
前言
io流用到的地方很多,就比如上传下载,传输,设计模式等....基础打扎实了,才能玩更高端的。
在博主认为真正懂IO流的优秀程序员每次在使用IO流之前都会明确分析如下四点:
(1)明确要操作的数据是数据源还是数据目的(也就是要读还是要写)
(2)明确要操作的设备上的数据是字节还是文本
(3)明确数据所在的具体设备
(4)明确是否需要额外功能(比如是否需要转换流、高效流等)
以上四点将会在文章告白IO流的四点明确里面小结一下,如果各位真能熟练以上四点,我觉得这篇文章你就没必要看了,因为你已经把IO玩弄与股掌之中,万物皆可被你盘也就也不再话下了。
@
(1)明确要操作的数据是数据源还是数据目的(要读还是要写)
源:
InputStream Reader
目的:
OutputStream Writer
(2)明确要操作的设备上的数据是字节还是文本
源:
字节: InputStream
文本: Reader
目的:
字节: OutputStream
文本: Writer
(3)明确数据所在的具体设备
源设备:
硬盘:文件 开头
内存:数组,字符串
键盘:
网络:
对应目的设备:
硬盘:文件 开头
内存:数组,字符串
屏幕:
网络:
(4)明确是否需要额外功能
需要转换—— 转换流 InputStreamReader 、OutputStreamWriter
需要高效—— 缓冲流Bufferedxxx
多个源—— 序列流 SequenceInputStream
对象序列化—— ObjectInputStream、ObjectOutputStream
保证数据的输出形式—— 打印流PrintStream 、Printwriter
操作基本数据,保证字节原样性——DataOutputStream、DataInputStream
到这里,我们再来看看IO流的分类吧
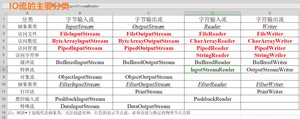
OK,准备好了告白IO流了咩?
至于IO流,也就是输入输出流,从文件出发到文件结束,至始至终都离不开文件,所以IO流还得从文件File类讲起。
怎么理解上面两句话?其实很简单!
在java中,一切皆是对象,File类也不例外,不论是哪个对象都应该从该对象的构造说起,所以博主来分析分析类的构造方法。首先从API开始着手

我们主要来学习一下比较常用的三个:
1、 :通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。
2、 :从父路径名字符串和子路径名字符串创建新的 File实例。
3、 :从父抽象路径名和子路径名字符串创建新的 File实例。
看字描述不够生动不够形象不得劲?没得事,下面进行构造举例,马上就生动形象了,代码如下:
File类的注意点:
- 一个File对象代表硬盘中实际存在的一个文件或者目录。
- File类构造方法不会给你检验这个文件或文件夹是否真实存在,因此无论该路径下是否存在文件或者目录,都不影响File对象的创建。
File的常用方法主要分为获取功能、获取绝对路径和相对路径、判断功能、创建删除功能的方法
1、 :返回此File的绝对路径名字符串。
2、 :将此File转换为路径名字符串。
3、 :返回由此File表示的文件或目录的名称。
4、 :返回由此File表示的文件的长度。
以上方法测试,代码如下【注意测试以自己的电脑文件夹为准】:
注意:,表示文件的长度。但是对象表示目录,则返回值未指定。
绝对路径:一个完整的路径,以盘符开头,例如。
相对路径:一个简化的路径,不以盘符开头,例如。
1、路径是不区分大小写
2、路径中的文件名称分隔符windows使用反斜杠,反斜杠是转义字符,两个反斜杠代表一个普通的反斜杠
1、 :此File表示的文件或目录是否实际存在。
2、 :此File表示的是否为目录。
3、 :此File表示的是否为文件。
方法演示,代码如下:
- :文件不存在,创建一个新的空文件并返回,文件存在,不创建文件并返回。
- :删除由此File表示的文件或目录。
- :创建由此File表示的目录。
- :创建由此File表示的目录,包括任何必需但不存在的父目录。
其中,和方法类似,但,只能创建一级目录,可以创建多级目录比如,所以开发中一般用;
这些方法中值得注意的是createNewFile方法以及mkdir与mkdirs的区别
方法测试,代码如下:
注意:方法,如果此表示目录,则目录必须为空才能删除。
- :返回一个String数组,表示该File目录中的所有子文件或目录。
- :返回一个File数组,表示该File目录中的所有的子文件或目录。
listFiles在获取指定目录下的文件或者文件夹时必须满足下面两个条件
1,指定的目录必须存在
2,指定的必须是目录。否则容易引发返回数组为null,出现NullPointerException异常
不说啥了,直接上代码:
如果对上面的代码有疑问,可以随时联系我,博主一直都在!
