
阅读全文
摘要: 原创出处 https://mp.weixin.qq.com/s/SVleHYFQeePNT7q67UoL4Q 「民工哥技术之路」欢迎转载,保留摘要,谢谢!
- Java 11 特性详解
- Java 12 新特详解
- Java 13 特性详解
- Java 14 特性详解
- Java 15 特性详解
- Java 16 特性详解
- Java 17 特性详解

🙂🙂🙂关注微信公众号:【芋道源码】有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
- 新的源码解析文章实时收到通知。每周更新一篇左右。
- 认真的源码交流微信群。
Java 11 特性详解
基于嵌套的访问控制
与 Java 语言中现有的嵌套类型概念一致, 嵌套访问控制是一种控制上下文访问的策略,允许逻辑上属于同一代码实体,但被编译之后分为多个分散的 class 文件的类,无需编译器额外的创建可扩展的桥接访问方法,即可访问彼此的私有成员,并且这种改进是在 Java 字节码级别的。
在 Java 11 之前的版本中,编译之后的 class 文件中通过 InnerClasses 和 Enclosing Method 两种属性来帮助编译器确认源码的嵌套关系,每一个嵌套的类会编译到自己所在的 class 文件中,不同类的文件通过上面介绍的两种属性的来相互连接。这两种属性对于编译器确定相互之间的嵌套关系已经足够了,但是并不适用于访问控制。这里大家可以写一段包含内部类的代码,并将其编译成 class 文件,然后通过 javap 命令行来分析,碍于篇幅,这里就不展开讨论了。
Java 11 中引入了两个新的属性:一个叫做 NestMembers 的属性,用于标识其它已知的静态 nest 成员;另外一个是每个 nest 成员都包含的 NestHost 属性,用于标识出它的 nest 宿主类。
标准 HTTP Client 升级
Java 11 对 Java 9 中引入并在 Java 10 中进行了更新的 Http Client API 进行了标准化,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。
新版 Java 中,Http Client 的包名由 jdk.incubator.http 改为 java.net.http,该 API 通过 CompleteableFutures 提供非阻塞请求和响应语义,可以联合使用以触发相应的动作,并且 RX Flo w 的概念也在 Java 11 中得到了实现。现在,在用户层请求发布者和响应发布者与底层套接字之间追踪数据流更容易了。这降低了复杂性,并最大程度上提高了 HTTP/1 和 HTTP/2 之间的重用的可能性。
Java 11 中的新 Http Client API,提供了对 HTTP/2 等业界前沿标准的支持,同时也向下兼容 HTTP/1.1,精简而又友好的 API 接口,与主流开源 API(如:Apache HttpClient、Jetty、OkHttp 等)类似甚至拥有更高的性能。与此同时它是 Java 在 Reactive-Stream 方面的第一个生产实践,其中广泛使用了 Java Flow API,终于让 Java 标准 HTTP 类库在扩展能力等方面,满足了现代互联网的需求,是一个难得的现代 Http/2 Client API 标准的实现,Java 工程师终于可以摆脱老旧的 HttpURLConnection 了。下面模拟 Http GET 请求并打印返回内容:
清单 1. GET 请求示例
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://openjdk.java.net/"))
.build();
client.sendAsync(request, BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println)
.join();
Epsilon:低开销垃圾回收器
Epsilon 垃圾回收器的目标是开发一个控制内存分配,但是不执行任何实际的垃圾回收工作。它提供一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间。
Java 版本中已经包含了一系列的高度可配置化的 GC 实现。各种不同的垃圾回收器可以面对各种情况。但是有些时候使用一种独特的实现,而不是将其堆积在其他 GC 实现上将会是事情变得更加简单。
下面是 no-op GC 的几个使用场景:
- 性能测试:什么都不执行的 GC 非常适合用于 GC 的差异性分析。no-op (无操作)GC 可以用于过滤掉 GC 诱发的性能损耗,比如 GC 线程的调度,GC 屏障的消耗,GC 周期的不合适触发,内存位置变化等。此外有些延迟者不是由于 GC 引起的,比如 scheduling hiccups, compiler transition hiccups,所以去除 GC 引发的延迟有助于统计这些延迟。
- 内存压力测试:在测试 Java 代码时,确定分配内存的阈值有助于设置内存压力常量值。这时 no-op 就很有用,它可以简单地接受一个分配的内存分配上限,当内存超限时就失败。例如:测试需要分配小于 1G 的内存,就使用-Xmx1g 参数来配置 no-op GC,然后当内存耗尽的时候就直接 crash。
- VM 接口测试:以 VM 开发视角,有一个简单的 GC 实现,有助于理解 VM-GC 的最小接口实现。它也用于证明 VM-GC 接口的健全性。
- 极度短暂 job 任务:一个短声明周期的 job 任务可能会依赖快速退出来释放资源,这个时候接收 GC 周期来清理 heap 其实是在浪费时间,因为 heap 会在退出时清理。并且 GC 周期可能会占用一会时间,因为它依赖 heap 上的数据量。延迟改进:对那些极端延迟敏感的应用,开发者十分清楚内存占用,或者是几乎没有垃圾回收的应用,此时耗时较长的 GC 周期将会是一件坏事。
- 吞吐改进:即便对那些无需内存分配的工作,选择一个 GC 意味着选择了一系列的 GC 屏障,所有的 OpenJDK GC 都是分代的,所以他们至少会有一个写屏障。避免这些屏障可以带来一点点的吞吐量提升。
- 如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
Epsilon 垃圾回收器和其他 OpenJDK 的垃圾回收器一样,可以通过参数 开启。
Epsilon 线性分配单个连续内存块。可复用现存 VM 代码中的 TLAB 部分的分配功能。非 TLAB 分配也是同一段代码,因为在此方案中,分配 TLAB 和分配大对象只有一点点的不同。Epsilon 用到的 barrier 是空的(或者说是无操作的)。因为该 GC
执行任何的 GC 周期,不用关系对象图,对象标记,对象复制等。引进一种新的 barrier-set 实现可能是该 GC 对 JVM 最大的变化。
简化启动单个源代码文件的方法
Java 11 版本中最令人兴奋的功能之一是增强 Java 启动器,使之能够运行单一文件的 Java 源代码。此功能允许使用 Java 解释器直接执行 Java 源代码。源代码在内存中编译,然后由解释器执行。唯一的约束在于所有相关的类必须定义在同一个 Java 文件中。
此功能对于开始学习 Java 并希望尝试简单程序的人特别有用,并且能与 jshell 一起使用,将成为任何初学者学习语言的一个很好的工具集。不仅初学者会受益,专业人员还可以利用这些工具来探索新的语言更改或尝试未知的 API。
如今单文件程序在编写小实用程序时很常见,特别是脚本语言领域。从中开发者可以省去用 Java 编译程序等不必要工作,以及减少新手的入门障碍。在基于 Java 10 的程序实现中可以通过三种方式启动:
- 作为 * .class 文件
- 作为 * .jar 文件中的主类
- 作为模块中的主类
而在最新的 Java 11 中新增了一个启动方式,即可以在源代码中声明类,例如:如果名为 HelloWorld.java 的文件包含一个名为 hello.World 的类,那么该命令:
$ java HelloWorld.java
也等同于:
$ javac HelloWorld.java
$ java -cp . hello.World
用于 Lambda 参数的局部变量语法
在 Lambda 表达式中使用局部变量类型推断是 Java 11 引入的唯一与语言相关的特性,这一节,我们将探索这一新特性。
从 Java 10 开始,便引入了局部变量类型推断这一关键特性。类型推断允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推断出类型。这一改进简化了代码编写、节省了开发者的工作时间,因为不再需要显式声明局部变量的类型,而是可以使用关键字 var,且不会使源代码过于复杂。
可以使用关键字 var 声明局部变量,如下所示:
var s = "Hello Java 11";
System.out.println(s);
但是在 Java 10 中,还有下面几个限制:
- 只能用于局部变量上
- 声明时必须初始化
- 不能用作方法参数
- 不能在 Lambda 表达式中使用
Java 11 与 Java 10 的不同之处在于允许开发者在 Lambda 表达式中使用 var 进行参数声明。乍一看,这一举措似乎有点多余,因为在写代码过程中可以省略 Lambda 参数的类型,并通过类型推断确定它们。但是,添加上类型定义同时使用 @Nonnull 和 @Nullable 等类型注释还是很有用的,既能保持与局部变量的一致写法,也不丢失代码简洁。
Lambda 表达式使用隐式类型定义,它形参的所有类型全部靠推断出来的。隐式类型 Lambda 表达式如下:
(x, y) -> x.process(y)
Java 10 为局部变量提供隐式定义写法如下:
var x = new Foo();
for (var x : xs) { ... }
try (var x = ...) { ... } catch ...
