
点击「关注」公众号,回复“1024”获取2TB学习资源!
什么是Java
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程 。
诞生背景

任职于Sun公司(Stanford University Network斯坦福网络公司)的詹姆斯·高斯林和麦克·舍林丹等人于1990年代初开发Java语言的雏形,最初被命名为Oak,Oak的目标是作为家用电器等小型系统的编程语言,用于电视机、电话、闹钟、烤面包机等家用电器的控制和通信。由于这些智能化家电的市场需求没有预期的高,Sun公司放弃了该项计划。随着1990年代互联网的发展,Sun公司发现Oak在互联网上应用的前景,于是改造了Oak,于1995年5月以Java的名称正式发布。伴随着互联网的迅猛发展,Java逐渐成为重要的网络编程语言。
三大版本
Java SE(J2SE,Java 2 Platform Standard Edition,标准版)
Java SE 以前称为 J2SE。它允许开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的 Java 应用程序。Java SE 包含了支持 Java Web 服务开发的类,并为Java EE和Java ME提供基础。
Java EE(J2EE,Java 2 Platform Enterprise Edition,企业版)
Java EE 以前称为 J2EE。企业版本帮助开发和部署可移植、健壮、可伸缩且安全的服务器端Java 应用程序。Java EE 是在 Java SE 的基础上构建的,它提供 Web 服务、组件模型、管理和通信 API,可以用来实现企业级的面向服务体系结构(service-oriented architecture,SOA)和 Web2.0应用程序。2018年2月,Eclipse 宣布正式将 JavaEE 更名为 JakartaEE
Java ME(J2ME,Java 2 Platform Micro Edition,微型版)
Java ME 以前称为 J2ME。Java ME 为在移动设备和嵌入式设备(比如手机、PDA、电视机顶盒和打印机)上运行的应用程序提供一个健壮且灵活的环境。Java ME 包括灵活的用户界面、健壮的安全模型、许多内置的网络协议以及对可以动态下载的连网和离线应用程序的丰富支持。基于 Java ME 规范的应用程序只需编写一次,就可以用于许多设备,而且可以利用每个设备的本机功能。
语言特点与应用场景
Java语言具有简单性、面向对象、分布式、健壮性、安全性、跨平台性、可移植性、多线程与动态性等特点。Java语言可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统等 。Java 快速、安全、可靠。从笔记本电脑到数据中心,从游戏控制台到超级计算机,从手机到互联网,Java 无处不在!
Java技术体系
下图为Oracle官网提供的Java技术体系图
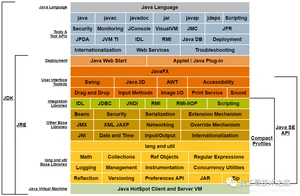
JVM、JRE和JDK的关系
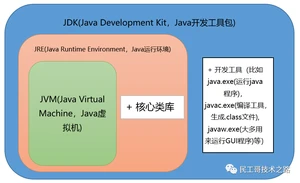
JVM
Java Virtual Machine是Java虚拟机,Java程序需要运行在虚拟机上,不同的平台有自己的虚拟机,因此Java语言可以实现跨平台。
JRE
Java Runtime Environment包括Java虚拟机和Java程序所需的核心类库等。核心类库主要是java.lang包:包含了运行Java程序必不可少的系统类,如基本数据类型、基本数学函数、字符串处理、线程、异常处理类等,系统缺省加载这个包
如果想要运行一个开发好的Java程序,计算机中只需要安装JRE即可。
JDK
Java Development Kit是提供给Java开发人员使用的,其中包含了Java的开发工具,也包括了JRE。所以安装了JDK,就无需再单独安装JRE了。其中的开发工具:编译工具(javac.exe),打包工具(jar.exe)等
JVM&JRE&JDK关系图
Properties 类简介
概述
Properties 继承于 Hashtable。表示一个持久的属性集,属性列表以key-value的形式存在,key和value都是字符串。
Java中有个比较重要的类Properties(Java.util.Properties),主要用于读取Java的配置文件,各种语言都有自己所支持的配置文件,配置文件中很多变量是经常改变的,这样做也是为了方便用户,让用户能够脱离程序本身去修改相关的变量设置。像Python支持的配置文件是.ini文件,同样,它也有自己读取配置文件的类ConfigParse,方便程序员或用户通过该类的方法来修改.ini配置文件。在Java中,其配置文件常为.properties文件,格式为文本文件,文件的内容的格式是“键=值”的格式,文本注释信息可以用"#"来注释。
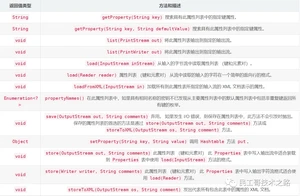
常用方法
除了从Hashtable中所定义的方法,Properties定义了以下方法:

常用方法实践
下面我们从写入、读取、遍历等角度来解析Properties类的常见用法
项目路径如下
PropertiesTest为测试类,prop.properties文件的内容如下
写入
Properties类调用setProperty方法将键值对保存到内存中,此时可以通过getProperty方法读取,propertyNames方法进行遍历,但是并没有将键值对持久化到属性文件中,故需要调用store方法持久化键值对到属性文件中。
输出结果,在resources目录下多一个文件config.properties,内容如下
读取
下面给出常见的六种读取properties文件的方式:
输出结果都是
其中第一、四、五、六种方式都是先获得文件的输入流,然后通过Properties类的load(InputStream inStream)方法加载到Properties对象中,最后通过Properties对象来操作文件内容。
第二、三中方式是通过ResourceBundle类来加载Properties文件,然后ResourceBundle对象来操做properties文件内容。
其中最重要的就是每种方式加载文件时,文件的路径需要按照方法的定义的格式来加载,否则会抛出各种异常,比如空指针异常。
遍历
下面给出四种遍历Properties中的所有键值对的方法:
什么是面向对象
面向对象(OOP)概述
举个最简单点的例子来区分面向过程和面向对象
有一天你想吃鱼香肉丝了,怎么办呢?你有两个选择
1、自己买材料,肉,鱼香肉丝调料,蒜苔,胡萝卜等等然后切菜切肉,开炒,盛到盘子里。
2、去饭店,张开嘴:老板!来一份鱼香肉丝!
看出来区别了吗?1是面向过程,2是面向对象。
面向对象有什么优势呢?首先你不需要知道鱼香肉丝是怎么做的,降低了耦合性。如果你突然不想吃鱼香肉丝了,想吃洛阳白菜,对于1你可能不太容易了,还需要重新买菜,买调料什么的。对于2,太容易了,大喊:老板!那个鱼香肉丝换成洛阳白菜吧,提高了可维护性。总的来说就是降低耦合,提高维护性!
面向过程是具体化的,流程化的,解决一个问题,你需要一步一步的分析,一步一步的实现。
面向对象是模型化的,你只需抽象出一个类,这是一个封闭的盒子,在这里你拥有数据也拥有解决问题的方法。需要什么功能直接使用就可以了,不必去一步一步的实现,至于这个功能是如何实现的,管我们什么事?我们会用就可以了。
面向对象的底层其实还是面向过程,把面向过程抽象成类,然后封装,方便我们使用的就是面向对象了。
面向过程和面向对象的区别
面向过程
优点:性能比面向对象好,因为类调用时需要实例化,开销比较大,比较消耗资源。
缺点:不易维护、不易复用、不易扩展
面向对象
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护
缺点:性能比面向过程差
面向对象三大特性五大原则