我想在座各位肯定经历都过这样的场景。当你编辑一个文本文件也好用eclipse打代码也罢,忘记了 ,在你关闭文件的哪一瞬间手残点了个不该点的按钮,但你反应过来,心早已拔凉拔凉的了。
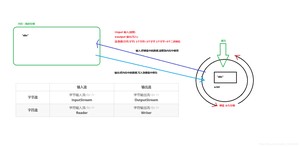
我们把这种数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为 和 ,即流向内存是输入流,流出内存的输出流。
Java中I/O操作主要是指使用包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出数据。
根据数据的流向分为:输入流 和 输出流。
- 输入流 :把数据从上读取到中的流。
- 输出流 :把数据从 中写出到上的流。
根据数据的类型分为:字节流 和 字符流。
- 字节流 :以字节为单位,读写数据的流。
- 字符流 :以字符为单位,读写数据的流。
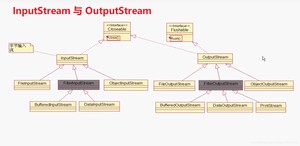
分类之后对应的超类(V8提示:超类也就是父类的意思)
注:
由这四个类的子类名称基本都是以其父类名作为子类名的后缀。
如:InputStream的子类FileInputStream。
如:Reader的子类FileReader。
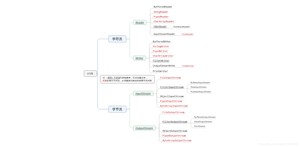
啥都不说了,看图吧
OutputStream与InputStream的继承关系
我们必须明确一点的是,一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。
抽象类是表示字节输出流的所有类的超类(父类),将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法,不要问我为啥可以定义字节输出流的基本共性功能方法,熊dei啊,上一句说过了OutputStream是字节输出流的所有类的超类,继承知识,懂?(如果是真的不理解的小白同学,可以点击蓝色字体继承进入补习)
字节输出流的基本共性功能方法:
1、 :关闭此输出流并释放与此流相关联的任何系统资源。
2、 :刷新此输出流并强制任何缓冲的输出字节被写出。
3、 :将 b.length个字节从指定的字节数组写入此输出流。
4、 :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。 也就是说从off个字节数开始读取一直到len个字节结束
5、 :将指定的字节输出流。
以上五个方法则是字节输出流都具有的方法,由父类OutputStream定义提供,子类都会共享以上方法
FileOutputStream类
有很多子类,我们从最简单的一个子类FileOutputStream开始。看名字就知道是文件输出流,用于将数据写出到文件。
FileOutputStream构造方法
不管学啥子,只有是对象,就从构造方法开始!
