
- ElasticSearch对电脑配置要求较高,内存至少4G以上,空闲2G内存,线程数4018+
- 学习的时候,推荐将ElasticSearch安装到Linux或者mac上,极度不推荐装Windows上(坑太多,服务器部署的时候,也不会部署到Window上,学习用Windows上玩,不是耽误自个时间麽)。如果是Window用户想学这个,电脑自身至少16G,然后装虚拟机,在虚拟机上搞个Linux玩
- Linux系统不建议装6/6.5版本的(启动的时候,会检查内核是否3.5+,当然可以忽略这个检查),推荐装7+
- 自身电脑配置不高的话,怎么办呢?土豪做法,去买个云服务器叭,在云服务器上玩
上面第1、2点未满足,又舍不得去买云服务器的小伙伴,就不要往下面看了,看了也白看,ElasticSearch对电脑配置要求较高,前置条件未满足的话,服务是起不来的。
我演示的时候,是用的mac系统,上面装了个虚拟机,虚拟机版本Centos6.5,jdk用的13,ElasticSearch用的版本是 7.8.1。这些我使用的包我下面也会提供,为了学习的话,尽量和我使用的版本一致,这样大家碰到的问题都一样,安装过程中,我也猜了不少坑,都总结出来了,仔细阅读文档就可以捣鼓出来。
常用的搜索网站:百度、谷歌
指具有固定格式或有限长度的数据,如数据库,元数据等。对于结构化数据,我们一般都是可以通过关系型数据库(mysql、oracle)的table的方法存储和搜索,也可以建立索引。通过b-tree等数据结构快速搜索数据
全文数据,指不定长或无固定格式的数据,如邮件,word等。对于非结构化数据,也即对全文数据的搜索主要有两种方式:顺序扫描法,全文搜索法
顺序扫描法
我们可以了解它的大概搜索方式,就是按照顺序扫描的方式查找特定的关键字。比如让你在一篇篮球新闻中,找出“科比”这个名字在那些段落出现过。那你肯定需要从头到尾把文章阅读一遍,然后标出关键字在哪些地方出现过
这种方式毋庸置疑是最低效的,如果文章很长,有几万字,等你阅读完这篇新闻找到“科比”这个关键字,那得花多少时间
全文搜索
对非结构化数据进行顺序扫描很慢,我们是否可以进行优化?把非结构化数据想办法弄得有一定结构不就好了嘛?将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对这些有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种方式就构成了全文搜索的基本思路。这部分从非结构化数据提取出的然后重新组织的信息,就是索引。
根据百度百科中的定义,全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每个词,对每个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。
- Lucene是一个Java全文搜索引擎,完全用Java编写。lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能
- 通过简单的API提供强大的功能
- 可扩展的高性能索引
- 强大,准确,高效的搜索算法
- 跨平台解决方案
- Apache软件基金会
- 在Apache软件基金会提供的开源软件项目的Apache社区的支持
- 但是Lucene只是一个框架,要充分利用它的功能,需要使用Java,并且在程序中集成Lucene。需要很多的学习了解,才能明白它是如何运行的,熟练运用Lucene确实非常复杂
- Solr是一个基于Lucene的Java库构建的开源搜索平台。它以友好的方式提供Apache Lucene的搜索功能。它是一个成熟的产品,拥有强大而广泛的用户社区。它能提供分布式索引,复制,负载均衡以及自动故障转移和恢复。如果它被正确部署然后管理的好,他就能够成为一个高可用,可扩展且容错的搜索引擎
- 强大功能
- 全文搜索
- 突出
- 分面搜索
- 实时索引
- 动态集群
- 数据库集成
- NoSQL功能和丰富的文档处理
- ElasticSearch是一个开源,是一个机遇Apache Lucene库构建的Restful搜索引擎
- ElasticSearch是Solr之后几年推出的。它提供了一个分布式,多租户能力的全文搜索引擎,具有HTTP Web页面和无架构JSON文档。ElasticSearch的官方客户端提供Java、Php、Ruby、Perl、Python、.Net和JavaScript
- 主要功能
- 分布式搜索
- 数据分析
- 分组和聚合
- 应用场景
- 维基百科
- Stack Overflow
- GitHub
- 电商网站
- 日志数据分析
- 商品价格监控网站
- BI系统
- 站内搜索
- 篮球论坛
注意,我使用的linux搭建的,当然Window(极度不推荐,坑太多)也能搭建,ElasticSearch安装前需要先安装jdk,这里我使用的是jdk13,因为linux自带jdk版本,需要先将之前的jdk版本卸载(点我直达),在安装指定的jdk版本!!!