为了 Lambda 类型表达式中正式参数定义的语法与局部变量定义语法的不一致,且为了保持与其他局部变量用法上的一致性,希望能够使用关键字 var 隐式定义 Lambda 表达式的形参:
(var x, var y) -> x.process(y)
于是在 Java 11 中将局部变量和 Lambda 表达式的用法进行了统一,并且可以将注释应用于局部变量和 Lambda 表达式:
var x = new Foo();
( var x, var y) -> x.process(y)
低开销的 Heap Profiling
Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
引入这个低开销内存分析工具是为了达到如下目的:
- 足够低的开销,可以默认且一直开启
- 能通过定义好的程序接口访问
- 能够对所有堆分配区域进行采样
- 能给出正在和未被使用的 Java 对象信息
对用户来说,了解它们堆里的内存分布是非常重要的,特别是遇到生产环境中出现的高 CPU、高内存占用率的情况。目前有一些已经开源的工具,允许用户分析应用程序中的堆使用情况,比如:Java Flight Recorder、jmap、YourKit 以及 VisualVM tools.。但是这些工具都有一个明显的不足之处:无法得到对象的分配位置,headp dump 以及 heap histogram 中都没有包含对象分配的具体信息,但是这些信息对于调试内存问题至关重要,因为它能够告诉开发人员他们的代码中发生的高内存分配的确切位置,并根据实际源码来分析具体问题,这也是 Java 11 中引入这种低开销堆分配采样方法的原因。
支持 TLS 1.3 协议
Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升。
新版本中包含了 Java 安全套接字扩展(JSSE)提供 SSL,TLS 和 DTLS 协议的框架和 Java 实现。目前,JSSE API 和 JDK 实现支持 SSL 3.0,TLS 1.0,TLS 1.1,TLS 1.2,DTLS 1.0 和 DTLS 1.2。
同时 Java 11 版本中实现的 TLS 1.3,重新定义了以下新标准算法名称:
- TLS 协议版本名称:TLSv1.3
- SSLContext 算法名称:TLSv1.3
- TLS 1.3 的 TLS 密码套件名称:TLS_AES_128_GCM_SHA256,TLS_AES_256_GCM_SHA384
- 用于 X509KeyManager 的 keyType:RSASSA-PSS
- 用于 X509TrustManager 的 authType:RSASSA-PSS
还为 TLS 1.3 添加了一个新的安全属性 jdk.tls.keyLimits。当处理了特定算法的指定数据量时,触发握手后,密钥和 IV 更新以导出新密钥。还添加了一个新的系统属性 jdk.tls.server.protocols,用于在 SunJSSE 提供程序的服务器端配置默认启用的协议套件。
之前版本中使用的 KRB5 密码套件实现已从 Java 11 中删除,因为该算法已不再安全。同时注意,TLS 1.3 与以前的版本不直接兼容。
升级到 TLS 1.3 之前,需要考虑如下几个兼容性问题:
- TLS 1.3 使用半关闭策略,而 TLS 1.2 以及之前版本使用双工关闭策略,对于依赖于双工关闭策略的应用程序,升级到 TLS 1.3 时可能存在兼容性问题。
- TLS 1.3 使用预定义的签名算法进行证书身份验证,但实际场景中应用程序可能会使用不被支持的签名算法。
- TLS 1.3 再支持 DSA 签名算法,如果在服务器端配置为仅使用 DSA 证书,则无法升级到 TLS 1.3。
- TLS 1.3 支持的加密套件与 TLS 1.2 和早期版本不同,若应用程序硬编码了加密算法单元,则在升级的过程中需要修改相应代码才能升级使用 TLS 1.3。
- TLS 1.3 版本的 session 用行为及秘钥更新行为与 1.2 及之前的版本不同,若应用依赖于 TLS 协议的握手过程细节,则需要注意。
ZGC:可伸缩低延迟垃圾收集器
ZGC 即 Z Garbage Collector(垃圾收集器或垃圾回收器),这应该是 Java 11 中最为瞩目的特性,没有之一。ZGC 是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colord
- 针以及 Load barriers 优化奠定基础
- 当前只支持 Linux/x64 位平台 停顿时间在 10ms 以下,10ms 其实是一个很保守的数据,即便是 10ms 这个数据,也是 GC 调优几乎达不到的极值。根据 SPECjbb 2015 的基准测试,128G 的大堆下最大停顿时间才 1.68ms,远低于 10ms,和 G1 算法相比,改进非常明显。
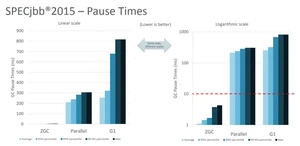
不过目前 ZGC 还处于实验阶段,目前只在 Linux/x64 上可用,如果有足够的需求,将来可能会增加对其他平台的支持。同时作为实验性功能的 ZGC 将不会出现在 JDK 构建中,除非在编译时使用 configure 参数: 显式启用。
在实验阶段,编译完成之后,已经迫不及待的想试试 ZGC,需要配置以下 JVM 参数,才能使用 ZGC,具体启动 ZGC 参数如下:
-XX:+ UnlockExperimentalVMOptions -XX:+ UseZGC -Xmx10g
其中参数:-Xmx 是 ZGC 收集器中最重要的调优选项,大大解决了程序员在 JVM 参数调优上的困扰。ZGC 是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:
- 对象的分配速率,要保证在 java 基础 代码 详解 GC 的时候,堆中有足够的内存分配新对象。
- 一般来说,给 ZGC 的内存越多越好,但是也不能浪费内存,所以要找到一个平衡。
飞行记录器
飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了。
Java 语言中的飞行记录器类似飞机上的黑盒子,是一种低开销的事件信息收集框架,主要用于对应用程序和 JVM 进行故障检查、分析。飞行记录器记录的主要数据源于应用程序、JVM 和 OS,这些事件信息保存在单独的事件记录文件中,故障发生后,能够从事件记录文件中提取出有用信息对故障进行分析。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
启用飞行记录器参数如下:
-XX:StartFlightRecording
也可以使用 bin/jcmd 工具启动和配置飞行记录器:
清单 2. 飞行记录器启动、配置参数示例
$ jcmd <pid> JFR.start $ jcmd <pid> JFR.dump filename=recording.jfr $ jcmd <pid> JFR.stop
JFR 使用测试:
清单 3. JFR 使用示例
public class FlightRecorderTest extends Event {
("Hello World")
("Helps the programmer getting started")
static class HelloWorld extends Event {
("Message")
String message;
}
public static void main(String[] args) {
HelloWorld event = new HelloWorld();
event.message = "hello, world!";
event.commit();
}
}
在运行时加上如下参数:
java -XX:StartFlightRecording=duration=1s, filename=recording.jfr
下面读取上一步中生成的 JFR 文件:recording.jfr
清单 4. 飞行记录器分析示例
public void readRecordFile() throws IOException {
final Path path = Paths.get("D:\ java \recording.jfr");
final List<RecordedEvent> recordedEvents = RecordingFile.readAllEvents(path);
for (RecordedEvent event : recordedEvents) {
System.out.println(event.getStartTime() + "," + event.getValue("message"));
}
}
动态类文件常量
为了使 JVM 对动态语言更具吸引力,Java 的第七个版本已将 invokedynamic 引入其指令集。
不过 Java 开发人员通常不会注意到此功能,因为它隐藏在 Java 字节代码中。通过使用 invokedynamic,可以延迟方法调用的绑定,直到第一次调用。例如,Java 语言使用该技术来实现 Lambda 表达式,这些表达式仅在首次使用时才显示出来。这样做,invokedynamic 已经演变成一种必不可少的语言功能。
Java 11 引入了类似的机制,扩展了 Java 文件格式,以支持新的常量池:CONSTANT_Dynamic,它在初始化的时候,像 invokedynamic 指令生成代理方法一样,委托给 bootstrap 方法进行初始化创建,对上层软件没有很大的影响,降低开发新形式的可实现类文件约束带来的成本和干扰。
结束语
Java 在更新发布周期为每半年发布一次之后,在合并关键特性、快速得到开发者反馈等方面,做得越来越好。Java 11 版本的发布也带来了不少新特性和功能增强、性能提升、基础能力的全面进步和突破,本文针对其中对使用人员影响重大的以及主要的特性做了介绍。Java 12 即将到来,您准备好了吗?
Java 12 新特详解
Shenandoah:一个低停顿垃圾收集器(实验阶段)
Java 12 中引入一个新的垃圾收集器:Shenandoah,它是作为一中低停顿时间的垃圾收集器而引入到 Java 12 中的,其工作原理是通过与 Java 应用程序中的执行线程同时运行,用以执行其垃圾收集、内存回收任务,通过这种运行方式,给虚拟机带来短暂的停顿时间。
Shenandoah 垃圾回收器是 Red Hat 在 2014 年宣布进行的一项垃圾收集器研究项目,旨在针对 JVM 上的内存收回实现低停顿的需求。该设计将与应用程序线程并发,通过交换 CPU 并发周期和空间以改善停顿时间,使得垃圾回收器执行线程能够在 Java 线程运行时进行堆压缩,并且标记和整理能够同时进行,因此避免了在大多数 JVM 垃圾收集器中所遇到的问题。
据 Red Hat 研发 Shenandoah 团队对外宣称,Shenandoah 垃圾回收器的暂停时间与堆大小无关,这意味着无论将堆设置为 200 MB 还是 200 GB,都将拥有一致的系统暂停时间,不过实际使用性能将取决于实际工作堆的大小和工作负载。
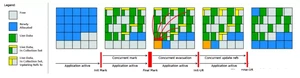
上图对应工作周期如下:
- 1.Init Mark 启动并发标记 阶段
- 2.并发标记遍历堆阶段
- 3.并发标记完成阶段
- 4.并发整理回收无活动区域阶段
- 5.并发 Evacuation 整理内存区域阶段
- 6.Init Update Refs 更新引用初始化 阶段
- 7.并发更新引用阶段
- 8.Final Update Refs 完成引用更新阶段
- 9.并发回收无引用区域阶段
需要了解不是唯有 GC 停顿可能导致常规应用程序响应时间比较长。具有较长的 GC 停顿时间会导致系统响应慢的问题,但响应时间慢并非一定是 GC 停顿时间长导致的,队列延迟、网络延迟、其他依赖服务延迟和操作提供调度程序抖动等都可能导致响应变慢。使用 Shenandoah 时需要全面了解系统运行情况,综合分析系统响应时间。各种 GC 工作负载对比如下所示:
下面推荐几个配置或调试 Shenandoah 的 JVM 参数:
- -XX:+AlwaysPreTouch:使用所有可用的内存分页,减少系统运行停顿,为避免运行时性能损失。
- -Xmx == -Xmsv:设置初始堆大小与最大值一致,可以减轻伸缩堆大小带来的压力,与 AlwaysPreTouch 参数配合使用,在启动时提交所有内存,避免在最终使用中出现系统停顿。
- -XX:+ UseTransparentHugePages:能够大大提高大堆的性能,同时建议在 Linux 上使用时将 /sys/kernel/mm/transparent_hugepage/enabled 和 /sys/kernel/mm/transparent_hugepage/defragv 设置为:madvise,同时与 AlwaysPreTouch 一起使用时,init 和 shutdownv 速度会更快,因为它将使用更大的页面进行预处理。
- -XX:+UseNUMA:虽然 Shenandoah 尚未明确支持 NUMA(Non-Uniform Memory Access),但最好启用此功能以在多插槽主机上启用 NUMA 交错。与 AlwaysPreTouch 相结合,它提供了比默认配置更好的性能。
- -XX:+DisableExplicitGC:忽略代码中的 System.gc() 调用。当用户在代码中调用 System.gc() 时会强制 Shenandoah 执行 STW Full GC ,应禁用它以防止执行此操作,另外还可以使用 -XX:+ExplicitGCInvokesConcurrent,在 调用 System.gc() 时执行 CMS GC 而不是 Full GC,建议在有 System.gc() 调用的情况下使用。
- 不过目前 Shenandoah 垃圾回收器还被标记为实验项目,需要使用参数:- XX:+UnlockExperimentalVMOptions 启用。更多有关如何配置、调试 Shenandoah 的信息,请参阅 henandoah wiki。
增加一套微基准套件
Java 12 中添加一套新的基本的微基准测试套件,该套微基准测试套件基于 JMH(Java Microbenchmark Harness),使开发人员可以轻松运行现有的微基准测试并创建新的基准测试,其目标在于提供一个稳定且优化过的基准,其中包括将近 100 个基准测试的初始集合,并且能够轻松添加新基准、更新基准测试和提高查找已有基准测试的便利性。
微基准套件与 JDK 源代码位于同一个目录中,并且在构建后将生成单个 Jar 文件。但它是一个单独的项目,在支持构建期间不会执行,以方便开发人员和其他对构建微基准套件不感兴趣的人在构建时花费比较少的构建时间。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
要构建微基准套件,用户需要运行命令:make build-microbenchmark,类似的命令还有:make test TEST="micro:java.lang.invoke" 将使用默认设置运行 java.lang.invoke 相关的微基准测试。关于配置本地环境可以参照文档 docs/testing.md|html。
Switch 表达式扩展(预览功能)
Java 11 以及之前 Java 版本中的 Switch 语句是按照类似 C、C++ 这样的语言来设计的,在默认情况下支持 fall-through 语法。虽然这种传统的控制流通常用于编写低级代码,但 Switch 控制语句通常运用在高级别语言环境下的,因此其容易出错性掩盖其灵活性。
