
一、配置虚拟机网络(NAT 模式)
宿主机ipconfig截图:
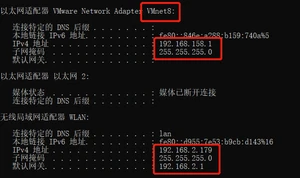
Vmnet8网络配置:
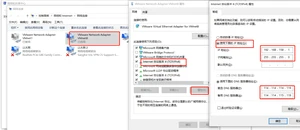
虚拟机网络配置:
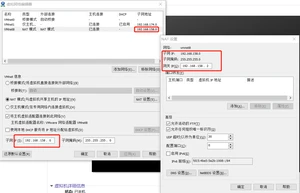
二、配置一个单节点环境
2.1 上传文件到CentOS并配置Java和Hadoop环境
上传安装包到服务器:
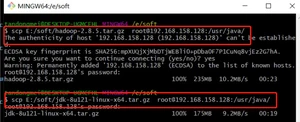
上传成功后,看到两个压缩包:

解压两个压缩包:

给文件重新命名,方便之后配置环境变量:

配置jdk+hadoop环境变量:
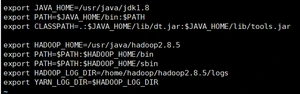
查看jdk环境变量是否配置成功:

查看hadoop环境变量是否配置成功:

至此jdk和hadoop已经安装好,接下来修改一些配置文件
2.2 修改CentOS主机名
默认主机名:
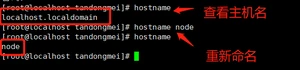
查看和修改主机名:
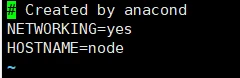
永久修改主机名,修改配置文件执行命令: vi /etc/sysconfig/network:
2.3 绑定hostname与IP
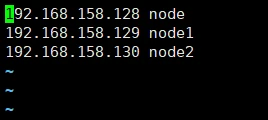
绑定hostname和ip, 执行命令:vi /etc/hosts
2.4 关闭防火墙

2.5 Hadoop目录结构
1、查看Hadoop目录结构,执行命令:ll
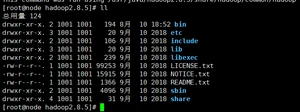
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
三、Hadoop三种运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
模式一:本地运行模式
官方Grep案例

2. 将Hadoop的xml配置文件复制到input
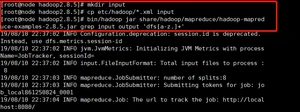
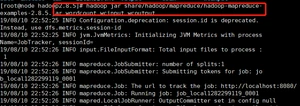
3. 执行share目录下的MapReduce程序
4. 查看输出结果
控制台结果展示:

官方WordCount案例
1. 创建在hadoop2.8.5文件下面创建一个wcinput文件夹
2. 在wcinput文件下创建一个wc.input文件
3. 编辑wc.input文件
在文件中输入如下内容
hadoop
hadoop
mapreduce
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop2.8.5
5. 执行程序
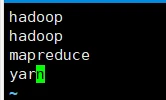
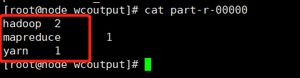
6. 查看结果
hadoop 2
mapreduce 1
yarn 1
案例结果展示:
模式二:伪分布式运行模式
启动HDFS并运行MapReduce程序
1. 配置集群
(1)配置:hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8/
(2)配置:core-site.xml
(3)配置:hdfs-site.xml
2. 启动集群
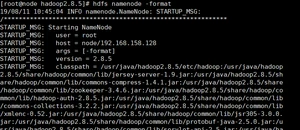
(1)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
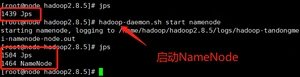
(2)启动NameNode
(3)启动DataNode
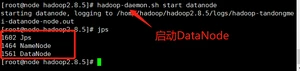
3. 查看集群
(1)查看是否启动成功, 执行命令jps
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
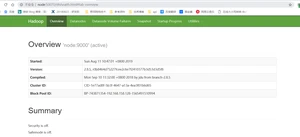
(2)web端查看HDFS文件系统
http://node:50070
注意:在Windows环境通过URL访问,需要在C:WindowsSystem32driversetchosts,在其中添加192.168.158.128 node即可。
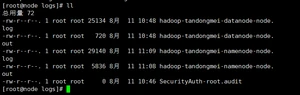
(3)查看产生的Log日志

本地查看日志:
web端查看日志:
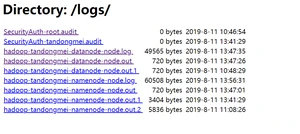
(4)思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
clusterID=clusterID=CID-1e77ad8f-5b3f-4647-a13a-4ea3f01b6d65
clusterID=clusterID=CID-1e77ad8f-5b3f-4647-a13a-4ea3f01b6d65
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
4. 操作集群
(1)在HDFS文件系统上创建一个input文件夹
执行命令: hdfs dfs -mkdir -p /usr/java/hadoop/input