开发环境,建议关闭防火墙,避免不必要的麻烦!!!!生产环境,视情况开启端口号!!!!
ElasticSearch是强依赖jdk环境的,所以一定要安装对应的jdk版本,并配置好相关的环境变量,比如ES7.X版本要装jdk8以上的版本,而且是要官方来源的jdk。启动的时候有可能会提示要装jdk11,因为ES7以上官方都是建议使用jdk11,但是一般只是提示信息,不影响启动。
ES官网推荐JDK版本兼容地址:点我直达
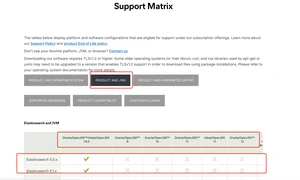
ES强依赖JVM,也很吃内存,所以一定要保证你的机器至少空闲出2G以上内存。推荐使用Linux,可以本地搭建虚拟机。
启动一定要使用非root账户!!!!这是ES强制规定的。ElasticSearch为了安全考虑,不让使用root启动,解决办法是新建一个用户,用此用户进行相关的操作。如果你用root启动,会报错。如果是使用root账户安装ES,首先给安装包授权,比如chown -R 777 安装包路径。然后再使用非root账户启动,具体的权限配置,根据自己想要的配置。
高版本的ElasticSearch自带jdk版本的,Linux中我安装的是jdk13,没用ElasticSearch自带的jdk,有兴趣的小伙伴可以去研究下。
官网地址:点我直达
1、修改elasticsearch-x.x.x/config/elasticsearch.yml,主要修改成以下内容
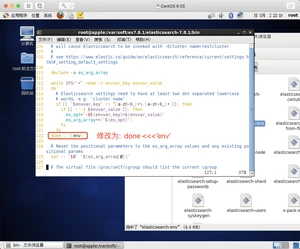
2、来到elasticsearch-x.x.x/bin下,执行:sh elasticsearch启动,报错,修改配置文件elasticsearch-env
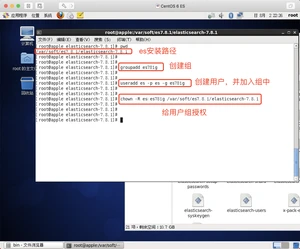
3、设置用户和组
注意=================以上root用户操作===============
注意=================以下es用户操作================
注意:若es用户密码登录不上,在回到root用户下,修改es用户的密码,语法:passwd 要修改用户名
4、登录到es用户下,继续启动ElasticSearch,执行:sh elasticsearch
5.继续启动ElasticSearch,执行:sh elasticsearch
修改一下内容需要使用root权限
修改完之后,一定要重启,重启,重启,重要的事儿说三遍!!!!!