1、 :根据File对象为参数创建对象。
2、 : 根据名称字符串为参数创建对象。
推荐第二种构造方法【开发常用】:
就以上面这句代码来讲,类似这样创建字节输出流对象都做了三件事情:
1、调用系统功能去创建文件【输出流对象才会自动创建】
2、创建outputStream对象
3、把foutputStream对象指向这个文件
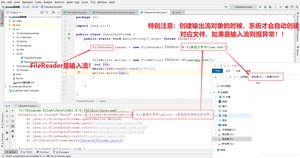
注意:
创建输出流对象的时候,系统会自动去对应位置创建对应文件,而创建输出流对象的时候,文件不存在则会报FileNotFoundException异常,也就是系统找不到指定的文件异常。
当你创建一个流对象时,必须直接或者间接传入一个文件路径。比如现在我们创建一个流对象,在该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。有兴趣的童鞋可以测试一下,具体代码如下:
FileOutputStream写出字节数据
使用FileOutputStream写出字节数据主要通过方法,而方法分如下三种
- 写出字节: 方法,每次可以写出一个字节数据,代码如下:
- 虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。
- 流操作完毕后,必须释放系统资源,调用close方法,千万记得。
- 写出字节数组:,每次可以写出数组中的数据,代码使用演示:
- 写出指定长度字节数组: ,每次写出从索引开始,个字节,代码如下:
FileOutputStream实现数据追加续写、换行
经过以上的代码测试,每次程序运行,每次创建输出流对象,都会清空目标文件中的数据。如何保留目标文件中数据,还能继续追加新数据呢?并且实现换行呢?其实很简单,这个时候我们又要再学习的另外两个构造方法了,如下:
1、
2、
这两个构造方法,第二个参数中都需要传入一个boolean类型的值, 表示追加数据, 表示不追加也就是清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了,至于Windows换行则是 ,下面将会详细讲到。
实现数据追加续写代码如下:
Windows系统里,换行符号是 ,具体代码如下:
- 回车符和换行符 :
- 回车符:回到一行的开头(return)。
- 换行符:下一行(newline)。
- 系统中的换行:
- Windows系统里,每行结尾是 ,即;
- Unix系统里,每行结尾只有 ,即;
- Mac系统里,每行结尾是 ,即。从 Mac OS X开始与Linux统一。
抽象类是表示字节输入流的所有类的超类(父类),可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
字节输入流的基本共性功能方法:
3、 : 该方法返回的int值代表的是读取了多少个字节,读到几个返回几个,读取不到返回-1
FileInputStream类
类是文件输入流,从文件中读取字节。
FileInputStream的构造方法
同样的,推荐使用第二种构造方法:
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出 。
构造举例,代码如下:
FileInputStream读取字节数据
- 读取字节:方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回,代码测试如下【read.txt文件中内容为abcde】:
循环改进读取方式,代码使用演示:
- 使用字节数组读取:,每次读取b的长度个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回 ,代码使用演示:
由于文件中内容为,而错误数据,是由于最后一次读取时,只读取一个字节,数组中,上次读取的数据没有被完全替换【注意是替换,看下图】,所以要通过 ,获取有效的字节
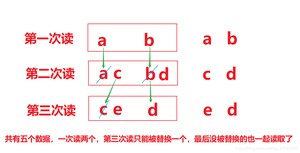
代码如下:
在开发中一般强烈推荐使用数组读取文件,代码如下:
字节流FileInputstream复制图片
复制图片原理
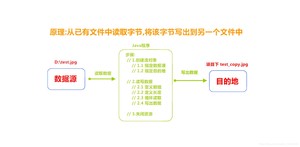
代码实现
复制图片文件,代码如下:
注:复制文本、图片、mp3、视频等的方式一样。
到这里,已经从File类讲到了字节流OutputStream与InputStream,而现在将主要从字符流Reader和Writer的故事开展。
字符流Reader和Writer的故事从它们的继承图开始,啥都不说了,直接看图
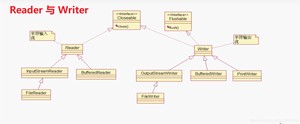
字符流的由来:因为数据编码的不同,因而有了对字符进行高效操作的流对象,字符流本质其实就是基于字节流读取时,去查了指定的码表,而字节流直接读取数据会有乱码的问题(读中文会乱码),这个时候小白同学就看不懂了,没事,咋们先来看个程序:
具体现状分析
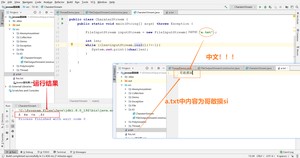
话说,就是你哥我敢摸si,那你哥我肯定也不认识这玩意啊:
字节流读取中文字符时,可能不会显示完整的字符,那是因为一个中文字符占用多个字节存储。
那字节流就没办法了吗?不,字节流依旧有办法,只是麻烦了点,代码如下:
这是为啥呢?没错解码的正是,查看的源码,构造方法有解码功能,并且默认编码是,代码如下:
尽管字节流也能有办法决绝乱码问题,但是还是比较麻烦,于是java就有了字符流,读写数据,字符流文件。如果处理纯文本的数据优先考虑字符流,其他情况就只能用字节流了(图片、视频、等等例外)。
从另一角度来说:字符流 = 字节流 + 编码表
抽象类是字符输入流的所有类的超类(父类),可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
字符输入流的共性方法:
1、 :关闭此流并释放与此流相关联的任何系统资源。
2、 : 从输入流读取一个字符。
3、 : 从输入流中读取一些字符,并将它们存储到字符数组 中
类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
1、: 创建一个新的 FileReader ,给定要读取的File对象。
2、 : 创建一个新的 FileReader ,给定要读取的文件的字符串名称。
构造方法的使用就算不写应该都很熟悉了吧,代码如下:
- 读取字符:方法,每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回,循环读取,代码使用演示:
至于读取的写法类似字节流的写法,只是读取单位不同罢了。
抽象类是字符输出流的所有类的超类(父类),将指定的字符信息写出到目的地。它同样定义了字符输出流的基本共性功能方法。
字符输出流的基本共性功能方法:
1、 写入单个字符。
2、写入字符数组。
3、 写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
4、 写入字符串。
5、 写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
6、刷新该流的缓冲。
7、 关闭此流,但要先刷新它。
类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
依旧是熟悉的构造举例,代码如下:
写出字符: 方法,每次可以写出一个字符数据,代码使用演示:
【注意】关闭资源时,与FileOutputStream不同。 如果不关闭,数据只是保存到缓冲区,并未保存到文件。
因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要 方法了。
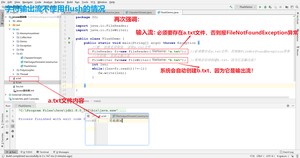
运行效果是怎么样的呢?答案是b.txt文件中依旧是空的,是的并没有任何东西,为啥呢?熊dei啊,我在上面就用红色字体特别标注过了,就是这句话: 【注意】关闭资源时,与FileOutputStream不同。 如果不关闭,数据只是保存到缓冲区,并未保存到文件。这个时候反应过来了吧,可见实践例子的重要性,编程就是这样,不去敲,永远学不会!!!所以一定要去敲,博主没敲过10万行代码真的没有脸出去说自己是学java的。所以,大家一定要多思考,多敲啊!!!
所以,我们在以上的代码中再添加下面三句代码,就完美了,b.txt文件就能复制到源文件的数据了!
这个函数是清空的意思,用于清空缓冲区的数据流,进行流的操作时,数据先被读到内存中,然后再用数据写到文件中,那么当你数据读完时,我们如果这时调用方法关闭读写流,这时就可能造成数据丢失,为什么呢?因为,读入数据完成时不代表写入数据完成,一部分数据可能会留在缓存区中,这个时候方法就格外重要了。
好了,接下来close使用代码如下:
即便是flush方法写出了数据,操作的最后还是要调用close方法,释放系统资源。
续写和换行:操作类似于FileOutputStream操作(上一篇博客讲到过),直接上代码:
直接上代码:
最后再次强调:
字符流,只能操作文本文件,不能操作图片,视频等非文本文件。当我们单纯读或者写文本文件时 使用字符流 其他情况使用字节流
我们在学习的过程中可能习惯把异常抛出,而实际开发中并不能这样处理,建议使用 代码块,处理异常部分,格式代码如下:
如果对异常不是特别熟练的童鞋可以参考这篇文章【java基础之异常】死了都要try,不淋漓尽致地catch我不痛快!
好了,到这里,字符流Reader和Writer的故事的到这里了!
前面主要写了一些基本的流作为IO流的入门。从这里开始将要见识一些更强大的流。比如能够高效读写的缓冲流,能够转换编码的转换流,能够持久化存储对象的序列化流等等,而这些强大的流都是在基本的流对象基础之上而来的!这些强大的流将伴随着我们今后的开发!