面向对象的三大特性
1、封装
隐藏对象的属性和实现细节,仅对外提供公共访问方式,将变化隔离,便于使用,提高复用性和安全性。
2、继承
提高代码复用性;继承是多态的前提。
3、多态
父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。提高了程序的拓展性。
五大基本原则
单一职责原则SRP(Single Responsibility Principle)类的功能要单一,不能包罗万象,跟杂货铺似的。
开放封闭原则OCP(Open-Close Principle)一个模块对于拓展是开放的,对于修改是封闭的,想要增加功能热烈欢迎,想要修改,哼,一万个不乐意。
里式替换原则LSP(the Liskov Substitution Principle LSP)子类可以替换父类出现在父类能够出现的任何地方。比如你能代表你爸去你姥姥家干活。哈哈~~
依赖倒置原则DIP(the Dependency Inversion Principle DIP)高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。就是你出国要说你是中国人,而不能说你是哪个村子的。比如说中国人是抽象的,下面有具体的xx省,xx市,xx县。你要依赖的抽象是中国人,而不是你是xx村的。
接口分离原则ISP(the Interface Segregation Principle ISP)设计时采用多个与特定客户类有关的接口比采用一个通用的接口要好。就比如一个手机拥有打电话,看视频,玩游戏等功能,把这几个功能拆分成不同的接口,比在一个接口里要好的多。
总结
抽象会使复杂的问题更加简单化。
从以前面向过程的执行者,变成了张张嘴的指挥者。
面向对象更符合人类的思维,面向过程则是机器的思想
YML简介
YML是什么
YAML (YAML Aint Markup Language)是一种标记语言,通常以.yml或者.yaml为后缀的文件,是一种直观的能够被电脑识别的数据序列化格式,并且容易被人类阅读,容易和脚本语言交互的,可以被支持YAML库的不同的编程语言程序导入,一种专门用来写配置文件的语言。可用于如:Java,C/C++, Ruby, Python, Perl, C#, PHP等。
YML的优点
YAML易于人们阅读。
YAML数据在编程语言之间是可移植的。
YAML匹配敏捷语言的本机数据结构。
YAML具有一致的模型来支持通用工具。
YAML支持单程处理。
YAML具有表现力和可扩展性。
YAML易于实现和使用。
YML语法
1.约定
k: v 表示键值对关系,冒号后面必须有一个空格
使用空格的缩进表示层级关系,空格数目不重要,只要是左对齐的一列数据,都是同一个层级的
大小写敏感
缩进时不允许使用Tab键,只允许使用空格。
松散表示,Java中对于驼峰命名法,可用原名或使用-代替驼峰,如java中的lastName属性,在yml中使用lastName或 last-name都可正确映射。
2.键值关系
(以Java语言为例,其它语言类似)对于键与值主要是看能否表示以下内容。普通的值(数字、字符串、布尔)、日期、对象、数组、集合等。
1)普通值(字面量)
k: v:字面量直接写;
字符串默认不用加上单引号或者双绰号;
“”: 双引号;不会转义字符串里面的特殊字符;特殊字符会作为本身想表示的意思
name: “zhangsan lisi”:输出;zhangsan 换行 lisi
‘’:单引号;会转义特殊字符,特殊字符最终只是一个普通的字符串数据
2)日期
3)对象(属性和值)、Map(键值对)
在下一行来写对象的属性和值的关系,注意缩进
行内写法:
4)数组、list、set
用- 值表示数组中的一个元素
行内写法
5)数组对象、list对象、set对象
6)Java代码示例
Java代码(省略get,set方法)
对应的yml
3.文档块
对于测试环境,预生产环境,生产环境可以使用不同的配置,如果只想写到一个文件中,yml与是支持的,每个块用----隔开
JSON简介
概述
JSON(JavaScript Object Notation JavaScript 对象表示法)是一种轻量级的数据交换格式,它基于JavaScript的一个子集,易于人的编写和阅读,也易于机器解析。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。这些特性使JSON成为理想的数据交换语言。
结构组成
JSON由两种结构组成:
键值对的无序集合——对象(或者叫记录、结构、字典、哈希表、有键列表或关联数组等)
值的有序列表——数组
这些都是常见的数据结构。事实上大部分现代计算机语言都以某种形式支持它们。这使得一种数据格式在同样基于这些结构的编程语言之间交换成为可能。
语法规则
数据在名称/值对中
数据由逗号分隔
大括号保存对象
中括号保存数组
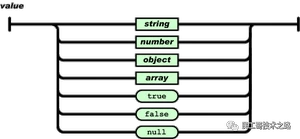
JSON的形式
对象
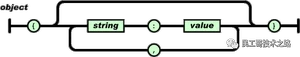
数组
值(value)的有序集合。一个数组以“[”(左中括号)开始,“]”(右中括号)结束。值之间使用“,”(逗号)分隔。
举例

