
序列化对象
将堆内存中的东西(对象)写到硬盘中
java的io流基础
写入对象的代码如下:
编译后运行出现以下结果:
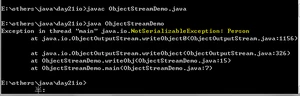
通过查找API了解该异常:

Person类需要具有序列化接口。

那么既然能将对象写进文件中,也就能将文件中得对象读出来,
调用读取文件的方法获取对象,得到如下结果:

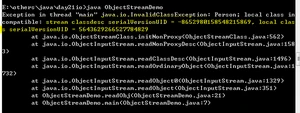
结果显示,从文件获取到的对象和调用Person获取到的对象的UID不一样,
当把private去掉之后,运行程序,就又可以获取到对象了,
这说明UID序列号是根据类的成员算出来的。
如果想要加上私有之后,还可以从之前的文件对象中获取到修改后的对象。
就是不让java给我算UID。我用自己定义UID,就可以了
这样不管参数中有没有加私有修饰符都不会影响从文件中读取对象。
注意,静态是不能被序列化的。
因为静态成员是在方法区中存在的,是不能被序列化的
只有堆中的对象才可以被序列化。
这是存入一个对象,如果存入多个对象的话也不用着急,因为readObject方法第一次读数据返回的是第一个对象,第二次读数据返回的就是第二个对象。
管道流
输入输出可以直接进行连接,通过结合线程使用。
PipedInputStream();
PipedOutputStream();

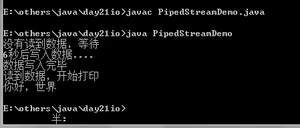
由图上信息可知,此处应该有多线程,
是什么原理呢?
运行结果:
随机访问文件RandomAccessFile
但是他是IO包中的成员,因为他具备读取和写入的功能。
内部封装了一个数组,而且通过指针对数组的元素进行操作
可以通过getFilePointer获取指针位置。
同时可以通过seek方法改变指针的位置。
其实完成读写的原理就是内部封装了字节输入流和输出流
如果模式为只读r,不会创建文件,会去读取一个已经存在的文件,如果该文件不存在,则会出现异常
如果模式为rw
而且该对象的构造函数要操作的文件不存在,会自动创建,如果存在不会覆盖。
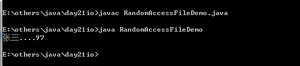
既然随机访问文件对象可以对文件进行读取和写入的,我们就先演示一下写文件的方法。
运行结果:
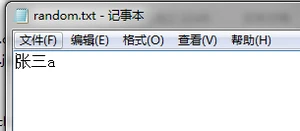
结果显示:可以存进去,但是写进去的97成了字符a。这是因为我写入的是字节数据,在写进记事本的时候,会按照传进来的字节数据按照查表的方式获取到相应的字符,然后写入到记事本中。
这里需要注意的是,自由访问文件流中的write方法和流中的write方法一样,也是只写八位,也就是一个字节(即使传进来的数据是4个字节或者更多),
那么就出现了局限性,要是我写入的数据长度大于一个字节的最大表示数(255)要写入的数据不仅仅是8位的数据
而write方法只能操作8位。
这样会造成数据的损失。
所以我们可以在写数据的时候用的是writeInt方法,可以一次写入4个字节的数据。
那么接下来演示读取文件中数据的方法。
重新用writInt方法写了一次人的年龄,所以人的年龄是4个字节了。
运行结果为:
如果要同时获取到张三李四的信息,可以直接在以上代码中将readDemo方法中的read方法和readInt方法再多写一次。
这里我想要直接获取到李四的信息,应该怎么做呢?
使用到了随机访问对象的设置指针的方法,seek方法
演示:
运行结果:

运行结果:
使用seek方法除了可以获取指定位置的元素,还可以在指定位置添加元素。包括跳过中间位置。
演示:
运行结果:

运行结果:
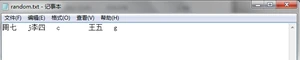
发现,在第一个位置存储的元素由张三变成了周七,seek可以实现对文件中数据的修改。
这样的原理可以用到下载视频上来,一个线程下载020M,同时另一个线程下载2040M,,,,这样下载下来的视频是有连接的,可以提高效率。
DataInputStream与DataOutputStream
可以用来操作基本数据类型的数据的流对象
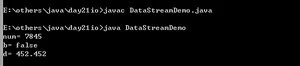
直接演示方法:
运行结果:

出现乱码,正常,因为是在记事本中,会有一个查编码表的过程。
接下来读取刚刚写入的数据
运行结果为
可以获取到数据。
writeUTF方法的演示:
运行结果:
 文件大小为8字节
文件大小为8字节
使用DataOutputStream的writeUTF方法写入的数据,只有同类的readUTF方法获取到数据。
读取数据
运行结果:

获取成功
当需要使用GBK或者UTF-8编码写入数据的时候用到了转换流:
写入成功:文件大小为4字节:

使用utf-8呢?
运行结果:写入成功,文件大小为6字节

当用readUTF(使用修改版的UTF_8编码表)方法读取用utf_8编码的文件时,会出现这样的效果:
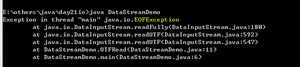
该异常的具体信息是:
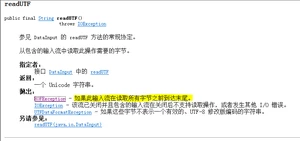
所以说用writeUTF写入的数据,只有用readUTF才能读取的出来。
那么utf-8编码表和readUTF码表中用到的utf_8修改版有什么不一样的呢?

操作字节数组
ByteArrayInputStream与ByteArrayOutputStream
用于操作字节数组的流对象
演示一下字节数组的操作方法。
运行结果为:

在流操作规律讲解时:
有时候要将一个文件中的内容放到一个数组里先存起来,这个时候,源就是硬盘,目的就是内存。就用到了字节数组对象。
其实字节数组流对象就是用流的思想来操作数组的,
设定自己的源和目的,判断读取的值是否为-1.也就是相当于判断有没有到了数组的末尾。
一次一次的读取操作也就是数组中的遍历元素。
写入操作也就是数组中的设置某一个位置上的元素的值。
只不过是把读取的方法封装起来了。
writeTo 方法
writeTo(OutputStream os):将数组中的数据写入到硬盘中取。
里边也存在源,就是要接收一个字符数组,
目的就是新建一个空的缓冲区。
里边的方法有toCharArray,append,write,toString
同时想操作数组的话还有StringReader和StringWriter
都是同样的道理源接收一个字符串作为源,目的是一个空的字符串。
字符编码
- 字符流的出现是为了方便操作字符
- 更重要的是加入了编码转换
- 通过子类转换流来完成
- InputStreamReader
- OutputStreamWriter
- 在两个对象进行构造的时候可以加入字符集
编码表的由来
- 计算机只能识别二进制数据,早期由来是电信号
- 为了方便应用计算机,让它可以识别各个国家的文字
- 就将各个国家的文字用数字来表示,并一一对应。形成一张表。
- 这就是编码表
常见的编码表
- ASCII美国标准信息交换码
- 用一个字节的7为就可以表示
- ISO8859-1:拉丁码表,欧洲码表
- 用一个字节 的8为表示
- GB2312:中国的中文编码表
- GBK:中国的中文编码表升级,融合了更多的中文文字符号
- Unicode:国际标准码,融合了多种文字
- 所有文字都用两个字节来表示,Java语言使用的就是Unicode
- UTF-8:最多用三个字节来表示一个字符。
那么现在,问题来了,GBK可以表示汉字的编码,UTF-8也可以表示汉字编码,但是相同的字在这两个编码表中不一样,这样会出什么问题呢?
用一段代码来演示:
接下来使用各自的读取方式去读文件
运行结果为:

那如果对文件进行读取的时候指定的编码表出现了错误的时候呢?
例如,使用GBK码表去读取UTF-8编码的文件,用UTF-8码表去读取GBK编码的文件
运行结果:
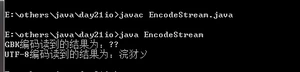
为什么会出来这种情况呢?
我们知道,GBK编码表中一个汉字占用的两个字节
而UTF-8码表中,一个汉字占用了三个字节
在具体读取中,过程是这样的。

字符编码
以上方法都是按照默认的编码表(GBK)来进行转换的。
先看看两种编码形式返回来的字节数组是什么样的:
运行结果:

运行结果:

发现默认编码和指定的GBK编码出来的字节数组是一样的,也就证实了,默认的编码方式是GBK的。
接下来用utf-8的方式进行编码,看看出来的字节数组是什么样的?
运行结果:

发现,使用utf-8编码之后返回一共有6个字节,也就是说一个汉字由三个字节组成。
以上是对汉字进行编码的过程,接下来演示解码GBK的过程。
运行结果:
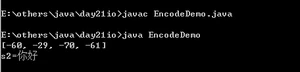
接下来演示解码UTF-8文件
运行结果:
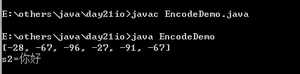
那么如果使用不同的编码表读取数据呢?
运行结果:

如果在写数据的时候使用了错误的编码形式,比如说ISO8859-1(欧洲语言码表),就没有办法了,因为发送了错误的编码形式,对方不知道这到底是什么样的编码形式。
运行结果:
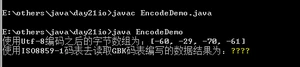
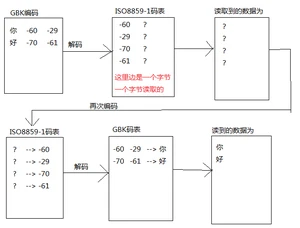
这是怎么样的一个过程呢?
当“你好”被解码的时候,解码成为-60,-29,-70,-61这是没有错的,
但是当解析的时候,用这些字节数组去查表的时候查的是ISO8859-1,
查一个,找不到,返回来一个?,后边的都一样找不到,所以会返回来4个?,
想要能把数据解析出来,可以这样做:
运行结果为:
过程是这样的:
这种方法适用在tomcat服务器的使用中,因为服务器中的默认编码形式为ISO8859-1,所以这就涉及到一个编码转换的问题了。
同样的道理,我们可不可以用GBK编码,用UTF-8解码,得到的乱码再进行编码,解码得到原来的数据呢?
运行结果为:

在上边运行结果中我们发现,第一次编码没有问题,得到了GBK对应的字节数组,
之后使用Utf-8码表去解析的时候出错了,得到了乱码字符,也没有问题
到对乱码在进行编码的时候,出现了和源码不一样的字节数组,
问题就出在了这里,
从GBK的编码获得的字节数组查Utf-8码表的时候找不到,返回了“?”
这个“?”在Utf-8中是存在了未知字符区域,
当再进行编码的时候就会给?重新编一个值,编成了一个三个字节的?
为什么Utf-8会重新编值呢?而ISO8859-1就不会重新编值呢?
因为Utf-8和GBK都可以识别中文,而ISO8859-1不识别中文,不会对中文进行编码,读到什么,解出来的还是什么。
联通的示例
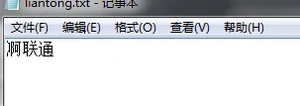
我在记事本上写下一个联通,然后保存再打开,结果成了这个样子:

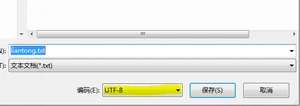
默认的GBK编码为什么会变成Utf-8编码的呢?
这个时候就要了解一下Utf-8中的编码格式了:
Utf-8中的编码形式如下图:

解读一下就是:
当读到的字节的首位是0的时候,就只读一个字节,回去查表
当读到的字节的首位是110,第二个字节的首位是10的时候,就读取两个字节,回去查表
当读到的字节的首位是1110,第二个字节的首位是10,第三个字节的首位是10的时候,就读取三个字节,回去查表
而联通这两个字,在内存中的二进制码是这样的:
四个字节的二进制码如下:

他是怎么样从GBK变啊变成Utf-8编码的呢?
当记事本将联通写入到文件中的时候,用GBK码表进行编码,编成如上图所示的二进制表现形式,
然后再打开记事本软件的时候,这就是一个解析编码的过程,
记事本一看,第一个字节首位是110,符合Utf-8编码的形式,继续往下读,发现是10,完全符合Utf-8编码形式,这就转变成Utf-8编码形式了。
这么多字符里边,只联通字符是这样的,其他字符并不这样,
解决方式:就是写联通的时候,在联通之前加上一个汉字,
练习:
有五个学生,每个学生有三门课程的成绩
从键盘输入以上数据,(包括姓名,三门课成绩)
输入的格式如:zhagnsanm30,40,32计算出总成绩
并把学生的信息和计算出的总分数高低顺序存放在磁盘文件“stud.txt”中
运行结果为:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/25836.html