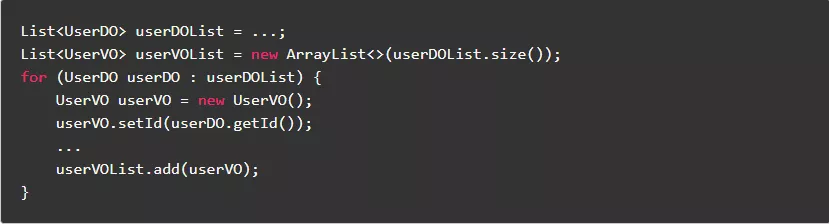
2.2.尽量不使用反射赋值对象
用反射赋值对象,主要优点是节省了代码量,主要缺点却是性能有所下降。
反例:
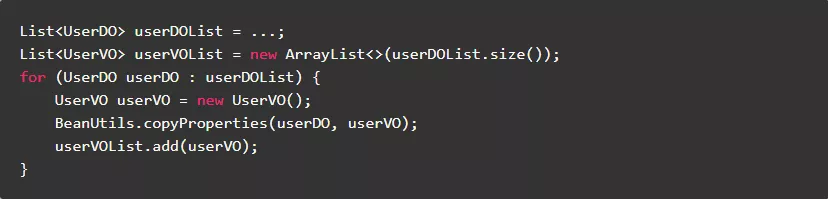
正例:
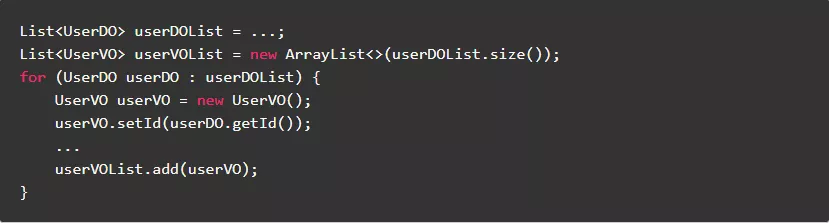
2.3.采用Lambda表达式替换内部匿名类
对于大多数刚接触JDK8的同学来说,都会认为Lambda表达式就是匿名内部类的语法糖。实际上, Lambda表达式在大多数虚拟机中采用invokeDynamic指令实现,相对于匿名内部类在效率上会更高一些。
反例:
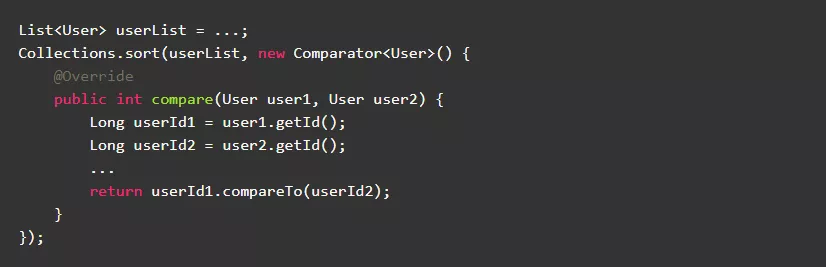
正例:
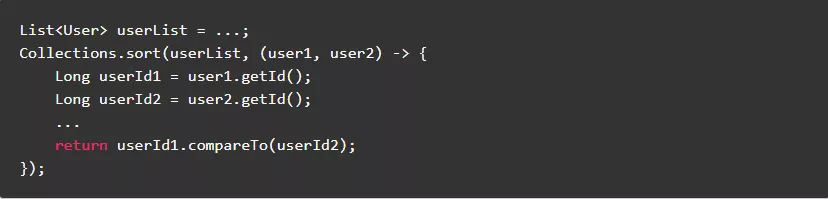
2.4.尽量避免定义不必要的子类
多一个类就需要多一份类加载,所以尽量避免定义不必要的子类。
反例:
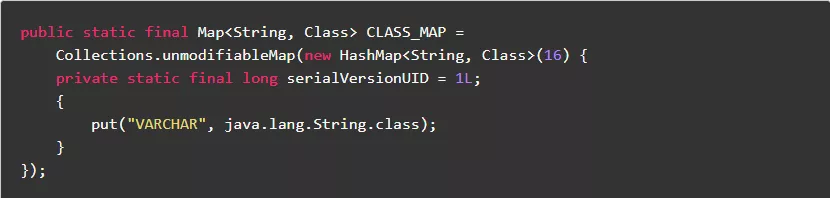
正例:
2.5.尽量指定类的final修饰符
为类指定final修饰符,可以让该类不可以被继承。如果指定了一个类为final,则该类所有的方法都是final的,Java编译器会寻找机会内联所有的final方法。内联对于提升Java运行效率作用重大,具体可参见Java运行期优化,能够使性能平均提高50%。
反例:

正例:

3.方法
3.1.把跟类成员变量无关的方法声明成静态方法
静态方法的好处就是不用生成类的实例就可以直接调用。静态方法不再属于某个对象,而是属于它所在的类。只需要通过其类名就可以访问,不需要再消耗资源去反复创建对象。即便在类内部的私有方法,如果没有使用到类成员变量,也应该声明为静态方法。
反例:

正例:

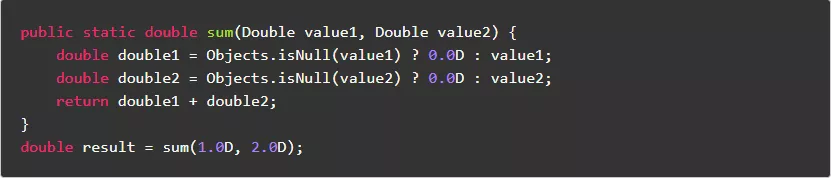
3.2.尽量使用基本数据类型作为方法参数类型,避免不必要的装箱、拆箱和空指针判断
反例:
正例:

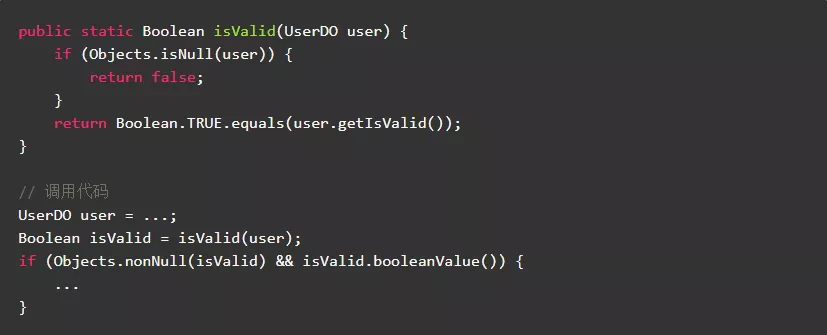
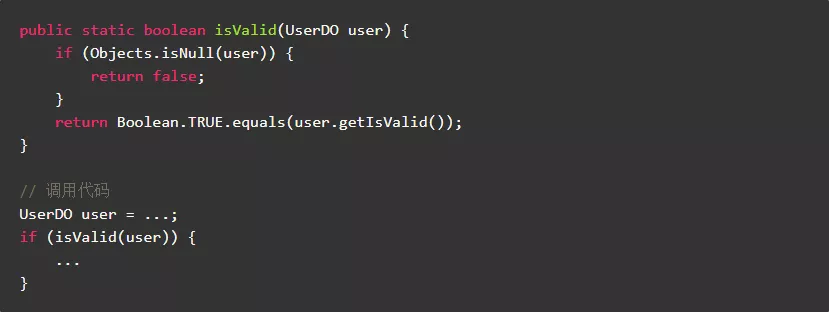
3.3.尽量使用基本数据类型作为方法返回值类型,避免不必要的装箱、拆箱和空指针判断
在JDK类库的方法中,很多方法返回值都采用了基本数据类型,首先是为了避免不必要的装箱和拆箱,其次是为了避免返回值的空指针判断。比如:
- Collection.isEmpty()
- Map.size()。
反例:
正例:
3.4.协议方法参数值非空,避免不必要的空指针判断
协议编程,可以@NonNull和@Nullable标注参数,是否遵循全凭调用者自觉。
反例:
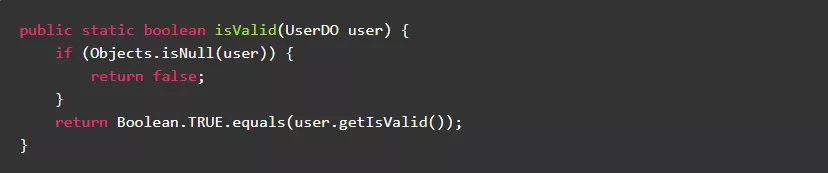
正例:

3.5.协议方法返回值非空,避免不必要的空指针判断
协议编程,可以@NonNull和@Nullable标注参数,是否遵循全凭实现者自觉。
反例:
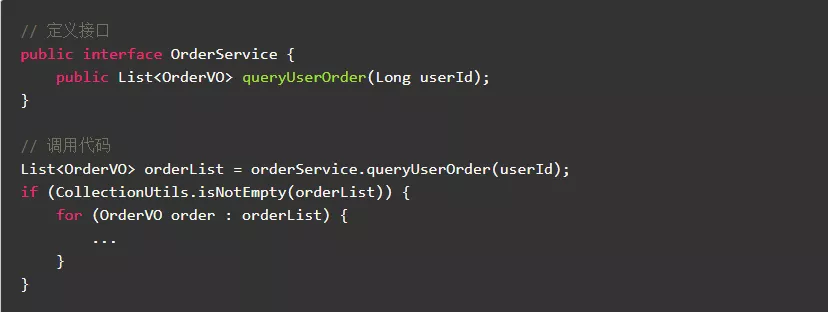
正例:
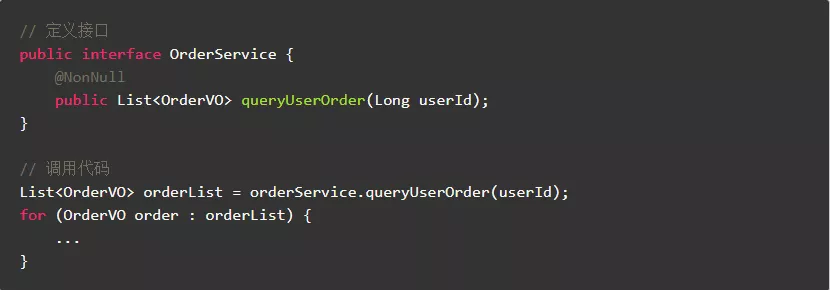
3.6.被调用方法已支持判空处理,调用方法无需再进行判空处理
反例:

正例:

3.7.尽量避免不必要的函数封装
方法调用会引起入栈和出栈,导致消耗更多的CPU和内存,应当尽量避免不必要的函数封装。当然,为了使代码更简洁、更清晰、更易维护,增加一定的方法调用所带来的性能损耗是值得的。
反例:
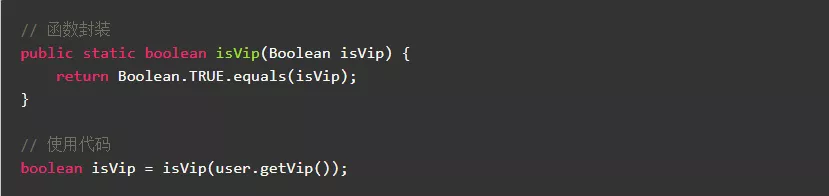
正例:

3.8.尽量指定方法的final修饰符
方法指定final修饰符,可以让方法不可以被重写,Java编译器会寻找机会内联所有的final方法。内联对于提升Java运行效率作用重大,具体可参见Java运行期优化,能够使性能平均提高50%。
注意:所有的private方法会隐式地被指定final修饰符,所以无须再为其指定final修饰符。
反例:

正例:

注意:使用Spring的AOP特性时,需要对Bean进行动态代理,如果方法添加了final修饰,将不会被代理。
4.表达式
4.1.尽量减少方法的重复调用
反例:

正例:

4.2.尽量避免不必要的方法调用
反例:

正例:
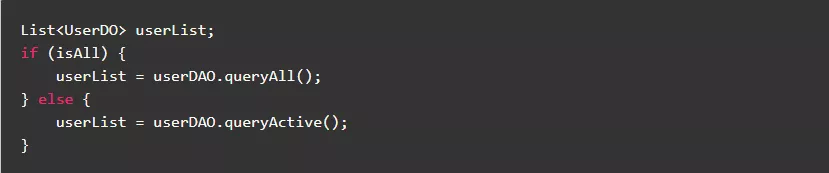
4.3.尽量使用移位来代替正整数乘除
用移位操作可以极大地提高性能。对于乘除2^n(n为正整数)的正整数计算,可以用移位操作来代替。
反例:

正例:

4.4.提取公共表达式,避免重复计算
提取公共表达式,只计算一次值,然后重复利用值。
反例:
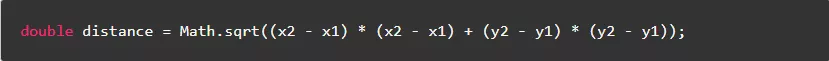
正例:

4.5.尽量不在条件表达式中用!取反
使用!取反会多一次计算,如果没有必要则优化掉。
反例:

正例:

4.6.对于多常量选择分支,尽量使用switch语句而不是if-else语句
if-else语句,每个if条件语句都要加装计算,直到if条件语句为true为止。switch语句进行了跳转优化,Java中采用tableswitch或lookupswitch指令实现,对于多常量选择分支处理效率更高。
经过试验证明:在每个分支出现概率相同的情况下,低于5个分支时if-else语句效率更高,高于5个分支时switch语句效率更高。
反例:

正例:

备注:如果业务复杂,可以采用Map实现策略模式。
5.字符串
5.1.尽量不要使用正则表达式匹配
正则表达式匹配效率较低,尽量使用字符串匹配操作。
反例:

正例:

5.2.尽量使用字符替换字符串
字符串的长度不确定,而字符的长度固定为1,查找和匹配的效率自然提高了。
反例:

正例:

5.3.尽量使用StringBuilder进行字符串拼接
String是final类,内容不可修改,所以每次字符串拼接都会生成一个新对象。
StringBuilder在初始化时申请了一块内存,以后的字符串拼接都在这块内存中执行,不会申请新内存和生成新对象。
反例:

正例:
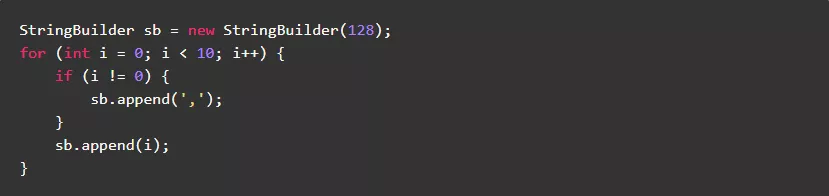
5.4.不要使用""+转化字符串
使用""+进行字符串转化,使用方便但是效率低,建议使用String.valueOf.
反例:

正例:

6.数组
6.1.不要使用循环拷贝数组,尽量使用System.arraycopy拷贝数组
推荐使用System.arraycopy拷贝数组,也可以使用Arrays.copyOf拷贝数组。
反例:

正例:

6.2.集合转化为类型T数组时,尽量传入空数组T[0]
将集合转换为数组有2种形式:toArray(new T[n])和toArray(new T[0])。在旧的Java版本中,建议使用toArray(new T[n]),因为创建数组时所需的反射调用非常慢。在OpenJDK6后,反射调用是内在的,使得性能得以提高,toArray(new T[0])比toArray(new T[n])效率更高。
此外,toArray(new T[n])比toArray(new T[0])多获取一次列表大小,如果计算列表大小耗时过长,也会导致toArray(new T[n])效率降低。
反例:

正例:

6.3.集合转化为Object数组时,尽量使用toArray()方法
转化Object数组时,没有必要使用toArray[new Object[0]],可以直接使用toArray()。避免了类型的判断,也避免了空数组的申请,所以效率会更高。
反例:

正例:

7.集合
7.1.初始化集合时,尽量指定集合大小
Java集合初始化时都会指定一个默认大小,当默认大小不再满足数据需求时就会扩容,每次扩容的时间复杂度有可能是O(n)。所以,尽量指定预知的集合大小,就能避免或减少集合的扩容次数。
反例:
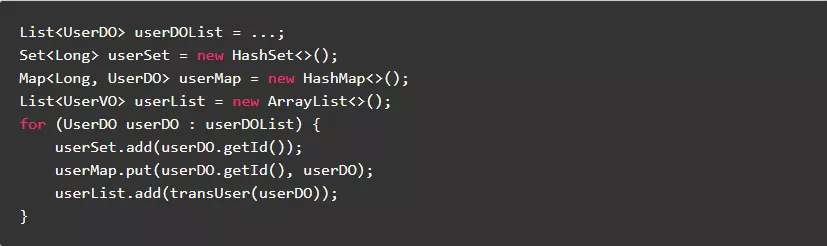
正例:
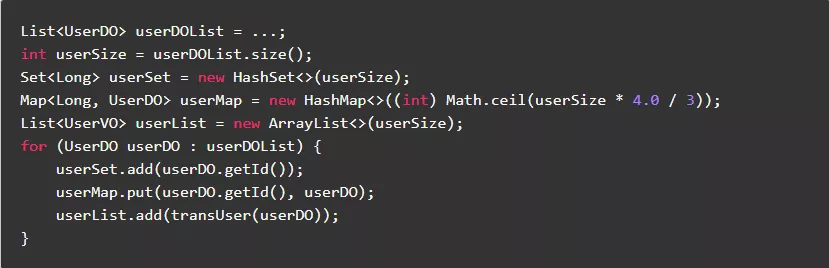
7.2.不要使用循环拷贝集合,尽量使用JDK提供的方法拷贝集合
JDK提供的方法可以一步指定集合的容量,避免多次扩容浪费时间和空间。同时,这些方法的底层也是调用System.arraycopy方法实现,进行数据的批量拷贝效率更高。
反例:
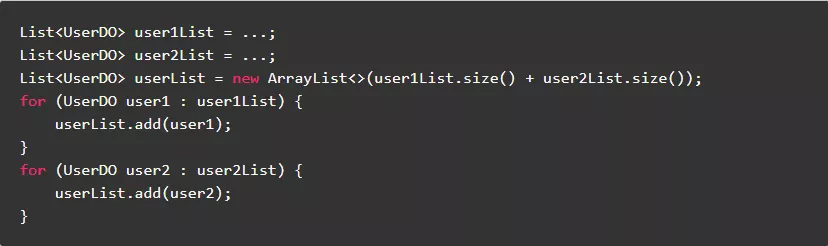
正例:

7.3.尽量使用Arrays.asList转化数组为列表
原理与"不要使用循环拷贝集合,尽量使用JDK提供的方法拷贝集合"类似。
反例:
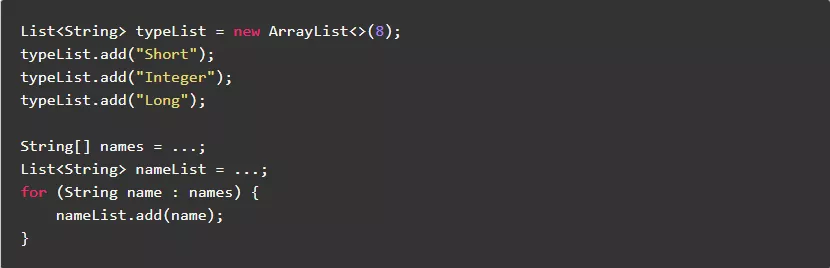
正例:

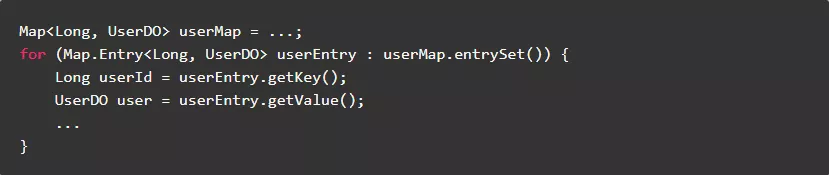
7.4.直接迭代需要使用的集合
直接迭代需要使用的集合,无需通过其它操作获取数据。
反例:

正例:
7.5.不要使用size方法检测空,必须使用isEmpty方法检测空
使用size方法来检测空逻辑上没有问题,但使用isEmpty方法使得代码更易读,并且可以获得更好的性能。任何isEmpty方法实现的时间复杂度都是O(1),但是某些size方法实现的时间复杂度有可能是O(n)。
反例:

正例:

7.6.非随机访问的List,尽量使用迭代代替随机访问
对于列表,可分为随机访问和非随机访问两类,可以用是否实现RandomAccess接口判断。随机访问列表,直接通过get获取数据不影响效率。而非随机访问列表,通过get获取数据效率极低。
反例:
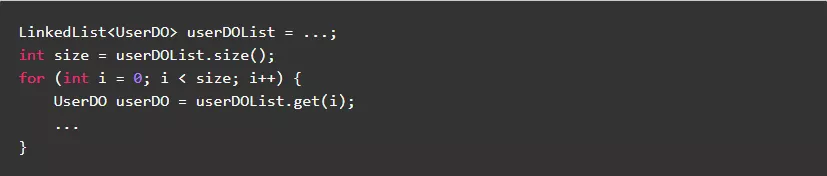
正例:

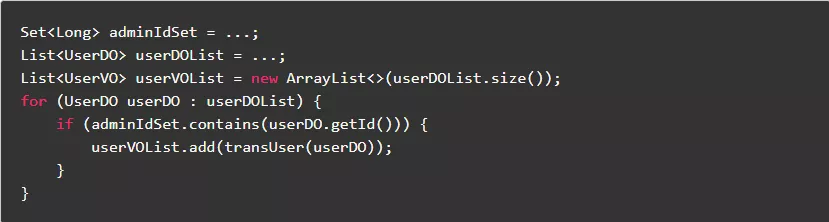
7.7.尽量使用HashSet判断值存在
在Java集合类库中,List的contains方法普遍时间复杂度是O(n),而HashSet的时间复杂度为O(1)。如果需要频繁调用contains方法查找数据,可以先将List转换成HashSet。
反例:
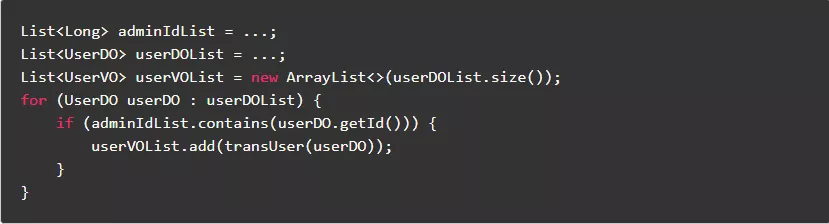
正例:
7.8.避免先判断存在再进行获取
如果需要先判断存在再进行获取,可以直接获取并判断空,从而避免了二次查找操作。
反例:
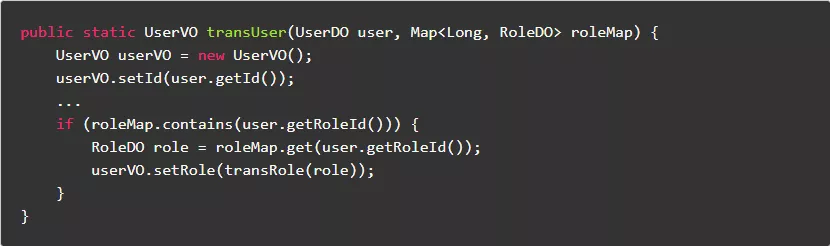
正例:
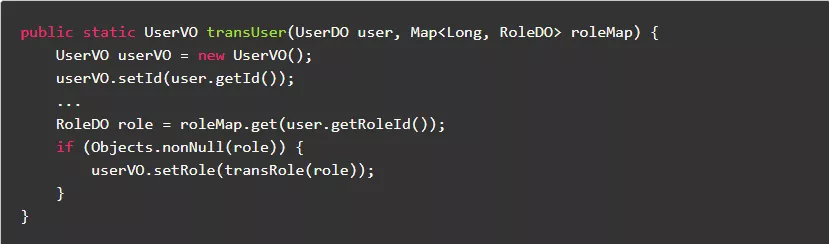
8.异常
8.1.直接捕获对应的异常
