
以下是我个人总结的复习资料,有些只是小点,若看不懂可自行按需拓展
spark:开源的大数据处理框架
spark模块
Spark Core :spark基础,提供基本的I/O功能,任务调度,内存管理,支持创建弹性分布式数据集,是所有高级API的基础,离线批处理,底层处理单位:RDD
Spark SQL :处理结构化与半结构化数据,支持多种数据源并提供SQL接口和DataFrame API进行数据查询,做sql高级查询,底层处理单位:DataFrame(新版本为DataSet:它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点)
Spark Streaming:用于处理实时数据,将实时数据分成小批量,底层处理单位:DStream
MLlib:机器学习
GraphX:图处理库
判断何时使用dataFrame和dataSet
● 数据类型和数据的结构:对于结构化和半结构化数据,DataFrame通常是更好的选择。对于非结构化数据,Dataset可能更合适。
● 编程模型:DataFrame API更像SQL编程,Dataset API更像传统的类型安全的编程(如Java或Scala)。
● 性能:两者在性能上都有优化,但在需要更具体、更复杂的计算时,Dataset可能会更有优势。
● 类型安全:如果你需要编译时类型检查,以避免运行时错误,那么应该选择Dataset。
spark 组成
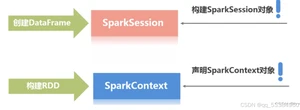
● driver (JVM进程 ): 执行main方法 创建spark context/session
● spark context/session : 程序集**互入口
● Cluster Manager :部署spark集群
● Executor :集群中工作节点(worker)中的JVM进程,执行spark任务返回给driver (内含多个task 可并发执行)
应用程序相关参数 :
spark的部署模式
本地模式(单机运行,所有组件都在同一机器上)
独立集群模式(自带的集群管理器,部署在一组机器上,一台master,其他worker)
yarn模式(在hadoop yarn上运行)
RDD特性(弹性分布式数据集 spark提供的编程模型):
● RDD是由一系列分区组成的
● Task是作用在每个分区上的,每个分区至少需要一个Task
● RDD之间是有一系列依赖关系的,可以按有无Shuflle分为:宽依赖(groupBy)、窄依赖 (一一对应 :map)
● 分区器是作用在KV格式的RDD上的
● Spark为每个Task尽可能的提供**计算位置 ,移动计算,不移动数据
RDD的创建:
● 从内存(集合)中:makeRDD、parallelize
● 从外部存储文件中:textFile
● 从其他RDD中创建
● 直接创建:new
算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行
Spark算子
转换算子(map、flatMap、filter、groupByKey、reduceByKey、join)/行动算子(foreach、count、take、collect、reduce)
spark与mapreduce
spark基于内存,可动态分配资源,容错机制,有向无环图(优化流程)
广播变量&累加器
广播变量:
减少网络中传输的数据量,提升运行效率
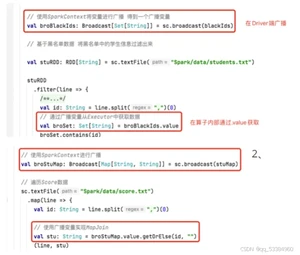
累加器:异常监控/累计
Spark任务主要有5个数据本地化级别:
PROCESS_LOCAL进程本地化
NODE_LOCAL节点本地化
NO_PREF无**位置
RACK_LOCAL机架本地化
ANY跨机架调用
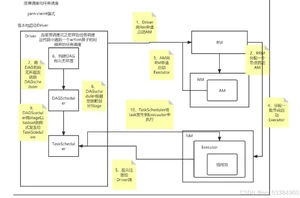
spark执行任务
- 资源申请(部署模式 ON YARN=> client 测试 cluster实操)
cluster与client的区别:
cluster的driver是在yarn上启动,分配资源
client的driver是在本地启动,联系yran分配资源
- 任务调度
算子
coalesce
map与flatmap的区别
使用 map 当每个输入元素仅产生一个输出元素时,例如对每个数进行平方计算。
使用 flatMap 当每个输入元素可能产生多个输出元素时,例如对每行文本进行单词拆分
map与mappartitions的区别
map每次处理一个元素
mappartitions提供迭代器,一次处理一个分区
fun _ 是将方法转换为函数值的语法,允许将方法作为函数使用
stage的划分有两种:shuffle map stage (过程中)和result stage(结尾)
spark内存管理:使用内存管理模型,执行内存与存储内存动态共享,内存溢写,内存分配,序列化
存储级别:
MEMORY_ONLY 只在内存中
DISK_ONLY 只在磁盘
MEMORY_AND_DISK 先内存不够在磁盘
MEMORY_ONLY _2 只在内存,存储两份副本
MEMORY_AND_DISK _2 先内存不够在磁盘,存储两份副本
DISK_ONLY _2 只在磁盘,存储两份副本
MEMORY_ONLY_SER 存在内存中,并序列化
…等等
spark的容错机制:
RDD:血统:每个RDD都会保留其血统信息,即从原始数据到当前RDD的所有转换步骤,这使得即使某些数据分区丢失,Spark也可以利用血统信息重新计算这些分区。不可变性:RDD是不可变的,这意味着一旦创建,其数据不会改变。这有助于容错,因为在数据重计算时可以确保数据的一致性。
任务重试,会在其他节点上重新运行(4)
检查点(checkpointing):即将RDD的当前状态保存到可靠的存储系统
数据复制
持久化:cache和persist
cache是persist的特例,cache默认存储在内存中,persist可自主选择更多存储级别
checkpoint(严格意义上不算持久化,算检查点):将RDD的中间结果写入HDFS等可靠存储系统中
cache:一般不使用,耗内存
persist:
缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存 储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存 中读取数据即可,否则需要再从头计算一次 RDD。
register:spark sql注册UDF(自定义函数)方法
aggregateByKey
aggregateByKey 算子是函数柯里化,存在两个参数列表 ,当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
- 第一个参数列表中的参数表示初始值
- 第二个参数列表中含有两个参数
2.1 第一个参数表示分区内的计算规则
2.2 第二个参数表示分区间的计算规则
背压机制
根据 JobScheduler 反馈作业的执行信息来动态调整 Receiver 没有java基础可以学spark吗 数据接收率
shuffle机制
● 未优化的HashShuffle
● 优化后的HashShuffle:合并机制:复用buffer
● SortShuffle
● bypass SortShuffle:相较于SortShuffle不会进行排序
spark sql数据倾斜
● 重新分区
● 广播小表:将 reduce join 转换为 map join
● 提高 shuffle 操作中的 reduce 并行度
● 过滤极端键值
● 对倾斜的键单独处理
● 加盐(添加随机键)
spark调优
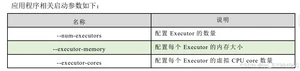
● 最优资源配置:–num-executors 配置 Executor 的数量 (提高执行task的并行度)
–driver-memory 配置 Driver 内存(影响不大)
–executor-memory 配置每个 Executor 的内存大小
–executor-cores 配置每个 Executor 的 CPU core 数量
● RDD优化:1、简化RDD 2、持久化多次使用的RDD 3、早做Filter操作
● 并行度调节:task 数量应该设置为 Spark 作业总 CPU core 数量的 2~3 倍
● 广播变量
● 转换各种算子,减少操作
● shuffle调优:调节map端或reduce端
null版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/25799.html