在 Java 12 中重新拓展了 Switch 让它具备了新的能力,通过扩展现有的 Switch 语句,可将其作为增强版的 Switch 语句或称为 "Switch 表达式"来写出更加简化的代码。
Switch 表达式也是作为预览语言功能的第一个语言改动被引入新版 Java 中来的,预览语言功能的想法是在 2018 年初被引入 Java 中的,本质上讲,这是一种引入新特性的测试版的方法。通过这种方式,能够根据用户反馈进行升级、更改,在极端情况下,如果没有被很好的接纳,则可以完全删除该功能。预览功能的关键在于它们没有被包含在 Java SE 规范中。
在 Java 11 以及之前版本中传统形式的 Switch 语句写法如下:
清单 1. Switch 语句示例
int dayNumber;
switch (day) {
case MONDAY:
case FRIDAY:
case SUNDAY:
dayNumber = 6;
break;
case TUESDAY:
dayNumber = 7;
break;
case THURSDAY:
case SATURDAY:
dayNumber = 8;
break;
case WEDNESDAY:
dayNumber = 9;
break;
default:
throw new IllegalStateException("Huh? " + day);
}
上面代码中多处出现 break 语句,显得代码比较冗余,同时如果某处漏写一段 break 语句,将导致程序一直向下穿透执行的逻辑错误,出现异常结果,同时这种写法比较繁琐,也容易出问题。
换做 Java 12 中的 Switch 表达式,上述语句写法如下:
清单 2. Switch 表达式示例
int dayNumber = switch (day) {
case MONDAY, FRIDAY, SUNDAY -> 6;
case TUESDAY -> 7;
case THURSDAY, SATURDAY -> 8;
case WEDNESDAY -> 9;
default -> throw new IllegalStateException("Huh? " + day);
}
使用 Java 12 中 Switch 表达式的写法,省去了 break 语句,避免了因少些 break 而出错,同时将多个 case 合并到一行,显得简洁、清晰也更加优雅的表达逻辑分支,其具体写法就是将之前的 case 语句表成了:case L ->,即如果条件匹配 case L,则执行 标签右侧的代码 ,同时标签右侧的代码段只能是表达式、代码块或 throw 语句。为了保持兼容性,case 条件语句中依然可以使用字符 : ,这时 fall-through 规则依然有效的,即不能省略原有的 break 语句,但是同一个 Switch 结构里不能混用 -> 和 : ,否则会有编译错误。并且简化后的 Switch 代码块中定义的局部变量,其作用域就限制在代码块中,而不是蔓延到整个 Switch 结构,也不用根据不同的判断条件来给变量赋值。
Java 11 以及之前版本中,Switch 表达式支持下面类型:byte、char、short、int、Byte、Character、Short、Integer、enum、tring,在未来的某个 Java 版本有可能会允许支持 float、double 和 long (以及上面类型的封装类型)。
引入 JVM 常量 API
Java 12 中引入 JVM 常量 API,用来更容易地对关键类文件 (key class-file) 和运行时构件(artefact)的名义描述 (nominal description) 进行建模,特别是对那些从常量池加载的常量,这是一项非常技术性的变化,能够以更简单、标准的方式处理可加载常量。
此项改进主要在新的 java.lang.invoke.constant 包中定义了一系列基于值的符号引用类型,能够描述每种可加载常量。符号引用以纯粹 nominal 的形式描述可加载常量,与类加载或可访问 性上下文分开。同时有些类可以作为自己的符号引用(例如 String),而对于可链接常量,另外定义了一系列符号引用类型,具体包括:ClassDesc (Class 的可加载常量标称描述符) ,MethodTypeDesc(方法类型常量标称描述符) ,MethodHandleDesc (方法句柄常量标称描述符) 和 DynamicConstantDesc (动态常量标称描述符) ,它们包含描述这些常量的 nominal 信息。
改进 AArch64 实现
Java 12 中将只保留一套 AArch64 实现,删除所有与 arm64 实现相关的代码,只保留 32 位 ARM 端口和 64 位 aarch64 的端口。删除此套实现将允许所有开发人员将目标集中在剩下的这个 64 位 ARM 实现上,消除维护两套端口所需的重复工作。
当前 Java 11 中存在两套 64 位 AArch64 端口,它们主要存在于 src/hotspot/cpu/arm 和 open/src/hotspot/cpu/aarch64 目录中。这两套代码中都实现了 AArch64,Java 12 中将删除目录 open/src/hotspot/cpu/arm 中关于 64-bit 的这套实现,只保留其中有关 32-bit 的实现,余下目录的 open/src/hotspot/cpu/aarch64 代码部分就成了 AArch64 的默认实现。
使用默认类数据共享(CDS)存档
类数据共享机制 (Class Data Sharing ,简称 CDS) ,允许将一组类预处理为共享归档文件,以便在运行时能够进行内存映射以减少 Java 程序的启动时间,当多个 Java 虚拟机(JVM)共享相同的归档文件时,还可以减少动态内存的占用量,同时减少多个虚拟机在同一个物理或虚拟的机器上运行时的资源占用。
自 Java 8 以来,在基本 CDS 功能上进行了许多增强、改进,启用 CDS 后应用的启动时间和内存占用量显着减少。使用 Java 11 早期版本在 64 位 Linux 平台上运行 HelloWorld 进行测试,测试结果显示启动时间缩短有 32 %,同时在其他 64 位平台上,也有类似或更高的启动性能提升。
Java 12 针对 64 位平台下的 JDK 构建过程进行了增强改进,使其默认生成类数据共享(CDS)归档,以进一步达到改进应用程序的启动时间的目的,同时也避免了需要手动运行:-Xshare:dump 的需要,修改后的 JDK 将在 lib/server 目录中保留构建时生成的 CDS 存档。
当然如果需要,也可以添加其他 GC 参数,来调整堆大小等,以获得更优的内存分布情况,同时用户也可以像之前一样创建自定义的 CDS 存档文件。
改善 G1 垃圾收集器,使其能够中止混合集合
G1 是垃圾收集器,设计用于具有大量内存的多处理器机器,提高了垃圾回收效率。该垃圾收集器 设计的主要目标之一是满足用户设置的预期的 JVM 停顿时间,G1 采用一个高级分析引擎来选择在收集期间要处理的工作量,此选择过程的结果是一组称为 GC 回收集的区域。一旦收集器确定了 GC 回收集 并且 GC 回收、整理工作已经开始,则 G1 收集器必须完成收集集合集的所有区域中的所有活动对象之后才能停止;但是如果收集器选择过大的 GC 回收集,可能会导致 G1 回收器停顿时间超过预期时间。
Java 12 中将把 GC 回收集(混合收集集合)拆分为必需和可选两部分,使 G1 垃圾回收器能中止垃圾回收过程。其中必需处理的部分包括 G1 垃圾收集器不能递增处理的 GC 回收集的部分(如:年轻代),同时也可以包含老年代以提高处理效率。将 GC 回收集拆分为必需和可选部分时,需要为可选 GC 回收集部分维护一些其他数据,这会产生轻微的 CPU 开销,但小于 1 %的变化,同时在 G1 回收器处理 GC 回收集期间,本机内存使用率也可能会增加,使用上述情况只适用于包含可选 GC 回收部分的 GC 混合回收集合。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
在 G1 垃圾回收器完成收集需要必需回收的部分之后,便开始收集可选的部分,如果还有时间的话,但是粗粒度的处理,可选部分的处理粒度取决于剩余的时间,一次只能处理可选部分的一个子集区域。在完成可选收集部分的收集后,G1 垃圾回收器可以根据剩余时间决定是否停止收集。如果在处理完 必需处理的 部分后,属于时间不足,总时间花销接近预期时间,G1 垃圾回收器也可以中止可选部分的回收以达到满足预期停顿时间的目标。
增强 G1 垃圾收集器,使其能自动返回未用堆内存给操作系统
上节中介绍了 Java 12 中增强了 G1 垃圾收集器关于混合收集集合的处理策略,这节主要介绍在 Java 12 中同时也对 G1 垃圾回收器进行了改进,使其能够在空闲时自动将 Java 堆内存返还给操作系统,这也是 Java 12 中的另外一项重大改进。
目前 Java 11 版本中包含的 G1 垃圾收集器 暂时无法及时将已提交的 Java 堆内存返回给操作系统, G1 垃圾收集器仅在进行完整 GC (Full GC) 或并发处理周期时才能将 Java 堆返回内存。由于 G1 回收器尽可能避免完整 GC,并且只触发基于 Java 堆占用和分配活动的并发周期,因此在许多情况下 G 1 垃圾回收器不能回收 Java 堆内存,除非有外部强制执行。
在使用云平台的容器环境中,这种不利之处特别明显。即使在虚拟机不活动,但如果仍然使用其分配的内存资源,哪怕是其中的一小部分,G1 回收器也仍将保留所有已分配的 Java 堆内存。而这将导致用户需要始终为所有资源付费,哪怕是实际并未用到,而云提供商也无法充分利用其硬件。如果在次期间虚拟机能够检测到 Java 堆内存的实际使用情况,并在利用空闲时间自动将 Java 堆内存返还,则两者都将受益。
为了尽可能的向操作系统返回空闲内存,G1 垃圾收集器将在应用程序不活动期间定期生成或持续循环检查整体 Java 堆使用情况,以便 G 1 垃圾收集器能够更及时的将 Java 堆中不使用内存部分返还给操作系统。对于长时间处于空闲状态的应用程序,此项改进将使 JVM 的内存利用率更加高效。
如果应用程序为非活动状态,在下面两种情况下,G1 回收器会触发定期垃圾收集:
自上次垃圾回收完成 以来已超过 G1PeriodicGCInterva l 毫秒, 并且此时没有正在进行的垃圾回收任务。如果 G1PeriodicGCInterval 值为零表示禁用快速回收内存的定期垃圾收集。应用所在主机系统上执行方法 getloadavg(),一分钟内系统返回的平均负载值低于 G1PeriodicGCSystemLoadThreshold。如果 G1PeriodicGCSystemLoadThreshold 值为零,则此条件不生效。如果不满足上述条件中的任何一个,则取消当期的定期垃圾回收。等一个 G1PeriodicGCInterval 时间周期后,将重新考虑是否执行定期垃圾回收。
G1 定期垃圾收集的类型根据 G1PeriodicGCInvokesConcurrent 参数的值确定:如果设置值了,G1 垃圾回收器将继续上一个或者启动一个新并发周期;如果没有设置值,则 G1 回收器将执行一个完整的 GC。在每次一次 GC 回收末尾,G1 回收器将调整当前的 Java 堆大小,此时便有可能会将未使用内存返还给操作系统。新的 Java 堆内存大小根据现有配置确定,具体包括下列配置:- XX:MinHeapFreeRatio、-XX:MaxHeapFreeRatio、-Xms、-Xmx。
默认情况下,G1 回收器在定期垃圾回收期间新启动或继续上一轮并发周期,将最大限度地减少应用程序的中断。如果定期垃圾收集严重影响程序执行,则需要考虑整个系统 CPU 负载,或让用户禁用定期垃圾收集。
Java 13 特性详解
动态应用程序类-数据共享
在 Java 10 中,为了改善应用启动时间和内存空间占用,通过使用 APP CDS,加大了 CDS 的使用范围,允许自定义的类加载器也可以加载自定义类给多个 JVM 共享使用,具体介绍可以参考 Java 10 新特性介绍一文详细介绍,在此就不再继续展开。
Java 13 中对 Java 10 中引入的 应用程序类数据共享进行了进一步的简化、改进和扩展,即:允许在 Java 应用程序执行结束时动态进行类归档,具体能够被归档的类包括:所有已被加载,但不属于默认基层 CDS 的应用程序类和引用类库中的类。通过这种改进,可以提高应用程序类-数据使用上的简易性,减少在使用类-数据存档中需要为应用程序创建类加载列表的必要,简化使用类-数据共享的步骤,以便更简单、便捷地使用 CDS 存档。
在 Java 中,如果要执行一个类,首先需要将类编译成对应的字节码文件,以下是 JVM 装载、执行等需要的一系列准备步骤:假设给定一个类名,JVM 将在磁盘上查找到该类对应的字节码文件,并将其进行加载,验证字节码文件,准备,解析,初始化,根据其内部数据结构加载到内存中。当然,这一连串的操作都需要一些时间,这在 JVM 启动并且需要加载至少几百个甚至是数千个类时,加载时间就尤其明显。
Java 10 中的 App CDS 主要是为了将不变的类数据,进行一次创建,然后存储到归档中,以便在应用重启之后可以对其进行内存映射而直接使用,同时也可以在运行的 JVM 实例之间共享使用。但是在 Java 10 中使用 App CDS 需要进行如下操作:
- 创建需要进行类归档的类列表
- 创建归档
- 使用归档方式启动
在使用归档文件启动时,JVM 将归档文件映射到其对应的内存中,其中包含所需的大多数类,而
需要使用多么复杂的类加载机制。甚至可以在并发运行的 JVM 实例之间共享内存区域,通过这种方式可以释放需要在每个 JVM 实例中创建相同信息时浪费的内存,从而节省了内存空间。
在 Java 12 中,默认开启了对 JDK 自带 JAR 包类的存档,如果想关闭对自带类库的存档,可以在启动参数中加上:
-Xshare:off
而在 Java 13 中,可以不用提供归档类列表,而是通过更简洁的方式来创建包含应用程序类的归档。具体可以使用参数 来控制应用程序在退出时生成存档,也可以使用 来使用动态存档功能,详细使用见如下示例。
清单 1. 创建存档文件示例
$ java -XX:ArchiveClassesAtExit=helloworld.jsa -cp helloworld.jar Hello
清单 2. 使用存档文件示例
$ java -XX:SharedArchiveFile=hello.jsa -cp helloworld.jar Hello
上述就是在 Java 应用程序执行结束时动态进行类归档,并且在 Java 10 的基础上,将多条命令进行了简化,可以更加方便地使用类归档功能。
增强 ZGC 释放未使用内存
ZGC 是 Java 11 中引入的最为瞩目的垃圾回收特性,是一种可伸缩、低延迟的垃圾收集器,不过在 Java 11 中是实验性的引入,主要用来改善 GC 停顿时间,并支持几百 MB 至几个 TB 级别大小的堆,并且应用吞吐能力下降不会超过 15%,目前只支持 Linux/x64 位平台的这样一种新型垃圾收集器。
通过在实际中的使用,发现 ZGC 收集器中并没有像 Hotspot 中的 G1 和 Shenandoah 垃圾收集器一样,能够主动将未使用的内存释放给操作系统的功能。对于大多数应用程序来说,CPU 和内存都属于有限的紧缺资源,特别是现在使用的云上或者虚拟化环境中。如果应用程序中的内存长期处于空闲状态,并且还不能释放给操作系统,这样会导致其他需要内存的应用无法分配到需要的内存,而这边应用分配的内存还处于空闲状态,处于”忙的太忙,闲的太闲”的非公平状态,并且也容易导致基于虚拟化的环境中,因为这些实际并未使用的资源而多付费的情况。由此可见,将未使用内存释放给系统主内存是一项非常有用且亟需的功能。
ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 ZPageCache 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织。在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用。同时释放这些未使用的内存给操作系统不会导致堆大小缩小到参数设置的最小大小以下,如果将最小和最大堆大小设置为相同的值,则不会释放任何内存给操作系统。
Java 13 中对 ZGC 的改进,主要体现在下面几点:
- 释放未使用内存给操作系统
- 支持最大堆大小为 16TB
- 添加参数:-XX:SoftMaxHeapSize 来软限制堆大小
这里提到的是软限制堆大小,是指 GC 应努力是堆大小不要超过指定大小,但是如果实际需要,也还是允许 GC 将堆大小增加到超过 SoftMaxHeapSize 指定值。主要用在下面几种情况:当希望降低堆占用,同时保持应对堆空间临时增加的能力,亦或想保留充足内存空间,以能够应对内存分配,而不会因为内存分配意外增加而陷入分配停滞状态。不应将 SoftMaxHeapSize 设置为大于最大堆大小(-Xmx 的值,如果未在命令行上设置,则此标志应默认为最大堆大小。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
Java 13 中,ZGC 内存释放功能,默认情况下是开启的,不过可以使用参数:-XX:-ZUncommit 显式关闭,同时如果将最小堆大小 (-Xms) 配置为等于最大堆大小 (-Xmx),则将隐式禁用此功能。
还可以使用参数:(默认值为 300 秒)来配置延迟释放,此延迟时间可以指定释放多长时间之前未使用的内存。
Socket API 重构
Java 中的 Socket API 已经存在了二十多年了,尽管这么多年来,一直在维护和更新中,但是在实际使用中遇到一些局限性,并且不容易维护和调试,所以要对其进行大修大改,才能跟得上现代技术的发展,毕竟二十多年来,技术都发生了深刻的变化。Java 13 为 Socket API 带来了新的底层实现方法,并且在 Java 13 中是默认使用新的 Socket 实现,使其易于发现并在排除问题同时增加可维护性。
Java Socket API(java.net.ServerSocket 和 java.net.Socket)包含允许监听控制服务器和发送数据的套接字对象。可以使用 ServerSocket 来监听连接请求的端口,一旦连接成功就返回一个 Socket 对象,可以使用该对象读取发送的数据和进行数据写回操作,而这些类的繁重工作都是依赖于 SocketImpl 的内部实现,服务器的发送和接收两端都基于 SOCKS 进行实现的。
在 Java 13 之前,通过使用 PlainSocketImpl 作为 SocketImpl 的具体实现。
Java 13 中的新底层实现,引入 NioSocketImpl 的实现用以替换 SocketImpl 的 PlainSocketImpl 实现,此实现与 NIO(新 I/O)实现共享相同的内部基础结构,并且与现有的缓冲区高速缓存机制集成在一起,因此不需要使用线程堆栈。除了这些更改之外,还有其他一些更便利的更改,如使用 java.lang.ref.Cleaner 机制来关闭套接字(如果 SocketImpl 实现在尚未关闭的套接字上被进行了垃圾收集),以及在轮询时套接字处于非阻塞模式时处理超时操作等方面。
为了最小化在重新实现已使用二十多年的方法时出现问题的风险,在引入新实现方法的同时,之前版本的实现还未被移除,可以通过使用下列系统属性以重新使用原实现方法:
-Djdk.net.usePlainSocketImpl = true
另外需要注意的是,SocketImpl 是一种传统的 SPI 机制,同时也是一个抽象类,并未指定具体的实现,所以,新的实现方式尝试模拟未指定的行为,以达到与原有实现兼容的目的。但是,在使用新实现时,有些基本情况可能会失败,使用上述系统属性可以纠正遇到的问题,下面两个除外。
- 老版本中,PlainSocketImpl 中的 getInputStream() 和 getOutputStream() 方法返回的 InputStream 和 OutputStream 分别来自于其对应的扩展类型 FileInputStream 和 FileOutputStream,而这个在新版实现中则没有。
- 使用自定义或其它平台的 SocketImpl 的服务器套接字无法接受使用其他(自定义或其它平台)类型 SocketImpl 返回 Sockets 的连接。
通过这些更改,Java Socket API 将更易于维护,更好地维护将使套接字代码的可靠性得到改善。同时 NIO 实现也可以在基础层面完成,从而保持 Socket 和 ServerSocket 类层面上的不变。
Switch 表达式扩展(预览功能)
在 Java 12 中引入了 Switch 表达式作为预览特性,而在 Java 13 中对 Switch 表达式做了增强改进,在块中引入了 yield 语句来返回值,而不是使用 break。这意味着,Switch 表达式(返回值)应该使用 yield,而 Switch 语句(不返回值)应该使用 break,而在此之前,想要在 Switch 中返回内容,还是比较麻烦的,只不过目前还处于预览状态。
在 Java 13 之后,Switch 表达式中就多了一个关键字用于跳出 Switch 块的关键字 yield,主要用于返回一个值,它和 return 的区别在于:return 会直接跳出当前循环或者方法,而 yield 只会跳出当前 Switch块,同时在使用 yield 时,需要有 default 条件。
在 Java 12 之前,传统 Switch 语句写法为:
清单 3. 传统形式
private static String getText(int number) {
String result = "";
switch (number) {
case 1, 2:
result = "one or two";
break;
case 3:
result = "three";
break;
case 4, 5, 6:
result = "four or five or six";
break;
default:
result = "unknown";
break;
};
return result;
}
在 Java 12 之后,关于 Switch 表达式的写法改进为如下:
清单 4. 标签简化形式
private static String getText(int number) {
String result = switch (number) {
case 1, 2 -> "one or two";
case 3 -> "three";
case 4, 5, 6 -> "four or five or six";
default -> "unknown";
};
return result;
}
而在 Java 13 中,value break 语句不再被编译,而是用 yield 来进行值返回,上述写法被改为如下写法:
清单 5. yield 返回值形式
private static String getText(int number) { return switch (number) { case 1, 2: yield "one or two"; case 3: yield "three"; case 4, 5, 6: yield "four or five or six"; default: yield "unknown"; };}
文本块(预览功能)
一直以来,Java 语言在定义字符串的方式是有限的,字符串需要以双引号开头,以双引号结尾,这导致字符串不能够多行使用,而是需要通过换行转义或者换行连接符等方式来变通支持多行,但这样会增加编辑工作量,同时也会导致所在代码段难以阅读、难以维护。
Java 13 引入了文本块来解决多行文本的问题,文本块以三重双引号开头,并以同样的以三重双引号结尾终止,它们之间的任何内容都被解释为字符串的一部分,包括换行符,避免了对大多数转义序列的需要,并且它仍然是普通的 java.lang.String 对象,文本块可以在 Java 中可以使用字符串文字的任何地方使用,而与编译后的代码没有区别,还增强了 Java 程序中的字符串可读性。并且通过这种方式,可以更直观地表示字符串,可以支持跨越多行,而且不会出现转义的视觉混乱,将可以广泛提高 Java 类程序的可读性和可写性。
在 Java 13 之前,多行字符串写法为:
清单 6. 多行字符串写法
String html ="<html> " +
" <body> " +
" <p>Hello, World</p> " +
" </body> " +
"</html> ";
String json ="{ " +
" "name":"mkyong", " +
" "age":38 " +
"} ";
在 Java 13 引入文本块之后,写法为:
清单 7. 多行文本块写法
String html = """
<html>
<body>
<p>Hello, World</p>
</body>
</html>
""";
String json = """
{
"name":"mkyong",
"age":38
}
""";
文本块是作为预览功能引入到 Java 13 中的,这意味着它们不包含在相关的 Java 语言规范中,这样做的好处是方便用户测试功能并提供反馈,后续更新可以根据反馈来改进功能,或者必要时甚至删除该功能,如果该功能立即成为 Java SE 标准的一部分,则进行更改将变得更加困难。重要的是要意识到预览功能不是 beta 形式。
由于预览功能不是规范的一部分,因此有必要为编译和运行时明确启用它们。需要使用下面两个命令行参数来启用预览功能:
清单 8. 启用预览功能
$ javac --enable-preview --release 13 Example.java$ java --enable-preview Example
结束语
Java 在更新发布周期为每半年发布一次之后,在合并关键特性、快速得到开发者反馈等方面,做得越来越好。从 Java 11 到 Java 13,目前确实是严格保持半年更新的节奏。Java 13 版本的发布带来了些新特性和功能增强、性能提升和改进尝试,不过 Java 13 不是 LTS 版本,本文针对其中对使用人员影响重大的以及主要的特性做了介绍,如有兴趣,您可以自行下载相关代码,继续深入研究。
Java 14 特性详解
instanceof 模式匹配(预览阶段)
Java 14 中对 instanceof 的改进,主要目的是为了让创建对象更简单、简洁和高效,并且可读性更强、提高安全性。
在以往实际使用中,instanceof 主要用来检查对象的类型,然后根据类型对目标对象进行类型转换,之后进行不同的处理、实现不同的逻辑,具体可以参考清单 1:
清单 1. instanceof 传统使用方式
if (person instanceof Student) {
Student student = (Student) person;
student.say();
// other student operations
} else if (person instanceof Teacher) {
Teacher teacher = (Teacher) person;
teacher.say();
// other teacher operations
}
上述代码中,我们首先需要对 person 对象进行类型判断,判断 person 具体是 Student 还是 Teacher,因为这两种角色对应不同操作,亦即对应到的实际逻辑实现,判断完 person 类型之后,然后强制对 person 进行类型转换为局部变量,以方便后续执行属于该角色的特定操作。
上面这种写法,有下面两个问题:
- 每次在检查类型之后,都需要强制进行类型转换。
- 类型转换后,需要提前创建一个局部变量来接收转换后的结果,代码显得多余且繁琐。
Java 14 中,对 instanceof 进行模式匹配改进之后,上面示例代码可以改写成:
清单 2. instanceof 模式匹配使用方式
if (person instanceof Student student) {
student.say();
// other student operations
} else if (person instanceof Teacher teacher) {
teacher.say();
// other teacher operations
}
清单 2 中,首先在 if 代码块中,对 person 对象进行类型匹配,校验 person 对象是否为 Student 类型,如果类型匹配成功,则会转换为 Student 类型,并赋值给模式局部变量 student,并且只有当模式匹配表达式匹配成功是才会生效和复制,同时这里的 student 变量只能在 if 块中使用,而不能在 else if/else 中使用,否则会报编译错误。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
注意,如果 if 条件中有 && 运算符时,当 instanceof 类型匹配成功,模式局部变量的作用范围也可以相应延长,如下面代码:
清单 3. Instanceof 模式匹配 && 方式
if (obj instanceof String s && s.length() > 5) {.. s.contains(..) ..}
另外,需要注意,这种作用范围延长,并不适用于或 || 运算符,因为即便 || 运算符左边的 instanceof 类型匹配没有成功也不会造成短路,依旧会执行到||运算符右边的表达式,但是此时,因为 instanceof 类型匹配没有成功,局部变量并未定义赋值,此时使用会产生问题。
与传统写法对比,可以发现模式匹配不但提高了程序的安全性、健壮性,另一方面,不需要显式的去进行二次类型转换,减少了大量不必要的强制类型转换。模式匹配变量在模式匹配成功之后,可以直接使用,同时它还被限制了作用范围,大大提高了程序的简洁性、可读性和安全性。instanceof 的模式匹配,为 Java 带来的有一次便捷的提升,能够剔除一些冗余的代码,写出更加简洁安全的代码,提高码代码效率。
G1 的 NUMA 可识别内存分配
Java 14 改进非一致性内存访问(NUMA)系统上的 G1 垃圾收集器的整体性能,主要是对年轻代的内存分配进行优化,从而提高 CPU 计算过程中内存访问速度。
NUMA 是 non-unified memory access 的缩写,主要是指在当前的多插槽物理计算机体系中,比较普遍是多核的处理器,并且越来越多的具有 NUMA 内存访问体系结构,即内存与每个插槽或内核之间的距离并不相等。同时套接字之间的内存访问具有不同的性能特征,对更远的套接字的访问通常具有更多的时间消耗。这样每个核对于每一块或者某一区域的内存访问速度会随着核和物理内存所在的位置的远近而有不同的时延差异。