值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array)。这些结构可以嵌套。
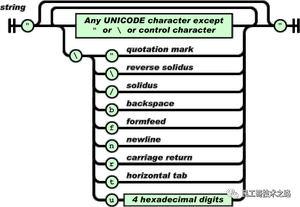
字符串(string)是由双引号包围的任意数量Unicode字符的集合,使用反斜线转义。一个字符(character)即一个单独的字符串(character string)。
字符串(string)与C或者Java的字符串非常相似。
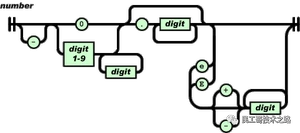
数值(number)也与C或者Java的数值非常相似。除去未曾使用的八进制与十六进制格式。除去一些编码细节。
空白可以加入到任何符号之间。
这里举例一个比较复杂的json
具体参见JSON官网http://www.json.org/json-zh.html
XML简介
什么是 XML
XML 是可扩展标记语言(EXtensible Markup Language)。
XML 是一种很像HTML的标记语言。
XML 的设计宗旨是传输数据,而不是显示数据。
XML 标签没有被预定义。您需要自行定义标签。
XML 被设计为具有自我描述性。
XML 是 W3C 的推荐标准。
XML 用途
XML 应用于 Web 开发的许多方面,常用于简化数据的存储和传输。
存放数据栗子
配置文件栗子
XML 语法
XML文件主要由XML文档声明,元素,属性,注释,转义字符,CDATA区,处理指令组成。
XML文档声明
文档声明必须为结束;
文档声明必须从文档的0行0列位置开始;
文档声明只有三个属性:
versioin:指定XML文档版本。必须属性,因为我们不会选择1.1,只会选择1.0;
encoding:指定当前文档的编码。可选属性,默认值是utf-8;
standalone:指定文档独立性。可选属性,默认值为yes,表示当前文档是独立文档。如果为no表示当前文档不是独立的文档,会依赖外部文件。
元素
元素是XML文档中最重要的组成部分,
普通元素的结构开始标签、元素体、结束标签组成。例如:大家好
元素体:元素体可以是元素,也可以是文本,例如:你好
空元素:空元素只有开始标签,而没有结束标签,但元素必须自己闭合,例如:
元素命名:
a) 区分大小写
b) 不能使用空格,不能使用冒号:
c) 不建议以XML、xml、Xml开头
良好的XML文档,必须有一个根元素。
属性
属性是元素的一部分,它必须出现在元素的开始标签中
属性的定义格式:属性名=属性值,其中属性值必须使用单引或双引
一个元素可以有0~N个属性,但一个元素中不能出现同名属性
属性名不能使用空格、冒号等特殊字符,且必须以字母开头
注释
XML 文件中注释采用:" " 这样的格式
XML 声明之前不能有注释
注释不能嵌套,比如下面不合规范:
转义字符
XML中的转义字符与HTML一样。
因为很多符号已经被XML文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用转义字符,例如:。