直接捕获对应的异常,避免用instanceof判断,效率更高代码更简洁。
反例:
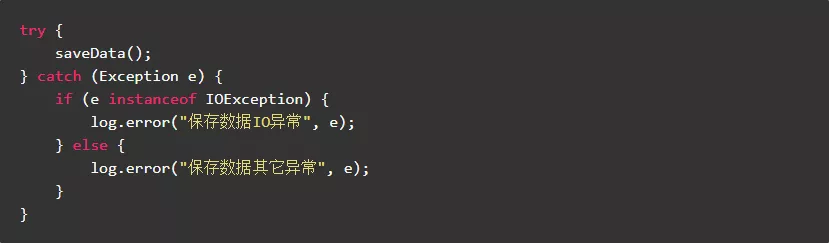
正例:
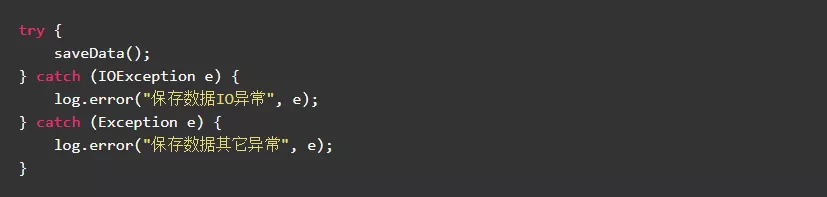
8.2.尽量避免在循环中捕获异常
当循环体抛出异常后,无需循环继续执行时,没有必要在循环体中捕获异常。因为,过多的捕获异常会降低程序执行效率。
反例:
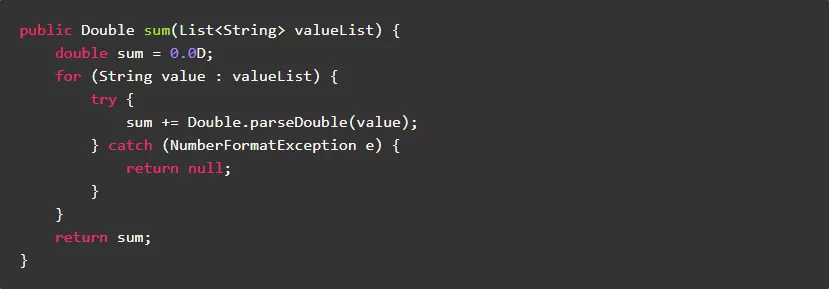
正例:
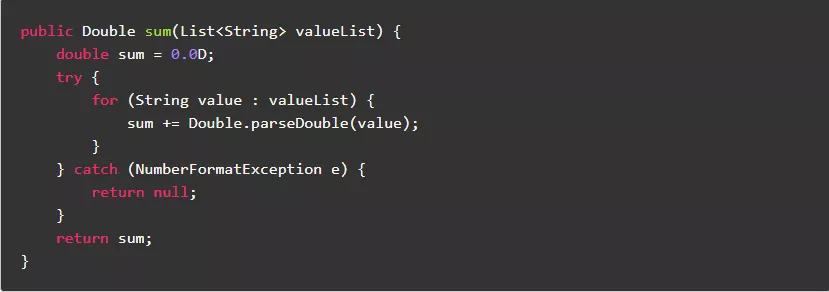
8.3.禁止使用异常控制业务流程
相对于条件表达式,异常的处理效率更低。
反例:
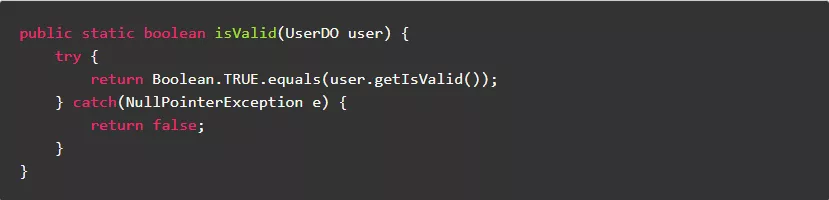
正例:
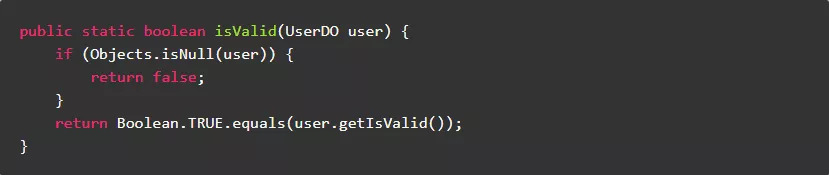
9.缓冲区
9.1.初始化时尽量指定缓冲区大小
初始化时,指定缓冲区的预期容量大小,避免多次扩容浪费时间和空间。
反例:

正例:

9.2.尽量重复使用同一缓冲区
针对缓冲区,Java虚拟机需要花时间生成对象,还要花时间进行垃圾回收处理。所以,尽量重复利用缓冲区。
反例:

正例:

9.3.尽量设计使用同一缓冲区
为了提高程序运行效率,在设计上尽量使用同一缓冲区。
反例:
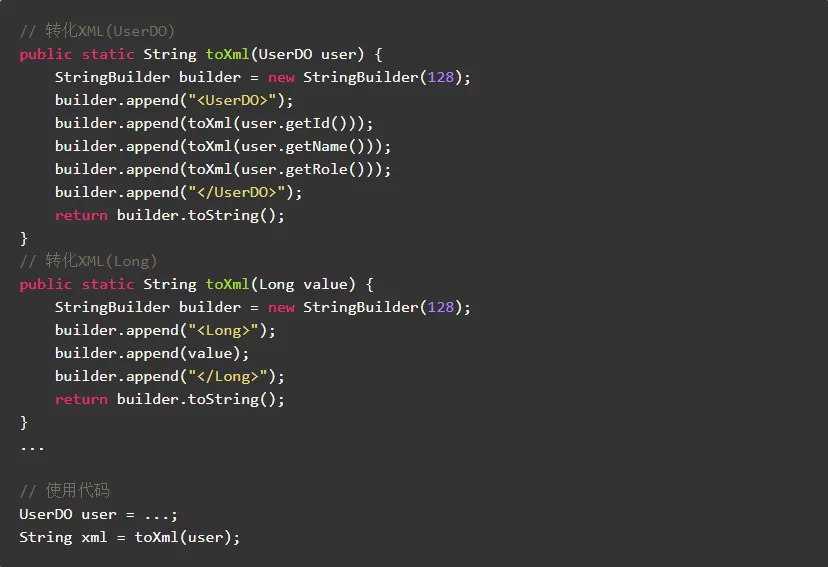
正例:
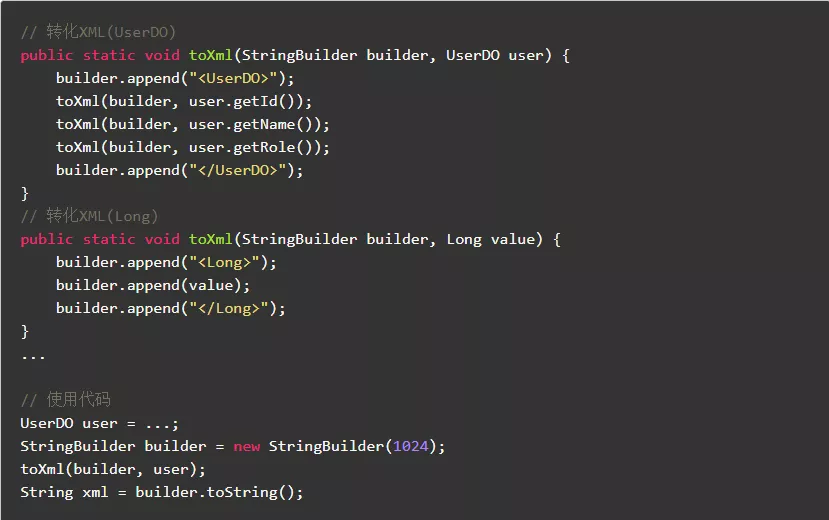
9.4.尽量使用缓冲流减少IO操作
使用缓冲流:
- BufferedReader
- BufferedWriter
- BufferedInputStream
- BufferedOutputStream
- ...
可以大幅减少IO次数并提升IO速度。
反例:
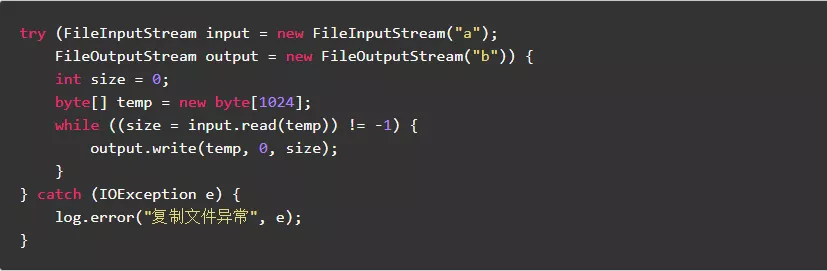
正例:
后记
作为一名长期奋战在业务一线的"IT民工",没有机会去研究什么高深莫测的"理论",只能专注于眼前看得见摸得着的"技术",致力于做到"干一行、爱一行、专一行、精一行"。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/24834.html