上面第2条问题,线程数修改不了,可以尝试使用这个方法修改线程数
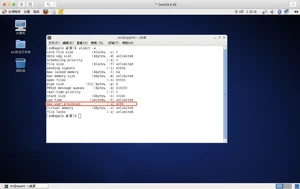
1、第一次配置过程中,踩了不少坑,我踩过的坑,都在上面记录了
2、如果照我上面哪个方法还解决不了,自行根据ElasticSearch日志,百度去找答案叭····
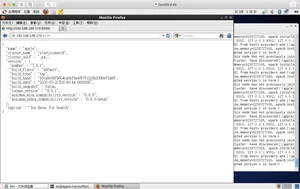
打开浏览器输入:127.0.0.1:9200

传统数据库查询数据的操作步骤是这样的:建立数据库->建表->插入数据->查询
一个索引可以理解成一个关系型数据库
一个type就像一类表,比如user表、order表
注意
1、ES 5.X中一个index可以有多种type
2、ES 6.X中一个index只能有一种type
3、ES 7.X以后已经移除type这个概念
mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构
一个document相当于关系型数据库中的一行记录
相当于关系型数据库表的字段
集群由一个或多个节点组成,一个集群由一个默认名称“elasticsearch”
集群的节点,一台机器或者一个进程
- 副本是分片的副本。分片有主分片(primary Shard)和副本分片(replica Shard)之分
- 一个Index数据在屋里上被分布在多个主分片中,每个主分片只存放部分数据
- 每个主分片可以有多个副本,叫副本分片,是主分片的复制
- RESTful是一种架构的规范与约束、原则,符合这种规范的架构就是RESTful架构
- 先看REST是什么意思,英文Representational state transfer表述性状态转移,其实就是对资源的标书性状态转移,即通过HTTP动词来实现资源的状态扭转
- 资源是REST系统的核心概念。所有的设计都是以资源为中心
- elasticsearch使用RESTful风格api来设计的
Postman工具(推荐)
curl工具
获取elasticcsearch状态
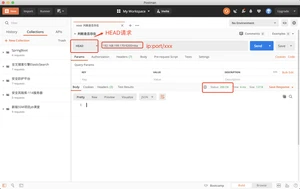
新建一个文档
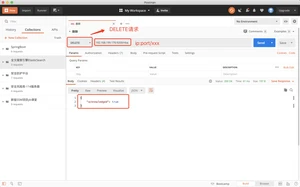
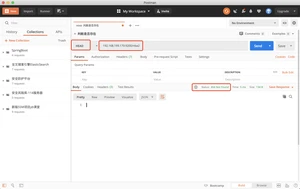
删除一个文档
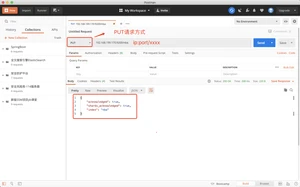
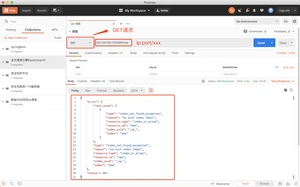
批量获取
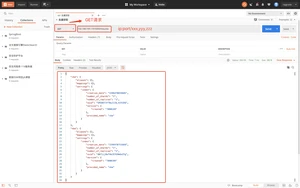
方式一
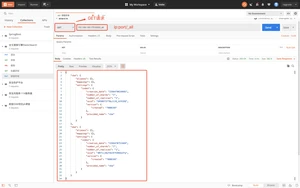
方式二