首先我们来认识认识一下缓冲流,也叫高效流,是对4个 流的“增强流”。
缓冲流的基本原理:
1、使用了底层流对象从具体设备上获取数据,并将数据存储到缓冲区的数组内。
2、通过缓冲区的read()方法从缓冲区获取具体的字符数据,这样就提高了效率。
3、如果用read方法读取字符数据,并存储到另一个容器中,直到读取到了换行符时,将另一个容器临时存储的数据转成字符串返回,就形成了readLine()功能。
也就是说在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
缓冲书写格式为,按照数据类型分类:
- 字节缓冲流:,
- 字符缓冲流:,
- :创建一个新的缓冲输入流,注意参数类型为InputStream。
- : 创建一个新的缓冲输出流,注意参数类型为OutputStream。
构造举例代码如下:
缓冲流读写方法与基本的流是一致的,我们通过复制370多MB的大文件,测试它的效率。
- 基本流,代码如下:
- 缓冲流,代码如下:
有的童鞋就要说了,我要更快的速度!最近看速度与激情7有点上头,能不能再快些?答案是当然可以
想要更快可以使用数组的方式,代码如下:
相同的来看看其构造,其格式以及原理和字节缓冲流是一样一样的!
- :创建一个新的缓冲输入流,注意参数类型为Reader。
- : 创建一个新的缓冲输出流,注意参数类型为Writer。
构造举例,代码如下:
字符缓冲流的基本方法与普通字符流调用方式一致,这里不再阐述,我们来看字符缓冲流具备的特有方法。
- BufferedReader:: 读一行数据。 读取到最后返回null
- BufferedWriter:: 换行,由系统属性定义符号。
方法演示代码如下:
方法演示代码如下:
字符缓冲流练习啥捏?先放松一下吧各位,先欣赏欣赏我写的下面的诗篇
6.你说你的程序叫简单,我说我的代码叫诗篇
1.一想到你我就哦豁豁豁豁豁豁豁豁豁豁....哦nima个头啊,完全不理人家受得了受不了
8.Just 简单你和我 ,Just 简单程序员
3.约了地点却忘了见面 ,懂得寂寞才明白浩瀚
5.沉默是最大的发言权
2.总是喜欢坐在电脑前, 总是喜欢工作到很晚
7.向左走 又向右走,我们转了好多的弯
4.你从来就不问我,你还是不是那个程序员
欣赏完了咩?没错咋们就练习如何使用缓冲流的技术把上面的诗篇归顺序,都编过号了就是前面的1到8的编号
分析:首先用字符输入缓冲流创建个源,里面放没有排过序的文字,之后用字符输出缓冲流创建个目标接收,排序的过程就要自己写方法了哦,可以从每条诗词的共同点“.”符号下手!
运行效果
何谓转换流?为何由来?暂时带着问题让我们先来了解了解字符编码和字符集!

众所周知,计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照规则存储,同样按照规则解析,那么就能显示正确的文本符号。反之,按照规则存储,再按照规则解析,就会导致乱码现象。
简单一点的说就是:
编码:字符(能看懂的)--字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
代码解释则是
- 字符编码 : 就是一套自然语言的字符与二进制数之间的对应规则。
而编码表则是生活中文字和计算机中二进制的对应规则
- 字符集 :也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有字符集、字符集、字符集等。
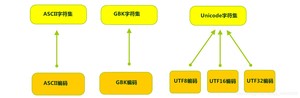
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
- ASCII字符集 :
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
- ISO-8859-1字符集:
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
- ISO-8859-1使用单字节编码,兼容ASCII编码。
- GBxxx字符集:
- GB就是国标的意思,是为了显示中文而设计的一套字符集。
- GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
- GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
- GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
- Unicode字符集 :
- Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
- 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
- UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
在java开发工具IDEA中,使用 读取项目中的文本文件。由于IDEA的设置,都是默认的编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
那么如何读取GBK编码的文件呢? 这个时候就得讲讲转换流了!
从另一角度来讲:字符流=字节流+编码表
转换流,是的子类,从字面意思可以看出它是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造代码如下:
转换流 ,是Writer的子类,字面看容易混淆会误以为是转为字符流,其实不然,OutputStreamWriter为从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造举例,代码如下:
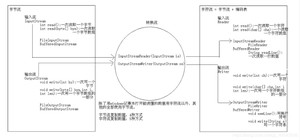
为了达到最高效率,可以考虑在 内包装
(1)可以把对象写入文本文件或者在网络中传输
(2)如何实现序列化呢?