Java 中,堆内存分配一般发生在线程运行的时候,当创建了一个新对象时,该线程会触发 G1 去分配一块内存出来,用来存放新创建的对象,在 G1 内存体系中,其实就是一块 region(大对象除外,大对象需要多个 region),在这个分配新内存的过程中,如果支持了 NUMA 感知内存分配,将会优先在与当前线程所绑定的 NUMA 节点空闲内存区域来执行 allocate 操作,同一线程创建的对象,尽可能的保留在年轻代的同一 NUMA 内存节点上,因为是基于同一个线程创建的对象大部分是短存活并且高概率互相调用的。
具体启用方式可以在 JVM 参数后面加上如下参数:
-XX:+UseNUMA
通过这种方式来启用可识别的内存分配方式,能够提高一些大型计算机的 G1 内存分配回收性能。改进 NullPointerExceptions 提示信息
Java 14 改进 NullPointerException 的可查性、可读性,能更准确地定位 null 变量的信息。该特性能够帮助开发者和技术支持人员提高生产力,以及改进各种开发工具和调试工具的质量,能够更加准确、清楚地根据动态异常与程序代码相结合来理解程序。
相信每位开发者在实际编码过程中都遇到过 NullPointerException,每当遇到这种异常的时候,都需要根据打印出来的详细信息来分析、定位出现问题的原因,以在程序代码中规避或解决。例如,假设下面代码出现了一个 NullPointerException:
book.id = 99;
打印出来的 NullPointerException 信息如下:
清单 4. NullPointerException 信息
Exception in thread "main" java.lang.NullPointerException
at Book.main(Book.java:5)
像上面这种异常,因为代码比较简单,并且异常信息中也打印出来了行号信息,开发者可以很快速定位到出现异常位置:book 为空而导致的 NullPointerException,而对于一些复杂或者嵌套的情况下出现 NullPointerException 时,仅根据打印出来的信息,很难判断实际出现问题的位置,具体见下面示例:
shoopingcart.buy.book.id = 99;
对于这种比较复杂的情况下,仅仅单根据异常信息中打印的行号,则比较难判断出现 NullPointerException 的原因。
而 Java 14 中,则做了对 NullPointerException 打印异常信息的改进增强,通过分析程序的字节码信息,能够做到准确的定位到出现 NullPointerException 的变量,并且根据实际源代码打印出详细异常信息,对于上述示例,打印信息如下:
清单 5. NullPointerException 详细信息
Exception in thread "main" java.lang.NullPointerException:
Cannot assign field "book" because "shoopingcart.buy" is null
at Book.main(Book.java:5)
对比可以看出,改进之后的 NullPointerException 信息,能够准确打印出具体哪个变量导致的 NullPointerException,减少了由于仅带行号的异常提示信息带来的困惑。该改进功能可以通过如下参数开启:
-XX:+ShowCodeDetailsInExceptionMessages
该增强改进特性,不仅适用于属性访问,还适用于方法调用、数组访问和赋值等有可能会导致 NullPointerException 的地方。
Record 类型(预览功能)
Java 14 富有建设性地将 Record 类型作为预览特性而引入。Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
在以往开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法,因此在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、Kotlin 中的 data class,但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。对于 Record 类型,具体可以用下面代码来说明:
清单 6. Record 类型定义
public record Person(String name, int age) {
public static String address;
public String getName() {
return name;
}
}
对上述代码进行编译,然后反编译之后可以看到如下结果:
清单 7. Record 类型反编译结果
public final class Person extends java.lang.Record {
private final java.lang.String name;
private final java.lang.String age;
public Person(java.lang.String name, java.lang.String age) { /* compiled code */ }
public java.lang.String getName() { /* compiled code */ }
public java.lang.String toString() { /* compiled code */ }
public final int hashCode() { /* compiled code */ }
public final boolean equals(java.lang.Object o) { /* compiled code */ }
public java.lang.String name() { /* compiled code */ }
public java.lang.String age() { /* compiled code */ }
}
根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征:
- 拥有一个构造方法
- 获取成员属性值的方法:name()、age()
- hashCode() 方法和 euqals() 方法
- toString() 方法
- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被 final 修饰,不能再被赋值使用。
- 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法:
清单 8. Record 新引入至 Class 中的方法
RecordComponent[] getRecordComponents()
boolean isRecord()
其中 getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
而 isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true。
Switch 表达式(正式版)
switch 表达式在之前的 Java 12 和 Java 13 中都是处于预览阶段,而在这次更新的 Java 14 中,终于成为稳定版本,能够正式可用。
switch 表达式带来的不仅仅是编码上的简洁、流畅,也精简了 switch 语句的使用方式,同时也兼容之前的 switch 语句的使用;之前使用 switch 语句时,在每个分支结束之前,往往都需要加上 break 关键字进行分支跳出,以防 switch 语句一直往后执行到整个 switch 语句结束,由此造成一些意想不到的问题。switch 语句一般使用冒号 :来作为语句分支代码的开始,而 switch 表达式则提供了新的分支切换方式,即 -> 符号右则表达式方法体在执行完分支方法之后,自动结束 switch 分支,同时 -> 右则方法块中可以是表达式、代码块或者是手动抛出的异常。以往的 switch 语句写法如下:
清单 9. Switch 语句
int dayOfWeek;
switch (day) {
case MONDAY:
case FRIDAY:
case SUNDAY:
dayOfWeek = 6;
break;
case TUESDAY:
dayOfWeek = 7;
break;
case THURSDAY:
case SATURDAY:
dayOfWeek = 8;
break;
case WEDNESDAY:
dayOfWeek = 9;
break;
default:
dayOfWeek = 0;
break;
}
而现在 Java 14 可以使用 switch 表达式正式版之后,上面语句可以转换为下列写法:
清单 10. Switch 表达式
int dayOfWeek = switch (day) { case MONDAY, FRIDAY, SUNDAY -> 6; case TUESDAY -> 7; case THURSDAY, SATURDAY -> 8;case WEDNESDAY -> 9; default -> 0;};
很明显,switch 表达式将之前 switch 语句从编码方式上简化了不少,但是还是需要注意下面几点:
- 需要保持与之前 switch 语句同样的 case 分支情况。
- 之前需要用变量来接收返回值,而现在直接使用 yield 关键字来返回 case 分支需要返回的结果。
- 现在的 switch 表达式中不再需要显式地使用 return、break 或者 continue 来跳出当前分支。
- 现在不需要像之前一样,在每个分支结束之前加上 break 关键字来结束当前分支,如果不加,则会默认往后执行,直到遇到 break 关键字或者整个 switch 语句结束,在 Java 14 表达式中,表达式默认执行完之后自动跳出,不会继续往后执行。
- 对于多个相同的 case 方法块,可以将 case 条件并列,而不需要像之前一样,通过每个 case 后面故意不加 break 关键字来使用相同方法块。
使用 switch 表达式来替换之前的 switch 语句,确实精简了不少代码,提高了编码效率,同时也可以规避一些可能由于不太经意而出现的意想不到的情况,可见 Java 在提高使用者编码效率、编码体验和简化使用方面一直在不停的努力中,同时也期待未来有更多的类似 lambda、switch 表达式这样的新特性出来。
删除 CMS 垃圾回收器
CMS 是老年代垃圾回收算法,通过标记-清除的方式进行内存回收,在内存回收过程中能够与用户线程并行执行。CMS 回收器可以与 Serial 回收器和 Parallel New 回收器搭配使用,CMS 主要通过并发的方式,适当减少系统的吞吐量以达到追求响应速度的目的,比较适合在追求 GC 速度的服务器上使用。
因为 CMS 回收算法在进行 GC 回收内存过程中是使用并行方式进行的,如果服务器 CPU 核数不多的情况下,进行 CMS 垃圾回收有可能造成比较高的负载。同时在 CMS 并行标记和并行清理时,应用线程还在继续运行,程序在运行过程中自然会创建新对象、释放不用对象,所以在这个过程中,会有新的不可达内存地址产生,而这部分的不可达内存是出现在标记过程结束之后,本轮 CMS 回收无法在周期内将它们回收掉,只能留在下次垃圾回收周期再清理掉。这样的垃圾就叫做浮动垃圾。由于垃圾收集和用户线程是并发执行的,因此 CMS 回收器不能像其他回收器那样进行内存回收,需要预留一些空间用来保存用户新创建的对象。由于 CMS 回收器在老年代中使用标记-清除的内存回收策略,势必会产生内存碎片,内存当碎片过多时,将会给大对象分配带来麻烦,往往会出现老年代还有空间但不能再保存对象的情况。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
所以,早在几年前的 Java 9 中,就已经决定放弃使用 CMS 回收器了,而这次在 Java 14 中,是继之前 Java 9 中放弃使用 CMS 之后,彻底将其禁用,并删除与 CMS 有关的选项,同时清除与 CMS 有关的文档内容,至此曾经辉煌一度的 CMS 回收器,也将成为历史。
当在 Java 14 版本中,通过使用参数:,尝试使用 CMS 时,将会收到下面信息:
Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; support was removed in <version>
ZGC 支持 MacOS 和 Windows 系统(实验阶段)
ZGC 是最初在 Java 11 中引入,同时在后续几个版本中,不断进行改进的一款基于内存 Region,同时使用了内存读屏障、染色指针和内存多重映射等技,并且以可伸缩、低延迟为目标的内存垃圾回收器器,不过在 Java 14 之前版本中,仅仅只支持在 Linux/x64 位平台。
此次 Java 14,同时支持 MacOS 和 Windows 系统,解决了开发人员需要在桌面操作系统中使用 ZGC 的问题。
在 MacOS 和 Windows 下面开启 ZGC 的方式,需要添加如下 JVM 参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
弃用 ParallelScavenge 和 SerialOld GC 的组合使用
由于 Parallel Scavenge 和 Serial Old 垃圾收集算法组合起来使用的情况比较少,并且在年轻代中使用并行算法,而在老年代中使用串行算法,这种并行、串行混搭使用的情况,本身已属罕见同时也很冒险。由于这两 GC 算法组合很少使用,却要花费巨大工作量来进行维护,所以在 Java 14 版本中,考虑将这两 GC 的组合弃用。
具体弃用情况如下,通过弃用组合参数:,来弃用年轻代、老年期中并行、串行混搭使用的情况;同时,对于单独使用参数: 的地方,也将显示该参数已被弃用的警告信息。
文本块(第二预览版本)
Java 13 引入了文本块来解决多行文本的问题,文本块主要以三重双引号开头,并以同样的以三重双引号结尾终止,它们之间的任何内容都被解释为文本块字符串的一部分,包括换行符,避免了对大多数转义序列的需要,并且它仍然是普通的 java.lang.String 对象,文本块可以在 Java 中能够使用字符串的任何地方进行使用,而与编译后的代码没有区别,还增强了 Java 程序中的字符串可读性。并且通过这种方式,可以更直观地表示字符串,可以支持跨越多行,而且不会出现转义的视觉混乱,将可以广泛提高 Java 类程序的可读性和可写性。
Java 14 在 Java 13 引入的文本块的基础之上,新加入了两个转义符,分别是: 和 s,这两个转义符分别表达涵义如下:
- :行终止符,主要用于阻止插入换行符;
- :表示一个空格。可以用来避免末尾的白字符被去掉。
在 Java 13 之前,多行字符串写法为:
清单 11. 多行字符串写法
String literal = "Lorem ipsum dolor sit amet, consectetur adipiscing " +
"elit, sed do eiusmod tempor incididunt ut labore " +
"et dolore magna aliqua.";
在 Java 14 新引入两个转义符之后,上述内容可以写为:
清单 12. 多行文本块加上转义符的写法
String text = """
Lorem ipsum dolor sit amet, consectetur adipiscing
elit, sed do eiusmod tempor incididunt ut labore
et dolore magna aliqua.