CDATA区
当大量的转义字符出现在xml文档中时,会使xml文档的可读性大幅度降低。这时如果使用CDATA段就会好一些。
在CDATA段中出现的,都无需使用转义字符。这可以提高xml文档的可读性。
在CDATA段中不能包含,即CDATA段的结束定界符。
处理指令
用来解析引擎如何解析 XML 文档内容
比如:在 XML 文档中可以使用 xml-stylesheet 指令,通知 XML 解析引擎,应用 CSS 文件显示 XML 文档内容
处理指令必须以结尾
XML的解析
开发中比较常见的解析方式有三种
DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象。
a) 优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
b) 缺点:XML文档过大,可能出现内存溢出显现。
SAX:是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都将触发对应的事件。(了解)
a) 优点:处理速度快,可以处理大文件
b) 缺点:只能读,逐行后将释放资源。
PULL:Android内置的XML解析方式,类似SAX。(了解)
解析器
根据不同的解析方式提供的具体实现。有的解析器操作过于繁琐,为了方便开发人员,有提供易于操作的解析开发包。
常见的解析开发包
JAXP:sun公司提供支持DOM和SAX开发包
JDom:dom4j兄弟
jsoup:一种处理HTML特定解析开发包
dom4j:比较常用的解析开发包,hibernate底层采用。
DOM解析原理及结构模型
XML DOM 和 HTML DOM类似,XML DOM 将 整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM进行操作
DOM中的核心概念就是节点,在XML文档中的元素、属性、文本等,在DOM中都是节点!
dom4j技术栗子
引入dom4j依赖
将xml文件放到指定位置,这里放的是XML 用途配置文件栗子的内容,然后读取这个位置的xml文件,测试代码如下
输出结果
XML的约束
作用
规定xml中可以出现哪些元素及哪些属性,以及他们出现的顺序
约束的分类
DTD约束:struts hiebernate等等(会用到)
SCHEMA约束:tomcat spring等等(会用到)
约束详解
既然是约束就和xml有联系,所以约束要和xml关联,xml的相关限制才能生效。
方式1:内部关联
方式2:外部关联-系统关联
举例web-app_2_3.dtd文件
接下来xml中只能出现dtd文件中规定的特有的标签了(不能自定义自己随便写了)
ps:idea中你输入< 便会提示能够输入的标签
方式3:外部关联-公共关联
dtd约束
无论是单独的dtd文件还是写在xml中(参考上面方式一)都需要按照语法要求写
再次强调下语dtd文件约束的作用:
规定xml中可以出现哪些元素及哪些属性,以及他们出现的顺序
注意:一个xml文档中只能添加一个DTD约束
schema约束
一个xml文档中可以添加多个schema约束
如下一个xml scheam的约束文档,我们创建xml时如果有相应的约束 直接引进约束就行。
Java注解
为什么要引入注解?
使用【注解】之前(甚至在使用之后),【XML】被广泛的应用于描述元数据,得到各大框架的青睐,它以松耦合的方式完成了框架中几乎所有的配置,但是随着项目越来越庞大,【XML】的内容也越来越复杂,一些应用开发人员和架构师发现维护成本变高。他们希望使用一些和代码紧耦合的东西,于是就有人提出来一种标记式高耦合的配置方式【注解】。方法上可以进行注解,类上也可以注解,字段属性上也可以注解,反正几乎需要配置的地方都可以进行注解。
下面我们通过一个例子来理解这两者的区别。
假如你想为应用设置很多的常量或参数,这种情况下,【XML】是一个很好的选择,因为它不会同特定的代码耦合。如果你想把某个方法声明为服务,那么使用【注解】会更好一些,因为这种情况下需要注解和方法紧密耦合起来,开发人员也必须认识到这点。
同时,【注解】定义了一种标准的描述元数据的方式。
关于【注解】和【XML】两种不同的配置模式,争论了好多年,各有各的优劣,注解可以提供更大的便捷性,易于维护修改,但耦合度高,而 【XML】 相对于注解则是相反的。追求低耦合就要抛弃高效率,追求效率必然会遇到耦合。目前,许多框架将【XML】和【注解】两种方式结合使用,平衡两者之间的利弊。
本文不再辨析两者谁优谁劣,而在于以最简单的语言介绍注解相关的基本知识。
什么是注解
注解也叫元数据,即一种描述数据的数据。例如我们常见的@Override和@Deprecated,注解是JDK1.5版本开始引入的一个特性,用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解
Annotation接口中有下面这句话来描述注解:Annotation 是所有注解继承的公共接口
注解的本质就是一个继承了 Annotation 接口的接口。有关这一点,你可以去反编译任意一个注解类得到结果。
一个注解准确意义上来说,只不过是一种特殊的注释而已,如果没有解析它的代码,它可能连注释都不如。
而解析一个类或者方法的注解往往有两种形式,一种是编译期直接的扫描,一种是运行期反射。反射的事情我们先不讨论,而编译器的扫描指的是编译器在对 e会学java语言程序设计基础 Java 代码编译成字节码的过程中会检测到某个类或者方法被一些注解修饰,这时它就会对于这些注解进行某些处理。
上面的代码中,我重写了toString()方法并使用了@Override注解。但是,即使我不使用@Override注解标记代码,程序也能够正常执行。那么,该注解表示什么?这么写有什么好处吗?事实上,@Override告诉编译器这个方法是一个重写方法(描述方法的元数据),如果父类中不存在该方法,编译器便会报错,提示该方法没有重写父类中的方法。如果我不小心拼写错误,例如将toString()写成了toStrring(),而且我也没有使用@Override注解,那程序依然能编译运行。但运行结果会和我期望的大不相同。现在我们了解了什么是注解,并且使用注解有助于提高代码的可读性。
注解的用途
生成文档,通过代码里标识的元数据生成javadoc文档。
编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例
注解的分类
Java自带的标准注解,包括@Override(标明重写某个方法)、@Deprecated(标明某个类或方法过时)和@SuppressWarnings(标明要忽略的警告),使用这些注解后编译器就会进行检查
元注解,元注解是用于定义注解的注解,包括@Retention(标明注解被保留的阶段)、@Target(标明注解使用的范围)、@Inherited(标明注解可继承)、@Documented(标明是否生成javadoc文档)
自定义注解,可以根据自己的需求定义注解
元注解
要想真正掌握怎么使用注解,还需要先学习一下元注解。
元注解是用于修饰注解的注解
元注解有 @Retention、@Documented、@Target、@Inherited、@Repeatable 5 种。
@Retention
Retention 的英文意为保留期的意思。当 @Retention 应用到一个注解上的时候,它解释说明了这个注解的的存活时间。
它的取值如下:
RetentionPolicy.SOURCE 注解只在源码阶段保留,在编译器进行编译时它将被丢弃忽视。
RetentionPolicy.CLASS 注解只被保留到编译进行的时候,它并不会被加载到 JVM 中。如Java内置注解,@Override、@Deprecated、@SuppressWarnning等
RetentionPolicy.RUNTIME 注解可以保留到程序运行的时候,它会被加载进入到 JVM 中,所以在程序运行时可以获取到它们。如SpringMvc中的@Controller、@Autowired、@RequestMapping等。
@Documented
顾名思义,这个元注解肯定是和文档有关。它的作用是能够将注解中的元素包含到 Javadoc 中去。
@Target
Target 是目标的意思,@Target 指定了注解运用的地方。
你可以这样理解,当一个注解被 @Target 注解时,这个注解就被限定了运用的场景。
类比到标签,原本标签是你想张贴到哪个地方就到哪个地方,但是因为 @Target 的存在,它张贴的地方就非常具体了,比如只能张贴到方法上、类上、方法参数上等等。@Target 有下面的取值
ElementType.ANNOTATION_TYPE 可以给一个注解进行注解
ElementType.CONSTRUCTOR 可以给构造方法进行注解
ElementType.FIELD 可以给属性进行注解
ElementType.LOCAL_VARIABLE 可以给局部变量进行注解
ElementType.METHOD 可以给方法进行注解
ElementType.PACKAGE 可以给一个包进行注解
ElementType.PARAMETER 可以给一个方法内的参数进行注解
ElementType.TYPE 可以给一个类型进行注解,比如类、接口、枚举
@Inherited
Inherited 是继承的意思,但是它并不是说注解本身可以继承,而是说如果一个超类使用了@Inherited 注解,那么如果它的子类没有被任何注解应用的话,那么这个子类就继承了超类的注解。
说的比较抽象。代码来解释。
@Repeatable
Repeatable 自然是可重复的意思。@Repeatable 是 Java 1.8 才加进来的,所以算是一个新的特性。
Repeatable使用场景:在需要对同一种注解多次使用时,往往需要借助@Repeatable。
下面举例说明一下,在生活中一个人往往是具有多种身份,如果我把每种身份当成一种注解该如何使用
先声明一个Persons类用来包含所有的身份
这里@Target是声明Persons注解的作用范围,参数ElementType.Type代表可以给一个类进行注解
@Retention是注解的有效时间,RetentionPolicy.RUNTIME是指程序运行的时候。
Person注解
@Repeatable括号内的就相当于用来保存该注解内容的容器。
声明一个Man类,给该类加上一些身份。
在主方法中访问该注解。
运行结果
注解的属性
注解的属性也叫做成员变量。注解只有成员变量,没有方法。注解的成员变量在注解的定义中以“无形参的方法”形式来声明,其方法名定义了该成员变量的名字,其返回值定义了该成员变量的类型。
上面代码定义了 @TestAnnotation 这个注解中拥有 id 和 msg 两个属性。在使用的时候,我们应该给它们进行赋值。
赋值的方式是在注解的括号内以 value="" 形式,多个属性之前用 ,隔开。
快捷方式
所谓的快捷方式就是注解中定义了名为value的元素,并且在使用该注解时,如果该元素是唯一需要赋值的一个元素,那么此时无需使用key=value的语法,而只需在括号内给出value元素所需的值即可。这可以应用于任何合法类型的元素,记住,这限制了元素名必须为value,简单案例如下
注解不支持继承
注解是不支持继承的,因此不能使用关键字extends来继承某个@interface,但注解在编译后,编译器会自动继承java.lang.annotation.Annotation接口
声明注解
这里总共定义了4个注解来演示注解的声明
定义一个可以注解在Class,interface,enum上的注解
定义一个可以注解在METHOD上的注解
定义一个可以注解在FIELD上的注解
定义一个可以注解在PARAMETER上的注解
编写一个测试处理类处理以上注解
输出结果
Java预置的注解
学习了上面相关的知识,我们已经可以自己定义一个注解了。其实 Java 语言本身已经提供了几个现成的注解。
@Deprecated
这个元素是用来标记过时的元素,想必大家在日常开发中经常碰到。编译器在编译阶段遇到这个注解时会发出提醒警告,告诉开发者正在调用一个过时的元素比如过时的方法、过时的类、过时的成员变量。
@Override
这个大家应该很熟悉了,用于标明此方法覆盖了父类的方法。
@SuppressWarnings
用于有选择的关闭编译器对类、方法、成员变量、变量初始化的警告。之前说过调用被 @Deprecated 注解的方法后,编译器会警告提醒,而有时候开发者会忽略这种警告,他们可以在调用的地方通过 @SuppressWarnings 达到目的。
@SafeVarargs
参数安全类型注解。它的目的是提醒开发者不要用参数做一些不安全的操作,它的存在会阻止编译器产生 unchecked 这样的警告。它是在 Java 1.7 的版本中加入的。
@FunctionalInterface
函数式接口注解,这个是 Java 1.8 版本引入的新特性。函数式编程很火,所以 Java 8 也及时添加了这个特性。
函数式接口 (Functional Interface) 就是一个具有一个方法的普通接口。
我们进行线程开发中常用的 Runnable 就是一个典型的函数式接口,从源码可以看到它使用了@FunctionalInterface 注解。
注解应用实例
注解的功能很强大,Spring和Hebernate这些框架在日志和有效性中大量使用了注解功能。
注解通常配合反射或者切面一起使用来实现相应的业务逻辑。
我这里向大家演示使用注解和切面进行日志记录的案例
定义一个系统日志注解
找到使用了注解的方法,利用切面进行日志记录
这里有些类或者参数只做演示,没有给出具体的实现(如SysLogMapper、SysLogEntity等),以看懂注解配合切面使用为目的
在方法中使用注解
总结
本文首先讲述了为什么要引入注解,注解是什么,注解的用途和分类,了解什么是元注解,怎么自定义注解,最后演示了使用注解和切面进行日志记录的案例。本人知识水平有限,只进行了Java注解的简单介绍,如有不正确的地方还请大神指教,希望对注解有更深入的了解掌握的话,可以自行进行更深入的学习。
Java反射
定义
Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性。这种动态获取信息以及动态调用对象方法的功能称为Java语言的反射机制。
用途
通过反射,Java 代码可以发现有关已加载类的字段,方法和构造函数的信息,并可以在安全限制内对这些字段,方法和构造函数进行操作。
很多人都认为反射在实际Java中开发应用中并不广泛,其实不然。当我们在使用 IDE(如 IDEA/Eclipse)时,当我们输入一个对象或者类并调用它的属性和方法时,一按 (“.”)点号,编译器就会自动列出她的属性或方法,这里就会用到反射。
反射最重要的用途就是开发各种通用框架
很多框架(比如 Spring)都是配置化的(比如Spring 通过 XML 配置模式装载 Bean),为了保证框架的通用性,他们可能根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射——运行时动态加载需要加载的对象。
对于框架开发人员来说,反射作用非常大,它是各种容器实现的核心。而对于一般的开发者来说,不深入框架开发反射用的就会少一点,不过了解一下框架的底层机制有助于丰富自己的编程思想,也是很有益的。
Java反射框架提供一下功能:
在运行时判定任意一个对象所属的类
在运行时构造任意一个类的对象
在运行时判定任意一个类所具有的成员变量和方法
在运行时调用任意一个对象的方法
反射的优缺点
反射的优点
使用反射机制,代码可以在运行时装配,提高了程序的灵活性和扩展性,降低耦合性,提高自适应能力。它允许程序创建和控制任何类的对象,无需硬编码目标类
反射的缺点
性能问题:使用反射基本上是一种解释操作,JVM无法对这些代码进行优化,因此,反射操作的效率要比那些非反射操作低得多。反射机制主要应用在对灵活性和扩展性要求很高的系统框架上,对性能要求高的程序中不建议使用
安全限制:使用反射技术要求程序必须在一个没有安全限制的环境中运行
内部暴露:由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用——代码有功能上的错误,降低可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
反射机制的相关类
与Java反射相关的类如下:

Class类
Class代表类的实体,在运行的Java应用程序中表示类和接口。在这个类中提供了很多有用的方法,这里对他们简单的分类介绍。获得类相关的方法:
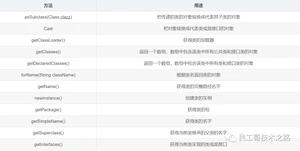
获得类中属性相关的方法
获得类中注解相关的方法

获得类中构造器相关的方法
获得类中方法相关的方法
类中其他重要的方法
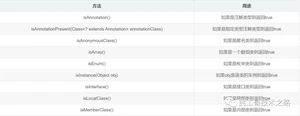
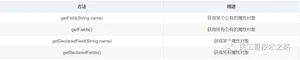
Field类
Field代表类的成员变量(成员变量也称为类的属性)。

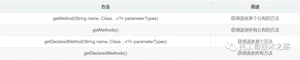
Method类
Method代表类的方法。

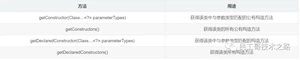
Constructor类
Constructor代表类的构造方法。

示例
为了演示反射的使用,首先构造一个与书籍相关的model——Book.java,然后了解获取Class类对象的三种方法,最后通过反射方法示例创建对象、反射私有构造方法、反射私有属性、反射私有方法
被反射类Book.java
获取Class类对象的三种方法
在反射中,要获取一个类或调用一个类的方法,我们首先需要获取到该类的 Class 对象。在 Java API 中,获取 Class 类对象的三种方法
方法一:使用 Class.forName 静态方法。当你知道该类的全路径名时,你可以使用该方法获取 Class 类对象。但可能抛出 ClassNotFoundException 异常;
方法二:这种方法只适合在编译前就知道操作的 Class。直接通过 类名.class 的方式得到,该方法最为安全可靠,程序性能更高,这说明任何一个类都有一个隐含的静态成员变量 class Class clz = Book.class;
方法三:使用类对象的 getClass() 方法。
输出结果都是true,可以知道三种方法获取到的Class对象都是同一个对象
反射常用类和方法测试
输出结果
通过反射获取私有属性,方法和构造方法时,需要进行暴力反射,设置setAccessible(true)。否则会报错说无法获取私有属性,方法和构造方法
总结
本文列举了反射机制使用过程中常用的、重要的一些类及其方法,更多信息和用法,反射原理和源码分析需要近一步的阅读反射相关资料。
在阅读Class类文档时发现一个特点,以通过反射获得Method对象为例,一般会提供四种方法,getMethod(parameterTypes)、getMethods()、getDeclaredMethod(parameterTypes)和getDeclaredMethods()。getMethod(parameterTypes)用来获取某个公有的方法的对象,getMethods()获得该类所有公有的方法,getDeclaredMethod(parameterTypes)获得该类某个方法,getDeclaredMethods()获得该类所有方法。带有Declared修饰的方法可以反射到私有的方法,没有Declared修饰的只能用来反射公有的方法。其他的Annotation、Field、Constructor也是如此。
Java基础语法
标识符
给包,类,方法,变量起名字的符号。
组成规则
标识符由字母、数字、下划线、美元符号组成。
命名原则:见名知意
包名:全部小写,多级包用.隔开。
举例:com.jourwon
类、接口:一个单词首字母大写,多个单词每个单词的首字母大写。
举例:Student,Car,HelloWorld
方法和变量:一个单词首字母小写,多个单词从第二个单词开始每个单词的首字母大写。
举例:age,maxAge,show(),getAge()
常量:如果是一个单词,所有字母大写,如果是多个单词,所有的单词大写,用下划线区分每个单词。
举例:DATE,MAX_AGE
项目名:全部用小写字母,多个单词之间用横杆-分割。
举例:demo,spring-boot
注意事项
不能以数字开头
不能是Java中的关键字
Java标识符大小写敏感,长度无限制
标识符不能包含空格
关键字
被Java语言赋予了特殊含义,用作专门用途的字符串(单词),这些关键字不能用于常量、变量、和任何标识符的名称。
Java关键字(Java 8版本)
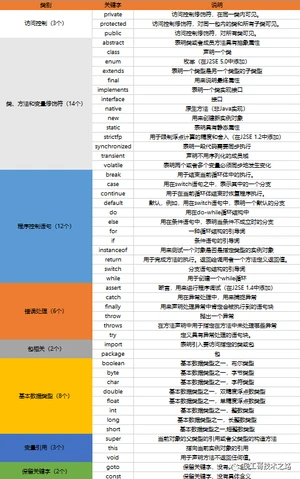
Java关键字(Java 8 以后版本)