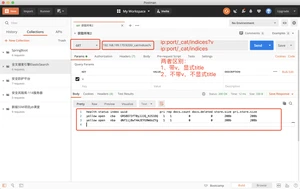
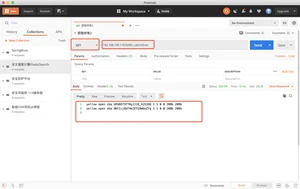
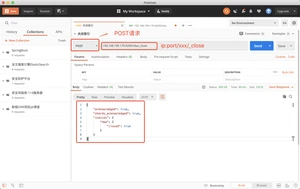
此时再次查询nba时,返回json会多一行
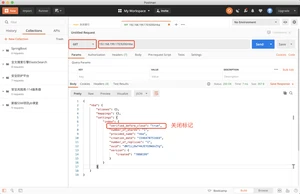
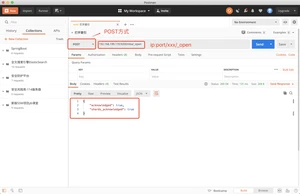
关闭索引标记消失
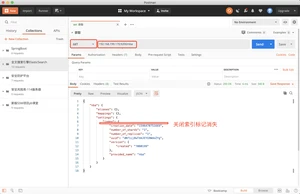
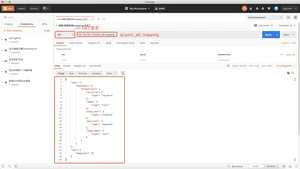
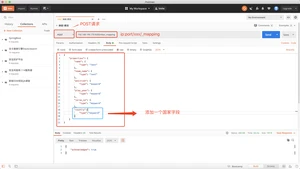
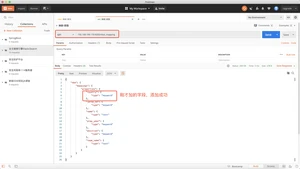
定义索引的结构,之前定义一个nba索引,但是没有定义他的结构,我们现在开始建立mapping;
type="keyword":是一个关键字,不会被分词
type="text":会被分词,使用的是全文索引
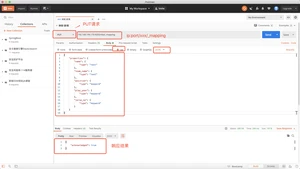
json格式
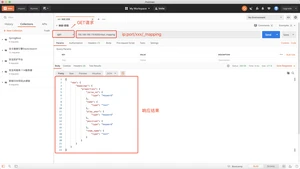
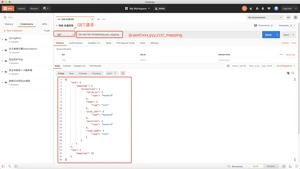
方式一
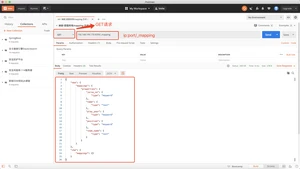
方式二
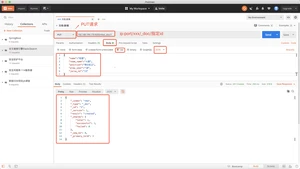
踩坑(要POST请求)
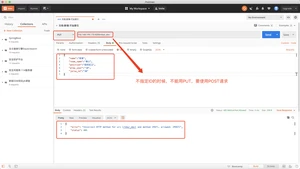
PUT请求改POST
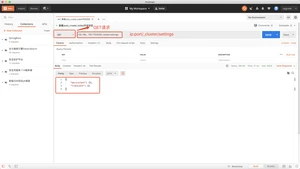
- 查看auto_create_index开关状态,请求:http://ip:port/_cluster/settings
- 当索引不存在并且auto_create_index为true的时候,新增文档时会自动创建索引
- 修改auto_create_index状态
- put方式:ip:port/_cluster/settings
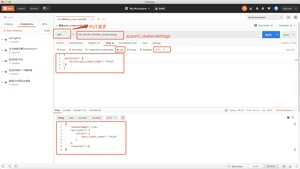
当auto_create_index=false时,指定一个不存在的索引,新增文档
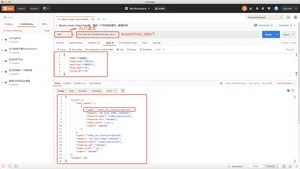
PUT请求:ip:port/xxx/_doc/1?op_type=create
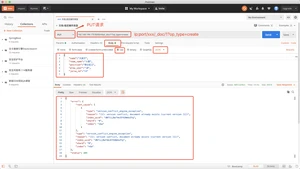
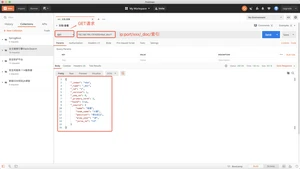
