
- 1)有一台Linux或Linux虚拟机
- 2)安装JDK(推荐1.7)
- 3)安装Apache Ant
下载Nutch源码:
推荐使用Nutch 1.9,官方下载地址:http://mirrors.hust.edu.cn/apache/nutch/1.9/apache-nutch-1.9-src.zip
安装IDE:
转换:
Nutch源码是用ant进行构建的,需要转换成eclipse工程才可以导入IDE正确使用,Intellij和Netbeans都可以支持ecilpse工程。
解压下载的apache-nutch-1.9-src.zip,得到文件夹apache-nutch-1.9。
找到:
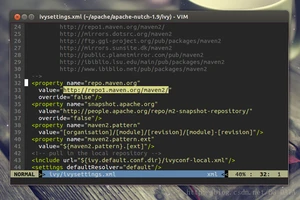
将value修改为http://maven.oschina.net/content/groups/public/ ,修改后:
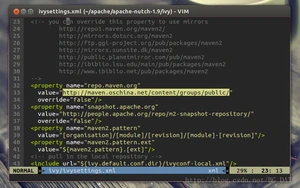
保存并退出,保证当前目录为apache-nutch-1.9,执行命令:
然后耐心等待,这个过程ant会根据ivy从中心仓库下载各种依赖jar包,可能要十几分钟。
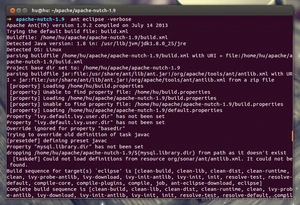
-verbose参数加上之后可以看到ant过程的详细信息。
10分钟左右,转换成功:
打开Intellij, File -> Import Project ->选择apache-nutch-1.9文件夹,确定后选择Import project from external model(Eclipse)
一直点击next到结束。成功将项目导入Intellij:
源码导入工程后,并不能执行完整的爬取。Nutch将爬取的流程切分成很多阶段,每个阶段分别封装在一个类的main函数中。在外面通过Linux Shell调用这些main函数,来完整爬取的流程。我们在后续教程中会对流程调度做一个详细的说明。
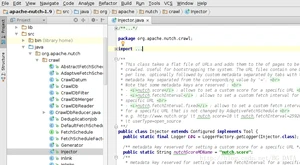
在阅读Nutch源码的过程中,最重要的就是找到每个类的main函数:
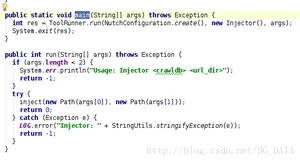
可以看到,main函数其实是利用ToolRunner,执行了run(String[] args)。这里ToolRunner.run会从第二个参数(new Injector())这个对象中,找到run(String[] args)这个方法执行。
从run方法中可以看出来,String[] args需要有2个参数,第一个参数表示爬虫的URL管理文件夹(输出),第二个参数表示种子文件夹(输入)。对hadoop中的map reduce程序来说,输入文件夹是必须存在的,输出文件夹应该不存在。我们创建一个文件夹 /tmp/urls,来存放种子文件(作为输入)。

在seed.txt中加入一个种子URL

运行这个类,我们会发现报错了(下面只给了错误的一部分):
这是因为用这种方式执行,按照Nutch默认的配置,不能正确地加载插件。我们需要修改Nutch的配置文件,为插件文件夹指定一个绝对路径,修改conf/nutch-default.xml文件,找到:
将value修改为绝对路径 apache-nutch-1.9所在文件夹+”/src/plugin”,比如我的配置:
建议在修改nutch-default.xml时,将原来的配置注释,并复制一份新的修改,方便还原:
现在再运行Injector.java,看到结果:

运行成功。
读取爬虫文件:
我们查看程序的输出 tree /tmp/crawldb ,如果没有tree命令,就直接用资源管理器之类的查看吧:
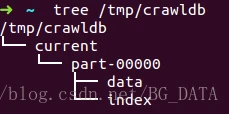
查看里面的data文件:

这是一个SequenceFile,Nutch中除了Inject的输入(种子)之外,其他文件 全部以SequenceFile的形式存储。SequenceFile的结构如下:
以key value的形式,将对象序列(key value序列)存储到文件中。我们从SequenceFile头部可以看出来key value的类型。
新建一个类org.apache.nutch.example.InjectorReader
运行结果:
我们可以看到,程序读出了刚才Inject到crawldb的url,key是url,value是一个CrawlDatum对象,这个对象用来维护爬虫的URL管理信息,我们可以看到一行:
表示当前url为未爬取状态,在后续流程中,爬虫会从crawldb取未爬取的url进行爬取。
完整爬取:
下面给出的是各位最期待的代码,就是如何用Nutch完成一次完整的爬取。官方代码在1.7之前(包括1.7),包含一个Crawl.java,这个代码的main函数可以执行一次完整的爬取,但是从1.7之后就取消了。只保留了使用Linux Shell来调用每个流程,来完成爬取的方法。但是好在取消的Crawl.java修改一下,还是可以使用的。
在爬取之前,我们先修改一下conf/nutch-default.xml中的一个地方,找到:
and set their values appropriately.
在
and set their values appropriately.
这个值会在发送http请求时,作为User-Agent字段。
下面给出代码:
运行成功,对网站进行了一个2层的爬取,爬取信息都保存在/tmp/crawl+时间的文件夹中。
有些时候爬虫爬一层就停止了,有几种原因:
- 1)种子对应的页面大小超过配置的上限,页面被忽略。
- 2)nutch默认遵循robots协议,有可能robots协议禁止了爬取,不过出现这种情况日志会给出相关信息。
- 3)网页没有被正确爬取(这种情况少)。
爬很多门户网站时容易出现第一种情况,这种情况只需要找到conf/nutch-default.xml中的:
将value设置为-1即可
如果看到日志中有说被robots协议阻拦,修改Fetcher.java的源码,找到:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/14517.html