注释
用于解释说明程序的文字
分类
单行注释
格式:// 注释文字
多行注释
格式:/* 注释文字 */
文档注释
格式:/** 注释文字 */
作用
在程序中,尤其是复杂的程序中,适当地加入注释可以增加程序的可读性,有利于程序的修改、调试和交流。注释的内容在程序编译的时候会被忽视,不会产生目标代码,注释的部分不会对程序的执行结果产生任何影响。
注意事项
多行和文档注释都不能嵌套使用。
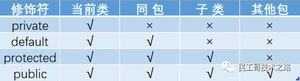
访问修饰符
Java中,可以使用访问修饰符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
分类
private : 在同一类内可见。使用对象:变量、方法。注意:不能修饰类(外部类)
default (即缺省,什么也不写,不使用任何关键字): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。注意:不能修饰类(外部类)。
public : 对所有类可见。使用对象:类、接口、变量、方法
访问修饰符图
分隔符

转义字符
转义字符是一种特殊的字符常量。转义字符以反斜线""开头,后跟一个或几个字符。转义字符具有特定的含义,不同于字符原有的意义,故称“转义”字符。
常见转义字符表
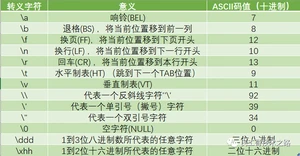
Java中需要转义的字符
在Java中,不管是String.split(),还是正则表达式,有一些特殊字符需要转义,这些字符是转义方法为字符前面加上"",这样在split、replaceAll时就不会报错。不过要注意,String.contains()方法不需要转义。
空行
空白行,或者有注释的行,Java编译器都会忽略掉
进制
进制也就是进位计数制,是人为定义的带进位的计数方法。
十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。
常用进制类型


进制转换
十进制转二进制
方法为:十进制数除2取余法,即十进制数除2,余数为权位上的数,得到的商值继续除2,依此步骤继续向下运算直到商为0为止。
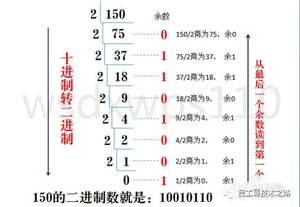
二进制转十进制
方法为:把二进制数按权展开、相加即得十进制数。