""";
上述两种写法,text 实际还是只有一行内容。
对于转义符:,用法如下,能够保证下列文本每行正好都是六个字符长度:
清单 13. 多行文本块加上转义符的写法
String colors = """
red s
greens
blue s
""";
Java 14 带来的这两个转义符,能够简化跨多行字符串编码问题,通过转义符,能够避免对换行等特殊字符串进行转移,从而简化代码编写,同时也增强了使用 String 来表达 HTML、XML、SQL 或 JSON 等格式字符串的编码可读性,且易于维护。
同时 Java 14 还对 String 进行了方法扩展:
- :用于从文本块中去除空白字符
- :用于翻译转义字符
- :用于格式化
结束语
Java 在更新版本周期为每半年发布一次之后,目前来看,确实是严格保持每半年更新的节奏。Java 14 版本的发布带来了不少新特性、功能实用性的增强、性能提升和 GC 方面的改进尝试。本文仅针对其中对使用人员影响较大的以及其中主要的特性做了介绍,如有兴趣,您还可以自行下载相关代码,继续深入研究。
Java 15 特性详解
Edwards-Curve 数字签名算法 (EdDSA)
Edwards-Curve 数字签名算法(EdDSA),一种根据 RFC 8032 规范所描述的 Edwards-Curve 数字签名算法(EdDSA)实现加密签名,实现了一种 RFC 8032 标准化方案,但它不能代替 ECDSA。
与 JDK 中的现有签名方案相比,EdDSA 具有更高的安全性和性能,因此备受关注。它已经在OpenSSL和BoringSSL等加密库中得到支持,在区块链领域用的比较多。
EdDSA是一种现代的椭圆曲线方案,具有JDK中现有签名方案的优点。EdDSA将只在SunEC提供商中实现。
// example: generate a key pair and sign
KeyPairGenerator kpg = KeyPairGenerator.getInstance("Ed25519");
KeyPair kp = kpg.generateKeyPair();
// algorithm is pure Ed25519
Signature sig = Signature.getInstance("Ed25519");
sig.initSign(kp.getPrivate());
sig.update(msg);
byte[] s = sig.sign();
// example: use KeyFactory to contruct a public key
KeyFactory kf = KeyFactory.getInstance("EdDSA");
boolean xOdd = ...
BigInteger y = ...
NamedParameterSpec paramSpec = new NamedParameterSpec("Ed25519");
EdECPublicKeySpec pubSpec = new EdECPublicKeySpec(paramSpec, new EdPoint(xOdd, y));
PublicKey pubKey = kf.generatePublic(pubSpec);
密封的类和接口(预览)
封闭类(预览特性),可以是封闭类和或者封闭接口,用来增强 Java 编程语言,防止其他类或接口扩展或实现它们。
因为我们引入了 或,这些class或者interfaces只允许被指定的类或者interface进行扩展和实现。
使用修饰符,您可以将一个类声明为密封类。密封的类使用reserved关键字permits列出可以直接扩展它的类。子类可以是最终的,非密封的或密封的。
之前我们的代码是这样的。
public class Person { } //人
class Teacher extends Person { }//教师
class Worker extends Person { } //工人
class Student extends Person{ } //学生
但是我们现在要限制 Person类 只能被这三个类继承,不能被其他类继承,需要这么做。
// 添加sealed修饰符,permits后面跟上只能被继承的子类名称
public sealed class Person permits Teacher, Worker, Student{ } //人
// 子类可以被修饰为 final
final class Teacher extends Person { }//教师
// 子类可以被修饰为 non-sealed,此时 Worker类就成了普通类,谁都可以继承它
non-sealed class Worker extends Person { } //工人
// 任何类都可以继承Worker
class AnyClass extends Worker{}
//子类可以被修饰为 sealed,同上
sealed class Student extends Person permits MiddleSchoolStudent,GraduateStudent{ } //学生
final class MiddleSchoolStudent extends Student { } //中学生
final class GraduateStudent extends Student { } //研究生
很强很实用的一个特性,可以限制类的层次结构。
隐藏类
隐藏类是为框架(frameworks)所设计的,隐藏类不能直接被其他类的字节码使用,只能在运行时生成类并通过反射间接使用它们。
该提案通过启用标准 API 来定义 无法发现 且 具有有限生命周期 的隐藏类,从而提高 JVM 上所有语言的效率。JDK内部和外部的框架将能够动态生成类,而这些类可以定义隐藏类。通常来说基于JVM的很多语言都有动态生成类的机制,这样可以提高语言的灵活性和效率。
- 隐藏类天生为框架设计的,在运行时生成内部的class。
- 隐藏类只能通过反射访问,不能直接被其他类的字节码访问。
- 隐藏类可以独立于其他类加载、卸载,这可以减少框架的内存占用。
Hidden Classes是什么呢?
Hidden Classes就是不能直接被其他class的二进制代码使用的class。Hidden Classes主要被一些框架用来生成运行时类,但是这些类不是被用来直接使用的,而是通过反射机制来调用。
比如在JDK8中引入的lambda表达式,JVM并不会在编译的时候将lambda表达式转换成为专门的类,而是在运行时将相应的字节码动态生成相应的类对象。
另外使用动态代理也可以为某些类生成新的动态类。
那么我们希望这些动态生成的类需要具有什么特性呢?
- 不可发现性。因为我们是为某些静态的类动态生成的动态类,所以我们希望把这个动态生成的类看做是静态类的一部分。所以我们不希望除了该静态类之外的其他机制发现。
- 访问控制。我们希望在访问控制静态类的同时,也能控制到动态生成的类。
- 生命周期。动态生成类的生命周期一般都比较短,我们并不需要将其保存和静态类的生命周期一致。
API的支持
所以我们需要一些API来定义无法发现的且具有有限生命周期的隐藏类。这将提高所有基于JVM的语言实现的效率。
比如:
java.lang.reflect.Proxy // 可以定义隐藏类作为实现代理接口的代理类。
java.lang.invoke.StringConcatFactory // 可以生成隐藏类来保存常量连接方法;
java.lang.invoke.LambdaMetaFactory //可以生成隐藏的nestmate类,以容纳访问封闭变量的lambda主体;
普通类是通过调用创建的,而隐藏类是通过调用创建的。这使JVM从提供的字节中派生一个隐藏类,链接该隐藏类,并返回提供对隐藏类的反射访问的查找对象。调用程序可以通过返回的查找对象来获取隐藏类的Class对象。
移除Nashorn JavaScript引擎
移除了 Nashorn JavaScript 脚本引擎、APIs,以及 jjs 工具。这些早在 JDK 11 中就已经被标记为 deprecated 了,JDK 15 被移除就很正常了。
Nashorn引擎是什么?
Nashorn 是 JDK 1.8 引入的一个 JavaScript 脚本引擎,用来取代 Rhino 脚本引擎。Nashorn 是 ECMAScript-262 5.1 的完整实现,增强了 Java 和 JavaScript 的兼容性,并且大大提升了性能。
为什么要移除?
官方的描述是,随着 ECMAScript 脚本语言的结构、API 的改编速度越来越快,维护 Nashorn 太有挑战性了,所以……。
重新实现 DatagramSocket API
重新实现了老的 DatagramSocket API 接口,更改了 java.net.DatagramSocket 和 java.net.MulticastSocket 为更加简单、现代化的底层实现,更易于维护和调试。
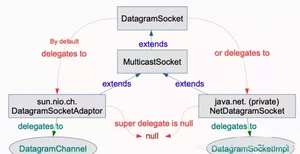
和的当前实现可以追溯到JDK 1.0,那时IPv6还在开发中。因此,当前的多播套接字实现尝试调和IPv4和IPv6难以维护的方式。
- 通过替换 java.net.datagram 的基础实现,重新实现旧版 DatagramSocket API。
- 更改 和 为更加简单、现代化的底层实现。提高了 JDK 的可维护性和稳定性。
- 通过将和 API的底层实现替换为更简单、更现代的实现来重新实现遗留的DatagramSocket API。
新的实现:
- 易于调试和维护;
- 与Project Loom中正在探索的虚拟线程协同。
禁用偏向锁定
准备禁用和废除偏向锁,在 JDK 15 中,默认情况下禁用偏向锁,并弃用所有相关的命令行选项。
在默认情况下禁用偏向锁定,并弃用所有相关命令行选项。目标是确定是否需要继续支持偏置锁定的 高维护成本 的遗留同步优化, HotSpot虚拟机使用该优化来减少非竞争锁定的开销。尽管某些Java应用程序在禁用偏向锁后可能会出现性能下降,但偏向锁的性能提高通常不像以前那么明显。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
该特性默认禁用了,并且废弃了所有相关的命令行选型(, , , , , and )
instanceof 自动匹配模式
模式匹配(第二次预览),第一次预览是 JDK 14 中提出来的。
Java 14 之前:
if (object instanceof Kid) {
Kid kid = (Kid) object;
// ...
} else if (object instanceof Kiddle) {
Kid kid = (Kid) object;
// ...
}
Java 14+:
if (object instanceof Kid kid) {
// ...
} else if (object instanceof Kiddle kiddle) {
// ...