方式一
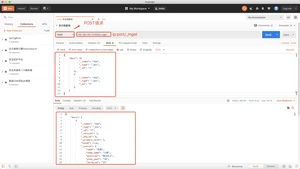
方式二
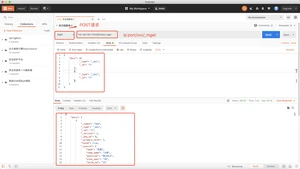
方式三
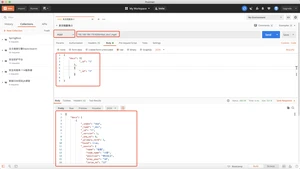
方式四
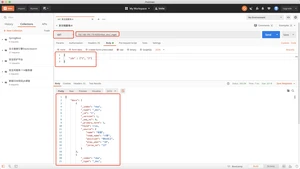
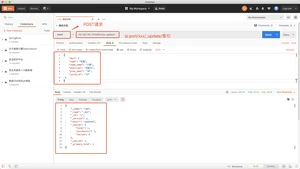
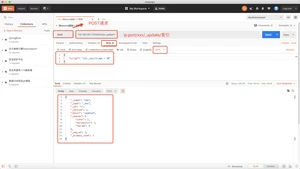
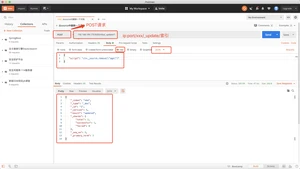
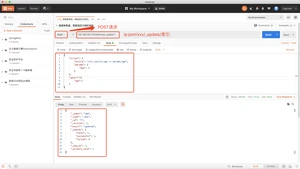
upsert当指定的文档不存在时,upsert参数包含的内容将会**入到索引中,作为一个新文档;如果指定的文档存在,ElasticSearch引擎将会执行指定的更新逻辑。
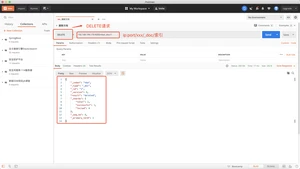
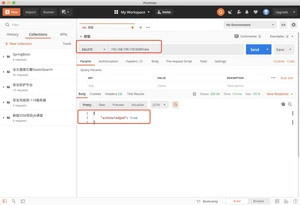
并指定mapping
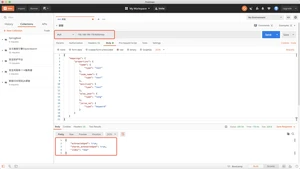
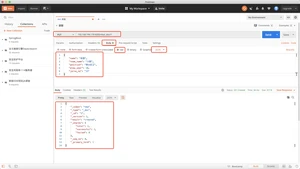
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时,才匹配搜索。
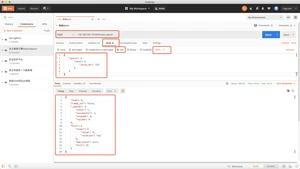
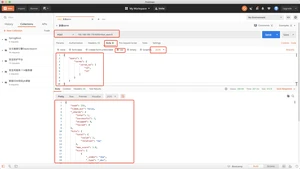
ElasticSearch引擎会先分析查询字符串,将其拆分成多个分词,只要已分析的字段中包含词条的任意一个,或全部包含,就匹配查询条件,返回该文档;如果不包含任意一个分词,表示没有任何问的那个匹配查询条件
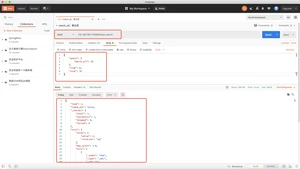
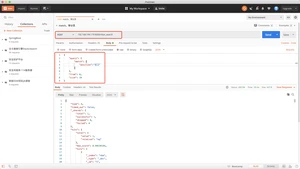
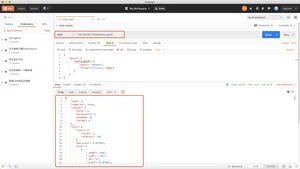
类似于词条查询,精准查询
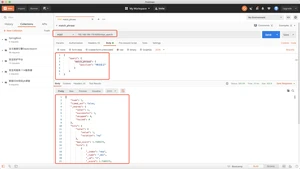
前缀匹配
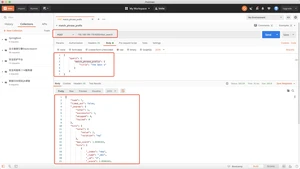
- 将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具
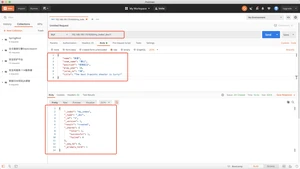
- example:The best 3-points shooter is Curry!