流程控制语句
流程是指程序运行时,各语句的执行顺序。流程控制语句就是用来控制程序中各语句执行的顺序。
Java流程控制语句-顺序结构
顺序结构是程序中最简单最基本的流程控制,没有特定的语法结构,按照代码的先后顺序,依次执行,程序中大多数的代码都是这样执行的
举例
Java流程控制语句-分支结构(选择结构)
条件语句可根据不同的条件执行不同的语句。包括if条件语句与switch多分支语句。
if分支结构
第一种格式
执行流程图
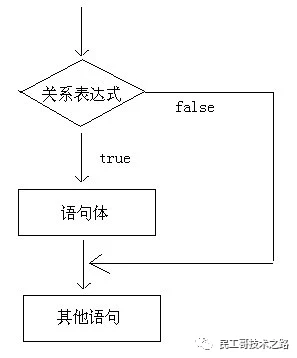
执行流程说明
首先判断关系表达式看其结果是true还是false
如果是true就执行语句体
如果是false就不执行语句体
举例
第二种格式
执行流程图
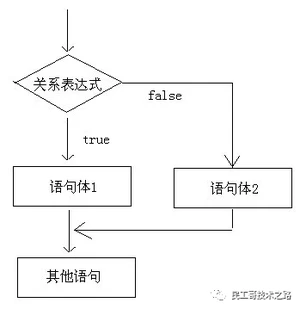
执行流程说明
首先判断关系表达式看其结果是true还是false
如果是true就执行语句体1
如果是false就执行语句体2
举例
第三种格式
执行流程图
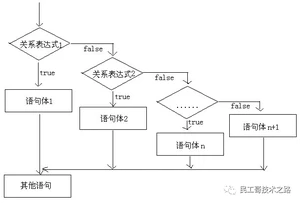
执行流程说明
首先判断关系表达式1看其结果是true还是false
如果是true就执行语句体1
如果是false就继续判断关系表达式2看其结果是true还是false
如果是true就执行语句体2
如果是false就继续判断关系表达式…看其结果是true还是false
…
如果没有任何关系表达式为true,就执行语句体n+1
举例
注意事项
1、一旦满足某个条件表达式,则进入其执行语句块执行,执行完毕后不会执行其一下的条件语句。
2、如果多个条件表达式之间为“互斥”关系,多个语句之间可以上下调换顺序,一旦是包含关系,要求条件表达式范围小的写到范围大的上边;
switch分支结构
执行流程说明
首先计算出表达式的值
其次,和case依次比较,一旦有对应的值,就会执行相应的语句,在执行的过程中,遇到break就会结束。
最后,如果所有的case都和表达式的值不匹配,就会执行default语句体部分,然后程序结束掉。
执行流程图
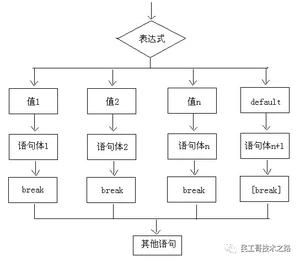
举例
注意事项
1、swich(表达式)中表达式的返回值必须是以下几种类型之一:
byte,short,char,int,枚举(jdk1.5),String(jdk1.7)
2、case子句中的值必须是常量,且所有case子句中的值应是不同的;
3、default子句是可任选的,当没有匹配的case时,执行default;
4、break语句用来在执行完一个case分支后使程序跳出swich语句块;如果没有break程序会顺序执行到swich结尾;
if分支结构和switch分支结构区别
if和swich语句很想,如果判断的具体数值不多,而且复合byte、short、int、char这四种类型。建议使用swich语句,因为效率稍高;
其他情况:对区间进行判断,对结果为boolean类型进行判断,使用if,if的使用范围比较广泛。
Java流程控制语句-循环结构
循环语句就是在满足一定条件的情况下反复执行某一个操作。包括while循环语句、do···while循环语句和for循环语句。
for循环语句
格式
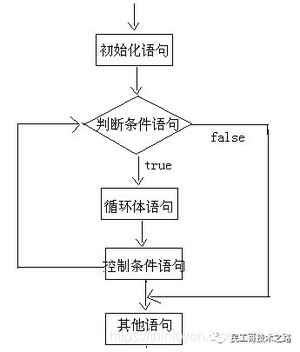
执行流程说明
A:执行初始化语句
B:执行判断条件语句,看其结果是true还是false
如果是false,循环结束。
如果是true,继续执行。
C:执行循环体语句
D:执行控制条件语句
E:回到B继续
举例
foreach循环语句
执行流程:和for循环执行流程相似
格式
举例
它是Java5后新增的for语句的特殊简化版本,并不能完全替代for语句,但所有foreach语句都可以改写为for语句。foreach语句在遍历数组等时为程序员提供了很大的方便。
while循环语句
基本格式
扩展格式
执行流程图
执行流程说明
while循环语句的循环方式为利用一个条件来控制是否要继续反复执行这个语句。
举例
do…while循环语句
基本格式
扩展格式
执行流程图
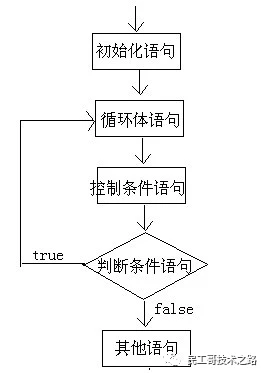
执行流程说明
A:执行初始化语句;
B:执行循环体语句;
C:执行控制条件语句;
D:执行判断条件语句,看是true还是false
如果是true,回到B继续
如果是false,就结束
举例
三种循环的区别
虽然可以完成同样的功能,但是还是有小区别:
do…while循环至少会执行一次循环体。
for循环和while循环只有在条件成立的时候才会去执行循环体
for循环语句和while循环语句的小区别:
使用区别:控制条件语句所控制的那个变量,在for循环结束后,就不能再被访问到了,而while循环结束还可以继续使用,如果你想继续使用,就用while,否则推荐使用for。原因是for循环结束,该变量就从内存中消失,能够提高内存的使用效率。
跳转语句(控制循环结构)
Java语言中提供了3种跳转语句,分别是break语句、continue语句和return语句。
break
break的使用场景:
在选择结构switch语句中
在循环语句中
break的作用:跳出单层循环
注意:离开使用场景是没有意义的。
举例
continue
continue的使用场景:在循环语句中
continue的作用:结束一次循环,继续下一次的循环
注意:离开使用场景的存在是没有意义的
continue与break区别:
break 退出当前循环
continue 退出本次循环
举例
return的使用场景:
在循环语句中
在方法中
return的作用:
可以从一个方法返回,并把控制权交给调用它的语句。
直接结束整个方法,从而结束循环。
举例
表达式
用运算符把常量或者变量连接起来符号java语法的式子就可以称为表达式。
类型和值
表达式值的数据类型即为表达式的类型。
对表达式中操作数进行运算得到的结果是表达式的值。
运算顺序
应按照运算符的优先级从高到低的顺序进行;
优先级相同的运算符按照事先约定的结合方向进行;
举例
运算符
运算符指明对操作数的运算方式。
算术运算符
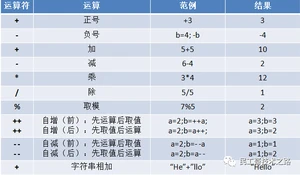
注意事项
1、/ 左右两端的类型需要一致;
2、%最后的符号和被模数相同;
3、前++;先+1,后运算 后++;先运算,后+1;
4、+:当String字符串与其他数据类型只能做连接运算;并且结果为String类型;
比较运算符(关系运算符)
比较运算符1
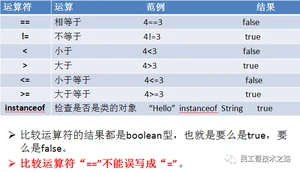
比较运算符2
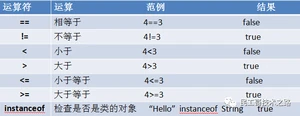
注意事项
1、比较运算符的两端都是boolean类型,也就是说要么是true,要么是false;
2、比较运算符的"==“与”="的作用是不同的,使用的时候需要小心。
赋值运算符
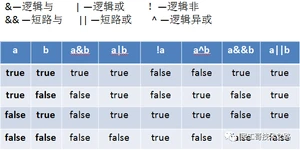
逻辑运算符(符号的两端都是boolean类型)
注意事项
1、& 与 &&以及|与||的区别:
&:左边无论真假,右边都会进行运算;
&&:如果左边为假,则右边不进行运算;
| 与 || 的区别同上;在使用的时候建议使用&&和||;
2、(^)与或(|)的不同之处是:当左右都为true时,结果为false。
逻辑运算符
位运算符(两端都是数值型的数据)
位运算符1
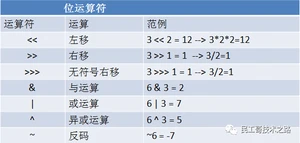
位运算符2

三元运算符(三目运算符)