}
Java 15 并没有对此特性进行调整,继续预览特性,只是为了收集更多的用户反馈,可能还不成熟吧。
垃圾回收器ZGC: 可伸缩低延迟垃圾收集器
ZGC是Java 11引入的新的垃圾收集器(JDK9以后默认的垃圾回收器是G1),经过了多个实验阶段,自此终于成为正式特性。ZGC是一个重新设计的并发的垃圾回收器,可以极大的提升GC的性能。支持任意堆大小而保持稳定的低延迟(10ms以内),性能非常可观。目前默认垃圾回收器仍然是 G1,后续很有可以能将ZGC设为默认垃圾回收器。之前需要通过来启用ZGC,现在只需要就可以。
以下是相关介绍:
ZGC 是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colord
- 针以及 Load barriers 优化奠定基础
- 当前只支持 Linux/x64 位平台 停顿时间在 10ms 以下,10ms 其实是一个很保守的数据,即便是 10ms 这个数据,也是 GC 调优几乎达不到的极值。根据 SPECjbb 2015 的基准测试,128G 的大堆下最大停顿时间才 1.68ms,远低于 10ms,和 G1 算法相比,改进非常明显。
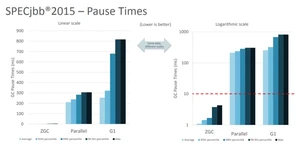
不过目前 ZGC 还处于实验阶段,目前只在 Linux/x64 上可用,如果有足够的需求,将来可能会增加对其他平台的支持。同时作为实验性功能的 ZGC 将不会出现在 JDK 构建中,除非在编译时使用 configure 参数: 显式启用。
在实验阶段,编译完成之后,已经迫不及待的想试试 ZGC,需要配置以下 JVM 参数,才能使用 ZGC,具体启动 ZGC 参数如下:
-XX:+ UnlockExperimentalVMOptions -XX:+ UseZGC -Xmx10g
其中参数:-Xmx 是 ZGC 收集器中最重要的调优选项,大大解决了程序员在 JVM 参数调优上的困扰。ZGC 是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:
- 对象的分配速率,要保证在 GC 的时候,堆中有足够的内存分配新对象。
- 一般来说,给 ZGC 的内存越多越好,但是也不能浪费内存,所以要找到一个平衡。
文本块(Text Blocks)
文本块,是一个多行字符串,它可以避免使用大多数转义符号,自动以可预测的方式格式化字符串,并让开发人员在需要时可以控制格式。
Text Blocks首次是在JDK 13中以预览功能出现的,然后在JDK 14中又预览了一次,终于在JDK 15中被确定下来,可放心使用了。
public static void main(String[] args) {
String query = """
SELECT * from USER
WHERE `id` = 1
ORDER BY `id`, `name`;
""";
System.out.println(query);
}
运行程序,输出(可以看到展示为一行了):
SELECT * from USER WHERE `id` = 1 ORDER BY `id`, `name`;
低暂停时间垃圾收集器 转正
“
Shenandoah垃圾回收算法终于从实验特性转变为产品特性,这是一个从 JDK 12 引入的回收算法,该算法通过与正在运行的 Java 线程同时进行疏散工作来减少 GC 暂停时间。Shenandoah 的暂停时间与堆大小无关,无论堆栈是 200 MB 还是 200 GB,都具有相同的一致暂停时间。
”
怎么形容Shenandoah和ZGC的关系呢?异同点大概如下:
- 相同点:性能几乎可认为是相同的
- 不同点:ZGC是Oracle JDK的。而Shenandoah只存在于OpenJDK中,因此使用时需注意你的JDK版本
- 打开方式:使用命令行参数打开。
Shenandoah在JDK12被作为experimental引入,在JDK15变为Production;之前需要通过来启用,现在只需要即可启用
移除了 Solaris 和 SPARC 端口。
移除了 Solaris/SPARC、Solaris/x64 和 Linux/SPARC 端口的源代码及构建支持。这些端口在 JDK 14 中就已经被标记为 deprecated 了,JDK 15 被移除也不奇怪。
删除对Solaris/SPARC、Solaris/x64和Linux/SPARC端口的源代码和构建支持,在JDK 14中被标记为废弃,在JDK15版本正式移除。许多正在开发的项目和功能(如Valhalla、Loom和Panama)需要进行重大更改以适应CPU架构和操作系统特定代码。
近年来,Solaris 和 SPARC 都已被 Linux 操作系统和英特尔处理器取代。放弃对 Solaris 和 SPARC 端口的支持将使 OpenJDK 社区的贡献者能够加速开发新功能,从而推动平台向前发展。
外部存储器访问 API(孵化器版)
外存访问 API(二次孵化),可以允许 Java 应用程序安全有效地访问 Java 堆之外的外部内存。
目的是引入一个 API,以允许 Java 程序安全、有效地访问 Java 堆之外的外部存储器。如本机、持久和托管堆。
有许多Java程序是访问外部内存的,比如Ignite和MapDB。该API将有助于避免与垃圾收集相关的成本以及与跨进程共享内存以及通过将文件映射到内存来序列化和反序列化内存内容相关的不可预测性 。该Java API目前没有为访问外部内存提供令人满意的解决方案。但是在新的提议中,API不应该破坏JVM的安全性。
Foreign-Memory Access API在JDK14被作为incubating API引入,在JDK15处于Second Incubator,提供了改进。
Records (二次预览)
Records 最早在 JDK 14 中成为预览特性,JDK 15 继续二次预览。
如下内容来自Java14
Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
在以往开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法,因此在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、Kotlin 中的 data class,但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。对于 Record 类型,具体可以用下面代码来说明:
public record Person(String name, int age) {
public static String address;
public String getName() {
return name;
}
}
对上述代码进行编译,然后反编译之后可以看到如下结果:
public final class Person extends java.lang.Record {
private final java.lang.String name;
private final java.lang.String age;
public Person(java.lang.String name, java.lang.String age) { /* compiled code */ }
public java.lang.String getName() { /* compiled code */ }
public java.lang.String toString() { /* compiled code */ }
public final int hashCode() { /* compiled code */ }
public final boolean equals(java.lang.Object o) { /* compiled code */ }
public java.lang.String name() { /* compiled code */ }
public java.lang.String age() { /* compiled code */ }
}
根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征:
- 拥有一个构造方法
- 获取成员属性值的方法:name()、age()
- hashCode() 方法和 euqals() 方法
- toString() 方法
- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被 final 修饰,不能再被赋值使用。
- 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法:
RecordComponent[] getRecordComponents()
boolean isRecord()
其中 getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
而 isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true。
废除 RMI 激活
RMI Activation被标记为Deprecate,将会在未来的版本中删除。RMI激活机制是RMI中一个过时的部分,自Java 8以来一直是可选的而非必选项。RMI激活机制增加了持续的维护负担。RMI的其他部分暂时不会被弃用。
RMI jdk1.2引入,EJB在RMI系统中,我们使用延迟激活。延迟激活将激活对象推迟到客户第一次使用(即第一次方法调用)之前。既然RMI Activation这么好用,为什么要废弃呢?
因为对于现代应用程序来说,分布式系统大部分都是基于Web的,web服务器已经解决了穿越防火墙,过滤请求,身份验证和安全性的问题,并且也提供了很多延迟加载的技术。
所以在现代应用程序中,RMI Activation已经很少被使用到了。并且在各种开源的代码库中,也基本上找不到RMI Activation的使用代码了。为了减少RMI Activation的维护成本,在JDK8中,RMI Activation被置为可选的。现在在JDK15中,终于可以废弃了。
总结
- OracleJDK 15 下载地址:
https://www.oracle.com/java/technologies/javase-downloads.html
- OpenJDK 15 地址:
https://openjdk.java.net/projects/jdk/15/
Java 16 特性详解
与 JDK 15 一样,JDK 16 也将是个短期版本,仅提供 6 个月的支持。预计于 2021 年 9 月发布的 JDK 17 将是一个长期支持(LTS)版本,会获得数年的支持。目前的 LTS 版本 JDK 11 则于 2018 年 9 月发布。
伴随着数千个性能、稳定性和安全性更新,Java 16 为用户提供了十七项主要的增强 / 更改(称为 JDK 增强提案——JEP),包括三个孵化器模块和一个预览特性。
孵化器模块(Incubator Module)中引入了一些增强,这是一种将非最终 API 和非最终工具交给开发人员的方法,该方法允许用户提供反馈,从而改善 Java 平台的质量。
同样,一些增强被作为 Java SE 平台的预览特性、语言或 VM 特性引入,这些增强已完全指定、完全实现但不是永久性的。JDK 特性版本中提供了这些增强,以推动开发人员根据实际使用情况提供反馈,这可能会导致它们在将来的版本中永久保留。这为用户提供了及时反馈的机会,并让工具供应商有机会在大量 Java 开发人员在生产中使用特性之前为其提供支持。
Java 16 随附的 17 个 JEP 分为六个不同类别:
新语言特性
JEP 394,适用于 instanceof 的模式匹配
模式匹配(Pattern Matching)最早在 Java 14 中作为预览特性引入,在 Java 15 中还是预览特性。模式匹配通过对 instacneof 运算符进行模式匹配来增强 Java 编程语言。
模式匹配使程序中的通用逻辑(即从对象中有条件地提取组件)得以更简洁、更安全地表示。
JEP 395,记录
记录(Records)在 Java 14 和 Java 15 中作为预览特性引入。它提供了一种紧凑的语法来声明类,这些类是浅层不可变数据的透明持有者。这将大大简化这些类,并提高代码的可读性和可维护性。
JVM 改进
JEP 376,ZGC 并发线程处理
JEP 376 将 ZGC 线程栈处理从安全点转移到一个并发阶段,甚至在大堆上也允许在毫秒内暂停 GC 安全点。消除 ZGC 垃圾收集器中最后一个延迟源可以极大地提高应用程序的性能和效率。
JEP 387,弹性元空间
此特性可将未使用的 HotSpot 类元数据(即元空间,metaspace)内存更快速地返回到操作系统,从而减少元空间的占用空间。具有大量类加载和卸载活动的应用程序可能会占用大量未使用的空间。新方案将元空间内存按较小的块分配,它将未使用的元空间内存返回给操作系统来提高弹性,从而提高应用程序性能并降低内存占用。
新工具和库
JEP 380,Unix-Domain 套接字通道
Unix-domain 套接字一直是大多数 Unix 平台的一个特性,现在在 Windows 10 和 Windows Server 2019 也提供了支持。此特性为 java.nio.channels 包的套接字通道和服务器套接字通道 API 添加了 Unix-domain(AF_UNIX)套接字支持。它扩展了继承的通道机制以支持 Unix-domain 套接字通道和服务器套接字通道。Unix-domain 套接字用于同一主机上的进程间通信(IPC)。它们在很大程度上类似于 TCP/IP,区别在于套接字是通过文件系统路径名而不是 Internet 协议(IP)地址和端口号寻址的。对于本地进程间通信,Unix-domain 套接字比 TCP/IP 环回连接更安全、更有效。
JEP 392,打包工具
此特性最初是作为 Java 14 中的一个孵化器模块引入的,该工具允许打包自包含的 Java 应用程序。它支持原生打包格式,为最终用户提供自然的安装体验,这些格式包括 Windows 上的 msi 和 exe、macOS 上的 pkg 和 dmg,还有 Linux 上的 deb 和 rpm。它还允许在打包时指定启动时参数,并且可以从命令行直接调用,也可以通过 ToolProvider API 以编程方式调用。注意 jpackage 模块名称从 jdk.incubator.jpackage 更改为 jdk.jpackage。这将改善最终用户在安装应用程序时的体验,并简化了“应用商店”模型的部署。
为未来做好准备
JEP 390,对基于值的类发出警告
此特性将原始包装器类(java.lang.Integer、java.lang.Double 等)指定为基于值的(类似于 java.util.Optional 和 java.time.LocalDateTime),并在其构造器中添加 forRemoval(自 JDK 9 开始被弃用),这样会提示新的警告。在 Java 平台中尝试在任何基于值的类的实例上进行不正确的同步时,它会发出警告。