让被序列化的对象所属类实现序列化接口。
该接口是一个标记接口。没有功能需要实现。
(3)注意问题:
把数据写到文件后,在去修改类会产生一个问题。
如何解决该问题呢?
在类文件中,给出一个固定的序列化id值。
而且,这样也可以解决黄色警告线问题
(4)面试题:
什么时候序列化?
如何实现序列化?
什么是反序列化?
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该、和等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。、和信息,都可以用来在内存中创建对象。看图理解序列化:

类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
: 创建一个指定OutputStream的ObjectOutputStream。
构造代码如下:
- 一个对象要想序列化,必须满足两个条件:
该类必须实现 接口, 是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出 。
该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用 关键字修饰。
2.写出对象方法
: 将指定的对象写出。
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
: 创建一个指定InputStream的ObjectInputStream。
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用读取对象的方法:
- : 读取一个对象。
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 异常。
另外,当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个异常。发生这个异常的原因如下:
1、该类的序列版本号与从流中读取的类描述符的版本号不匹配
2、该类包含未知数据类型
2、该类没有可访问的无参数构造方法
接口给需要序列化的类,提供了一个序列版本号。 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
- 将存有多个自定义对象的集合序列化操作,保存到文件中。
- 反序列化 ,并遍历集合,打印对象信息。
- 把若干学生对象 ,保存到集合中。
- 把集合序列化。
- 反序列化读取时,只需要读取一次,转换为集合类型。
- 遍历集合,可以打印所有的学生信息
平时我们在控制台打印输出,是调用方法和方法完成的,各位用了这么久的输出语句肯定没想过这两个方法都来自于类吧,哈哈。该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。
打印流分类:
字节打印流PrintStream,字符打印流PrintWriter
打印流特点:
A:只操作目的地,不操作数据源
B:可以操作任意类型的数据
C:如果启用了自动刷新,在调用println()方法的时候,能够换行并刷新
D:可以直接操作文件
这个时候有同学就要问了,哪些流可以直接操作文件呢?答案很简单,如果该流的构造方法能够同时接收File和String类型的参数,一般都是可以直接操作文件的!
PrintStream是OutputStream的子类,PrintWriter是Writer的子类,两者处于对等的位置上,所以它们的API是非常相似的。二者区别无非一个是字节打印流,一个是字符打印流。
我想各位对这个Properties类多多少少也接触过了,首先Properties类并不在IO包下,那为啥要和IO流一起讲呢?原因很简单因为properties类经常和io流的联合一起使用。
(1)是一个集合类,Hashtable的子类
(2)特有功能
A:public Object setProperty(String key,String value)
B:public String getProperty(String key)
C:public SetstringPropertyNames()
(3)和IO流结合的方法
把键值对形式的文本文件内容加载到集合中
public void load(Reader reader)
public void load(InputStream inStream)
把集合中的数据存储到文本文件中
public void store(Writer writer,String comments)
public void store(OutputStream out,String comments)
继承于 ,来表示一个持久的属性集。它使用键值结构存储数据,每个键及其对应值都是一个字符串。该类也被许多Java类使用,比如获取系统属性时, 方法就是返回一个对象。
:创建一个空的属性列表。
- : 保存一对属性。
- :使用此属性列表中指定的键搜索属性值。
- :所有键的名称的集合。
: 从字节输入流中读取键值对。
参数中使用了字节输入流,通过流对象,可以关联到某文件上,这样就能够加载文本中的数据了。现在文本数据格式如下:
加载代码演示:
文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。
怎么说呢,io流的基础回顾就先告一段落了,浅尝辄止。循序渐进,实践中慢慢总结!更何况我还很low,依旧任重而道远。
现在jdk已经出到13了,io流也有了许多的变化。有时间会从头整理一下,一定会有机会的!
最后,欢迎各位关注我的公众号,一起探讨技术,向往技术,追求技术...

版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/15188.html