注意事项
1、表达式1与表达式2的类型必须一致;
2、使用三元运算符的地方一定可以使用if…else代替,反之不一定成立;
运算符的优先级
优先级按照从高到低的顺序书写,也就是优先级为1的优先级最高,优先级14的优先级最低。使用优先级为 1 的小括号可以改变其他运算符的优先级。
变量
在程序执行的过程中,在某个范围内其值可以发生改变的量。从本质上讲,变量其实是内存中的一小块区域
成员变量
方法外部,类内部定义的变量
类变量(静态变量):独立于方法之外的变量,用 static 修饰。
类变量也称为静态变量,在类中以static关键字声明,但必须在方法构造方法和语句块之外。
无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。
静态变量除了被声明为常量外很少使用。常量是指声明为public/private,final和static类型的变量。常量初始化后不可改变。
静态变量储存在静态存储区。经常被声明为常量,很少单独使用static声明变量。
静态变量在第一次被访问时创建,在程序结束时销毁。
与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为public类型。
默认值和实例变量相似。数值型变量默认值是0,布尔型默认值是false,引用类型默认值是null。变量的值可以在声明的时候指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。
静态变量可以通过:ClassName.VariableName的方式访问。
类变量被声明为public static final类型时,类变量名称一般建议使用大写字母。如果静态变量不是public和final类型,其命名方式与实例变量以及局部变量的命名方式一致。
实例变量(非静态变量):独立于方法之外的变量,不过没有 static 修饰。
实例变量声明在一个类中,但在方法、构造方法和语句块之外;
当一个对象被实例化之后,每个实例变量的值就跟着确定;
实例变量在对象创建的时候创建,在对象被销毁的时候销毁;
实例变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息;
实例变量可以声明在使用前或者使用后;
访问修饰符可以修饰实例变量;
实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见;
实例变量具有默认值。数值型变量的默认值是0,布尔型变量的默认值是false,引用类型变量的默认值是null。变量的值可以在声明时指定,也可以在构造方法中指定;
实例变量可以直接通过变量名访问。但在静态方法以及其他类中,就应该使用完全限定名:ObejectReference.VariableName。
类变量和实例变量的区别
调用方式
静态变量也称为类变量,可以直接通过类名调用。也可以通过对象名调用。这个变量属于类。
成员变量也称为实例变量,只能通过对象名调用。这个变量属于对象。
存储位置
静态变量存储在方法区长中的静态区。
成员变量存储在堆内存。
生命周期
静态变量随着类的加载而存在,随着类的消失而消失。生命周期长。
成员变量随着对象的创建而存在,随着对象的消失而消失。
与对象的相关性
静态变量是所有对象共享的数据。
成员变量是每个对象所特有的数据。
局部变量
局部变量:类的方法中的变量。
局部变量声明在方法、构造方法或者语句块中;
局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,变量将会被销毁;
访问修饰符不能用于局部变量;
局部变量只在声明它的方法、构造方法或者语句块中可见;
局部变量是在栈上分配的。
局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
成员变量和局部变量的区别
作用域
成员变量:针对整个类有效。
局部变量:只在某个范围内有效。(一般指的就是方法,语句体内)
存储位置
成员变量:随着对象的创建而存在,随着对象的消失而消失,存储在堆内存中。
局部变量:在方法被调用,或者语句被执行的时候存在,存储在栈内存中。当方法调用完,或者语句结束后,就自动释放。
生命周期
成员变量:随着对象的创建而存在,随着对象的消失而消失
局部变量:当方法调用完,或者语句结束后,就自动释放。
初始值
成员变量:有默认初始值。
局部变量:没有默认初始值,使用前必须赋值。
使用原则
在使用变量时需要遵循的原则为:就近原则,首先在局部范围找,有就使用;接着在成员位置找。
基本数据类型变量
基本数据类型
byte,short,int,long,float,double,char,boolean
变量的定义格式
数据类型 变量名 = 初始化值;
注意
整数默认是int类型,定义long类型的数据时,要在数据后面加L。
浮点数默认是double类型,定义float类型的数据时,要在数据后面加F。
引用数据类型变量
定义格式
数据类型 变量名 = 初始化值;
注意:格式是固定的,记住格式,以不变应万变
举例
注意事项
类外面不能有变量的声明
常量
定义
常量定义:在程序执行的过程中,其值不可以发生改变的量。常量不同于常量值,它可以在程序中用符号来代替常量值使用,因此在使用前必须先定义。
常量值定义:常量和常量值是不同的概念,常量值又称为字面常量,它是通过数据直接表示的。
关系:常量值是常量的具体和直观的表现形式,常量是形式化的表现。通常在程序中既可以直接使用常量值,也可以使用常量。
分类
字符串常量 用双引号括起来的内容(“HelloWorld”)
整数常量 所有整数(12,-23)
小数常量 所有小数(12.34)
字符常量 用单引号括起来的内容(‘a’,’A’,’0’)
布尔常量 较为特有,只有true和false
空常量 null(数组部分讲解)
举例
Java 语言使用 final 关键字来定义一个常量
final int COUNT=10;
final float HEIGHT=10.2F;
注意事项
在定义常量时就需要对该常量进行初始化。
final 关键字不仅可以用来修饰基本数据类型的常量,还可以用来修饰对象的引用或者方法。
为了与变量区别,常量取名一般都用大写字符。
数据类型
Java语言是强类型语言,对于每一种数据都定义了明确的具体的数据类型,在内存中分配了不同大小的内存空间。
分类
基本数据类型
类(class)
接口(interface)
数组([])
整数类型(byte,short,int,long)
浮点类型(float,double)
数值型
字符型(char)
布尔型(boolean)
引用数据类型
计算机存储单元
定义:变量是内存中的小容器,用来存储数据。那么计算机内存是怎么存储数据的呢?无论是内存还是硬盘,计算机存储设备的最小信息单元叫“位(bit)”,我们又称之为“比特位”,通常用小写的字母b表示。而计算机最小的存储单元叫“字节(byte)”,通常用大写字母B表示,字节是由连续的8个位组成。
常用存储单元关系
Java基本数据类型图
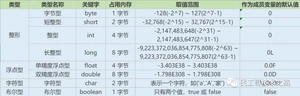
定义
数据类型的转换是在所赋值的数值类型和被变量接收的数据类型不一致时发生的,它需要从一种数据类型转换成另一种数据类型。
分类
自动类型转换的实现需要同时满足两个条件:①两种数据类型彼此兼容,②目标类型的取值范围大于源数据类型(低级类型数据转换成高级类型数据)。例如 byte 类型向 short 类型转换时,由于 short 类型的取值范围较大,会自动将 byte 转换为 short 类型。
数值型数据的转换:byte→short→int→long→float→double。
字符型转换为整型:char→int。
在运算过程中,由于不同的数据类型会转换成同一种数据类型,所以整型、浮点型以及字符型都可以参与混合运算。自动转换的规则是从低级类型数据转换成高级类型数据。
隐式转换
定义
转换规则
转换条件
显式转换
目标类型 变量名 = (目标类型) (被转换的数据);
当两种数据类型不兼容,或目标类型的取值范围小于源类型时,自动转换将无法进行,这时就需要进行强制类型转换。
定义
语法格式
举例:int b = (byte)(a + b);
注意
如果超出了被赋值的数据类型的取值范围得到的结果会与你期望的结果不同
不建议强制转换,因为会有精度的损失。
作者:ThinkWon
blog.csdn.net/thinkwon/category_9379953.html
我的新书:《 Linux系统运维指南 》已出版
推荐阅读 点击标题可跳转
ClickHouse 这么牛逼吗?是的,简直开挂!
挺带劲!这款开源数据库迁移工具超牛逼
干掉 Swagger (丝袜哥),试试这个新工具!
再见!Eclipse
程序员缺乏经验的 7 种表现!
北京最最最牛逼的 IT 公司全在这了!
几款超牛逼的 SSH 客户端工具!好用到爆
Docker 常用命令!还有谁不会?
JetBrains 又出了款新神器,一套代码适应多端!
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/26452.html