- standard analyzer
- simple analyzer
- whitespace analyzer
- stop analyzer
- language analyzer
- pattern analyzer
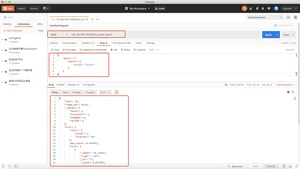
标准分析器是默认分词器,如果未指定,则使用该分词器
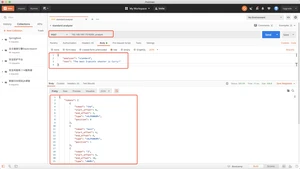
simple分析器当他遇到只要不是字母的字符,就将文本解析成term,而且所有的term都是小写的
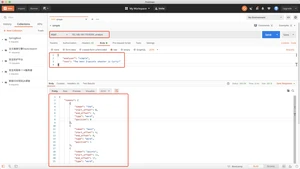
whitespace分析器,当他遇到空白字符时,就将文本解析成terms
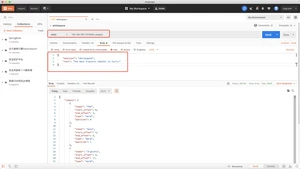
stop分析器和simple分析器很想,唯一不同的是,stop分析器增加了对删除停止词的支持,默认使用了english停止词
stopwords预定义的停止词列表,比如(ths,a,an,this,of,at)等等

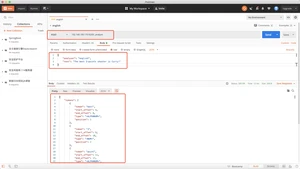
用正则表达式将文本分割成sterms,默认的正则表达式是W+
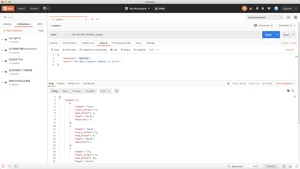
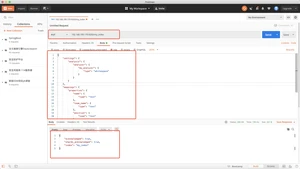
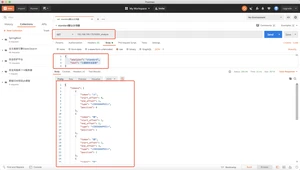
- smartCN一个简单的中文或中英文混合文本的分词器
- IK分词器,更智能更友好的中文分词器
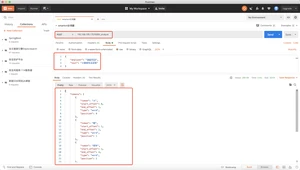
- sh elasticsearch-plugin install analysis-smartcn
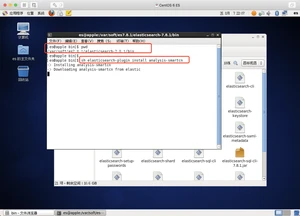
校验
安装后重启
卸载
sh elasticsearch-plugin remove analysis-smartcn
下载地址:点我直达
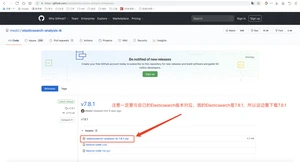
安装,解压到plugins目录
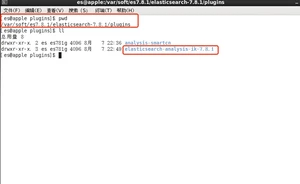
然后重启
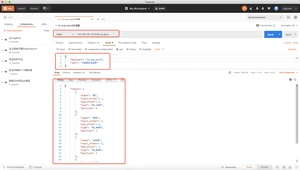
- 核心数据类型
- 复杂数据类型
- 专用数据类型
- text:用于全文索引,该类型的字段将通过分词器进行分词
- keyword:不分词,只能搜索该字段的完整的值
- long、integer、short、byte、double、float、half_float、scaled_float
- boolean
- binary:该类型的字段把值当做经过base64编码的字符串,默认不存储,且不可搜索
- 范围类型表示值是一个范围,而不是一个具体的值