许多流行的开源项目已经在其源中删除了包装构造器调用来响应 Java 9 的弃用警告,并且鉴于“弃用移除”警告的紧迫性,我们可以期望更多开源项目跟上这一步伐。
JEP 396,默认强封装 JDK 内部元素
此特性会默认强封装 JDK 的所有内部元素,但关键内部 API(例如 sun.misc.Unsafe)除外。默认情况下,使用早期版本成功编译的访问 JDK 内部 API 的代码可能不再起作用。鼓励开发人员从使用内部元素迁移到使用标准 API 的方法上,以便他们及其用户都可以无缝升级到将来的 Java 版本。强封装由 JDK 9 的启动器选项–illegal-access 控制,到 JDK 15 默认改为 warning,从 JDK 16 开始默认为 deny。(目前)仍然可以使用单个命令行选项放宽对所有软件包的封装,将来只有使用–add-opens 打开特定的软件包才行。
孵化器和预览特性
JEP 338,向量 API(孵化器)
该孵化器 API 提供了一个 API 的初始迭代以表达一些向量计算,这些计算在运行时可靠地编译为支持的 CPU 架构上的**向量硬件指令,从而获得优于同等标量计算的性能,充分利用单指令多数据(SIMD)技术(大多数现代 CPU 上都可以使用的一种指令)。尽管 HotSpot 支持自动向量化,但是可转换的标量操作集有限且易受代码更改的影响。该 API 将使开发人员能够轻松地用 Java 编写可移植的高性能向量算法。
JEP 389,外部链接器 API(孵化器)
该孵化器 API 提供了静态类型、纯 Java 访问原生代码的特性,该 API 将大大简化绑定原生库的原本复杂且容易出错的过程。Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。Java 开发人员应该能够为特定任务绑定特定的原生库。它还提供了外来函数支持,而无需任何中间的 JNI 粘合代码。
JEP 393,外部存储器访问 API(第 3 个孵化器)
在 Java 14 和 Java 15 中作为孵化器 API 引入的这个 API 使 Java 程序能够安全有效地对各种外部存储器(例如本机存储器、持久性存储器、托管堆存储器等)进行操作。它提供了外部链接器 API 的基础。
JEP 397,密封类(第二预览)
这个预览特性可以限制哪些类或接口可以扩展或实现它们;它允许类或接口的作者控制负责实现它的代码;它还提供了比访问修饰符更具声明性的方式来限制对超类的使用。它还通过对模式进行详尽的分析来支持模式匹配的未来发展。
提升 OpenJDK 开发人员的生产力
其余更改对 Java 开发人员(使用 Java 编写代码和运行应用程序的人员)不会直接可见,而只对 Java 开发人员(参与 OpenJDK 开发的人员)可见。
JEP 347,启用 C++14 语言特性(在 JDK 源代码中)
它允许在 JDK C++ 源代码中使用 C++14 语言特性,并提供在 HotSpot 代码中可以使用哪些特性的具体指导。在 JDK 15 中,JDK 中 C++ 代码使用的语言特性仅限于 C++98/03 语言标准。它要求更新各种平台编译器的最低可接受版本
JEP 357,从 Mercurial 迁移到 Git;JEP 369,迁移到 GitHub
这些 JEP 将 OpenJDK 社区的源代码存储库从 Mercurial(hg)迁移到 Git,并将它们托管在 GitHub 上以供 JDK 11 及更高版本使用,其中包括将 jcheck、webrev 和 defpath 工具等工具更新到 Git。Git 减小了元数据的大小(约 1/4),可节省本地磁盘空间并减少克隆时间。与 Mercurial 相比,现代工具链可以更好地与 Git 集成。
Open JDK Git 存储库现在位于 https://github.com/openjdk。
JEP 386,AlpineLinux 移植;JEP 388,Windows/AArch64 移植
这些 JEP 的重点不是移植工作本身,而是将它们集成到 JDK 主线存储库中;JEP 386 将 JDK 移植到 Alpine Linux 和其他使用 musl 作为 x64 上主要 C 库的发行版上。此外,JEP 388 将 JDK 移植到 Windows AArch64(ARM64)。
工具链支持
工具链有助于提高开发人员的生产力。目前,对 Java 16 提供支持的 IDE 有 JetBrainsIDEA、EclipseIDE。
甲骨文表示,“我们继续欢迎领先的 IDE 供应商所做的努力,这些供应商的工具链解决方案为开发人员提供了对当前 Java 版本的支持”。
写在最后:
去年,Java 迎来 25 周年。根据 IDC 的最新报告“Java Turns 25”显示,超过 900 万名开发人员(全球专职开发人员中的 69%)在使用 Java——比其他任何语言都多。凭借自身不断提高平台性能、稳定性和安全性的能力,Java 一直是开发人员中最流行的编程语言,被誉为“宇宙第一语言”。
甲骨文在博文写道:
经过二十多年的持续创新,Java 一直在通过适应不断变化的技术格局来保持灵活性,同时维持平台独立性;通过保持向后兼容性来保证可靠性;在不牺牲安全性的前提下加速创新来保持优势。
Java 17 特性详解
Java 开发工具包 (JDK) 17 将是一个长期支持 (LTS) 版本,预计来自 Oracle 的扩展支持将持续数年。该功能集定于 6 月 10 日冻结,届时 JDK 17 将进入初始阶段。作为 OpenJDK JDK 17 的一部分提交的功能包括:
- 特定于上下文的反序列化过滤器允许应用程序通过调用 JVM 范围的过滤器工厂来配置特定于上下文和动态选择的反序列化过滤器,以便为每个序列化操作选择一个过滤器。在解释该提议背后的动机时,Oracle 表示反序列化不受信任的数据是一种固有的危险活动,因为传入数据流的内容决定了创建的对象、其字段的值以及它们之间的引用。在许多用途中,流中的字节是从未知、不受信任或未经身份验证的客户端接收的。通过仔细构建流,攻击者可以导致恶意执行任意类中的代码。如果对象构造具有改变状态或调用其他操作的副作用,则这些操作可能会危及应用程序对象的完整性,库对象和 Java 运行时。禁用序列化攻击的关键是防止任意类的实例被反序列化,从而防止直接或间接执行它们的方法。反序列化过滤器被引入Java 9使应用程序和库代码能够在反序列化之前验证传入的数据流。
代码java.io.ObjectInputFilter在创建反序列化流时提供验证逻辑。但是,依赖流的创建者来明确请求验证有局限性。JDK Enhancement Proposal 290通过引入可通过 API、系统属性或安全属性设置的 JVM 范围的反序列化过滤器解决了这些限制,但这种方法也有局限性,尤其是在复杂的应用程序中。更好的方法是配置每个流过滤器,这样它们就不需要每个流创建者的参与。计划中的增强应帮助开发人员为每个反序列化上下文和用例构建和应用适当的过滤器。
- 随着always-strict 浮点语义,浮点运算将变得始终严格,而不是同时具有严格浮点语义 ( strictfp) 和微妙不同的默认浮点语义。这将原始浮点语义恢复到语言和 VM中,匹配 Java 标准版 1.2 中引入严格和默认浮点模式之前的语义。这项工作的目标包括简化数字敏感库的开发,包括java.lang.Math和java.lang.StrictMath.
改变默认浮点语义的动力来自于原始Java语言和JVM语义之间的不良交互作用,以及流行的x86体系结构的x87浮点协处理器指令集的一些特性。在所有情况下匹配精确的浮点语义,包括非正规操作数和结果,需要大量额外指令的开销。在没有溢出或下溢的情况下匹配结果可以用较少的开销完成,而这正是javase1.2中引入的修改后的默认浮点语义所允许的。但是,大约从2001年开始在奔腾4和更高版本的处理器中发布的SSE2(第二代数据流单指令多数据扩展指令集)扩展可以以一种简单的方式支持严格的JVM浮点操作,而不会产生过多的开销。由于Intel和AMD支持SSE2和更高版本的扩展,这些扩展允许自然地支持严格浮点语义,因此使用不同于strict的默认浮点语义的技术动机已不复存在。
- 弃用安全管理器,准备在未来版本中移除。追溯到 Java 1.0,安全管理器一直是保护客户端 Java 代码的主要手段,很少用于保护服务器端代码。该提案的一个目标是评估是否需要新的 API 或机制来解决使用安全管理器的特定狭窄用例,例如阻塞System::exit。计划要求弃用安全管理器以与旧 Applet API 一起删除,该 API 也计划在 JDK 17 中弃用。
- 模式匹配switch预览版扩展了 Java 中的模式语言,允许switch针对多个模式测试表达式和语句,每个模式都有特定的操作。这使得复杂的面向数据的查询能够简洁而安全地表达。
此功能的目标包括扩展转换表达式和语句允许模式出现在case标签中,减轻了转换如果需要,引入两种模式:guarded patterns允许使用任意布尔表达式对模式匹配逻辑进行优化,以及parenthesized patterns解决了一些解析歧义。
- 如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
在JDK 16,的运算符运算符被扩展为获取类型模式并执行模式匹配。提议的适度扩展允许简化熟悉的instanceof和cast习惯用法。
- JDK 内部的强封装,除了关键的内部 API,如sun.misc.Unsafe,将不再可能通过单个命令行选项放松内部元素的强封装,这在 JDK 9 到 JDK 16 中是可行的。计划包括提高 JDK 的安全性和可维护性,并鼓励开发人员从内部元素迁移到标准 API。
- 删除远程方法调用 (RMI) 激活机制,同时保留 RMI 的其余部分。RMI 激活机制已过时和废弃,在JDK 15 中不推荐使用。
- 在外部函数和内存API引入了一个孵化器阶段,允许 Java 程序与 Java 运行时之外的代码和数据进行互操作。通过高效调用外部函数,即 JVM 之外的代码,安全访问外部内存,即非 JVM 管理的内存,API 使 Java 程序能够调用本地库和处理本地数据,而没有JNI(Java本机接口)的脆弱性和风险。
-
- 提议的 API 是两个 API 的演变:外部内存访问 API 和外部链接器 API。
- 外部内存访问 API 在 2019 年作为孵化 API 面向 Java 14,并在 Java 15 和 Java 16 中重新孵化。外部链接器 API 在 2020 年末面向 Java 16 作为孵化 API。API 计划的目标包括易用性、性能、通用性和安全性。
- 与平台无关的矢量 API作为孵化 API集成到JDK 16中,将在 JDK 17 中再次孵化,提供一种机制来表达矢量计算,这些计算在运行时可靠地编译为支持的 CPU 架构上的**矢量指令。这比等效的标量计算获得了更好的性能。在 JDK 17 中,向量 API 已针对性能和实现进行了增强,包括在字节向量与布尔数组之间进行转换的增强功能。
- 密封类和接口限制哪些其他类或接口可以扩展或实现它们。该提案的目标包括允许类或接口的作者控制由哪些代码负责实现它,提供一种比访问修饰符更具声明性的方式来限制超类的使用,并通过为模式的详尽分析提供基础来支持模式匹配的未来方向。
- 删除实验性 AOT 和 JIT 编译器,它们几乎没有使用,但需要大量维护工作。该计划要求维护 Java 级别的 JVM 编译器接口,以便开发人员可以继续使用外部构建的编译器版本进行 JIT 编译。AOT 编译(jaotc 工具)作为一个实验性特性被整合到JDK 9,它本身是用 Java 编写的,用于 AOT 编译。这些实验性功能未包含在JDK 16 中由 Oracle 发布的版本,没有人抱怨。根据规定的计划,将删除三个 JDK 模块:jdk.aot(jaotc 工具);internal.vm.compiler,Graal 编译器;和 jdk.internal.vm.compiler.management,Graal MBean。与 AOT 编译相关的 HotSpot 代码也将被删除。
- 将 JDK 移植到 MacOS/AArch64以响应Apple 将其 Macintosh 计算机从 x64 转换到 AArch64 的计划。适用于 Linux 的 Java 的 AArch64 端口已经存在,并且 Windows 的工作正在进行中。Java 构建者希望通过使用条件编译来重用来自这些端口的现有 AArch64 代码,这是 JDK 端口中的规范,以适应低级约定的差异,例如应用程序二进制接口和一组保留的处理器寄存器。MacOS/AArch64 的更改可能会破坏现有的 Linux/AArch64、Windows/AArch64 和 MacOS/x64 端口,但通过预集成测试将降低风险。
- 弃用 Applet API 以进行删除。这个 API 本质上是无关紧要的,因为所有 Web 浏览器供应商要么已经取消了对 Java 浏览器插件的支持,要么已经宣布了这样做的计划。Applet API 之前在 2017 年 9 月的java中已被弃用,但并未删除。
- 用于 MacOS 的新渲染管道,使用 Apple Metal API 作为使用已弃用 OpenGL API 的现有管道的替代方案。该提案旨在为使用 MacOS Metal 框架的 Java 2D API 提供功能齐全的渲染管道,并在 Apple 从未来版本的 MacOS 中删除 OpenGL API 时做好准备。该管道旨在与现有的 OpenGL 管道具有同等功能,在选定的应用程序和基准测试中具有相同或更好的性能。将创建适合当前 Java 2D 模型的干净架构。管道将与 OpenGL 管道共存直到过时。添加任何新的 Java 或 JDK API 并不是提案的目标。
- 增强的伪随机数生成器将为伪随机数生成器 (PRNG) 提供新的接口类型和实现,包括可跳转的 PRNG 和额外的一类可拆分 PRNG 算法 (LXM)。新接口RandomGenerator将为所有现有的和新的 PRNG 提供统一的 API。将提供四个专门的 RandomGenerator 接口。推动该计划的重点是 Java 伪随机数生成领域的多个改进领域。这项工作不需要提供许多其他 PRNG 算法的实现。但是已经添加了三种常用算法,这些算法已经广泛部署在其他编程语言环境中。该计划的目标包括:
- 使在应用程序中交替使用各种 PRNG 算法变得更容易。
- 改进了对基于流的编程的支持,提供了 PRNG 对象流。
- 消除现有 PRNG 类中的代码重复。
- 保留类的现有行为java.util.Random。
9 月 14 日已被定为 JDK 17 的全面可用日期。生产版本之前将在 6 月和 7 月进行斜降阶段,并在 8 月发布候选版本。JDK 17 的早期访问开源版本可以在jdk.java.net上找到。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/25921.html