(2)将本地测试文件内容上传到文件系统上
执行命令:hdfs dfs -put wcinput/wc.input /user/java/hadoop/input/


(3)查看上传的文件是否正确
执行命令:hdfs dfs -cat /usr/java/hadoop/input/wc.input

(4)运行MapReduce程序
执行命令:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /usr/java/hadoop/input/ /usr/java/hadoop/output

(5)查看输出结果
执行命令:hdfs dfs -cat /usr/java/hadoop/output/*



(6)将测试文件内容下载到本地
执行命令:hdfs dfs -get /usr/java/hadoop/output/part-r-00000 wcoutput/

(7)删除输出结果
执行命令:hdfs dfs -rm -f /usr/java/hadoop/output

启动YARN并运行MapReduce程序
1. 配置集群
(1)配置yarn-env.sh

(2)配置yarn-site.xml
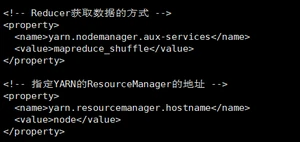
(3)配置:mapred-env.sh
(4)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
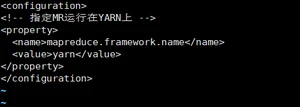
2. 启动集群
(1)启动前必须保证NameNode和DataNode已经启动
(2)启动ResourceManager
执行命令:yarn-daemon.sh start resourcemanager
(3)启动NodeManager
执行命令:yarn-daemon.sh start nodemanager
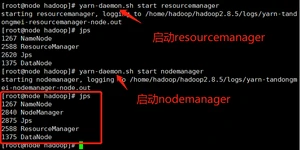
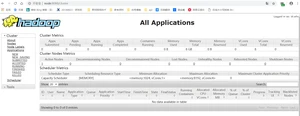
3. 集群操作
(1)YARN的浏览器页面查看,如图2-35所示
http://node:8088/cluster
(2)删除文件系统上的output文件
执行命令:hdfs dfs -rm -f /usr/java/hadoop/output
(3)执行MapReduce程序
(4)查看运行结果

模式三:完全分布式运行模式
1. 克隆虚拟机
2. 修改配置文件
(1)vi /etc/sysconfig/network-scripts/ifcfg-ens33
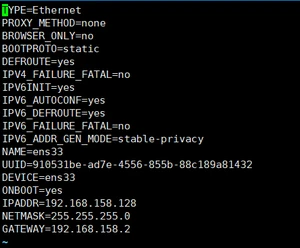
(2) vi /etc/sysconfig/network
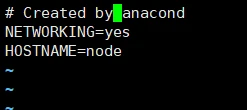
(3) vi /etc/hosts
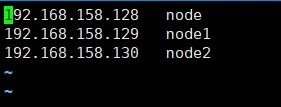
3. 集群部署规划
node
node1node2
HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
NodeManager
ResourceManager
NodeManager
NodeManager
4. 配置集群
(1)配置core-site.xml
java hadoop基础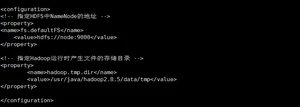
(2)HDFS配置文件
- 配置hadoop-env.sh
- 配置hdfs-site.xml
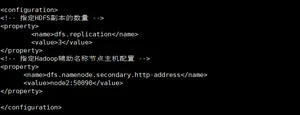
- 配置yarn-env.sh
- 配置yarn-site.xml
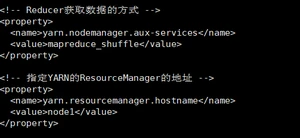
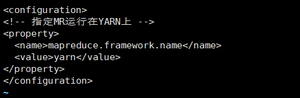
(4)MapReduce配置文件
- 配置mapred-env.sh
- 配置mapred-site.xml
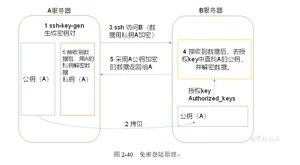
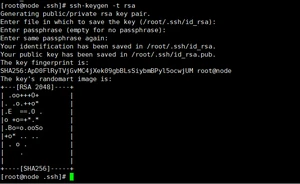
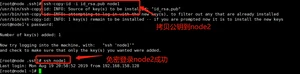
5. 节点之间免密通信: ssh配置免密登录


6. 群起集群
启动HDFS:start-dfs.sh

启动yarn: start-yarn.sh

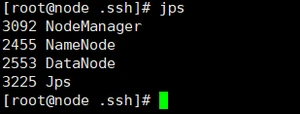
[node] jps
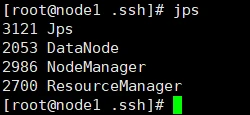
[node1] jps
[node2] jps
集群命令:
启动/停止HDFS
start-dfs.sh / stop-dfs.sh
启动/停止YARN
start-yarn.sh / stop-yarn.sh
全部启动/全部停止
start-all.sh / stop-all.sh
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/24854.html