- integer_range、float_range、long_range、double_range、date_range
- 比如age类型是integer_range,那么值可以是{"gte":20,"lte":40};搜索"term":{"age":21}可以搜索该值
由于json类型没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型
format默认为:strict_date_optional_time || epoch_millis
格式
从开始纪元(1970年1月1日0点)开始的毫秒数
- ES中没有专门的数据类型,直接使用[]定义接口,数组中所有的值必须是同一种数据类型,不支持混合数据类型的数组
- 字符串数组["one","two"]
- 整数数组[1,2]
- Object对象数组[{"name":"alex","age":18},{"name":"tom","age":18}]
索引方式
IP类型的字段用于存储IPv4和IPv6的地址,本质上是一个长整形字段
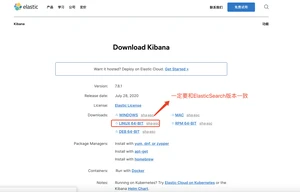
可视化工具kibana的安装和使用
点我直达
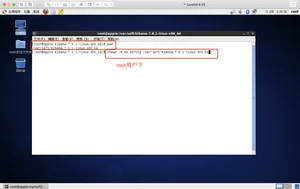
赋权限
kibana.yml
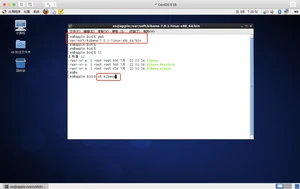
ip:5601
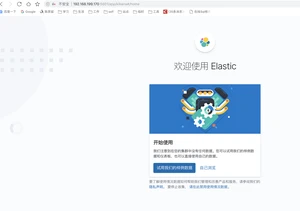
后面示例,会大量使用该工具

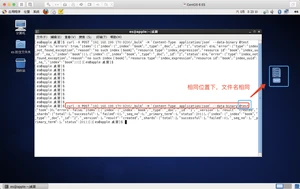
手把手教你批量导入数据
ES提供了一个叫bulk的API来进行批量操作
数据
- 单词级别查询
- 这些查询通常用于结构化的数据,比如:number,data,keyword等,而不是对text
- 也就是说,全文查询之前要先对文本内容进行分词,而单词级别的查询直接在相应字段的反向索引中精确查找,单词级别的查询一般用于数值、日期等类型的字段上
- 删除nba
- 新增nba索引
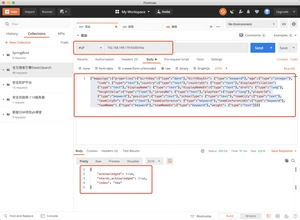
- 批量导入player
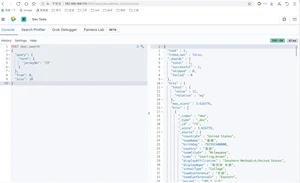
Exsit Query在特定的字段中查找非空值的文档(查找队名非空的球员)
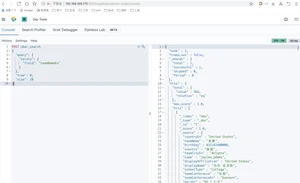
Prefix Query查找包含带有指定前缀term的文档(查找队名为Rock开头的球员)
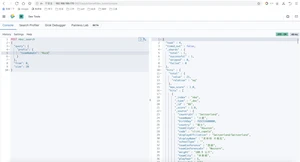
Wildcard Query支持通配符查询,*表示任意字符,?表示任意单个字符(查找火箭队的球员)
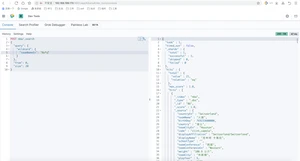
Regexp Query正则表达式查询(查找火箭队的球员)
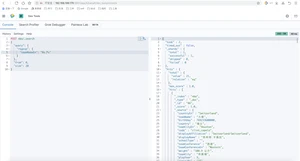
Ids Query(查找id为1和2的球员)
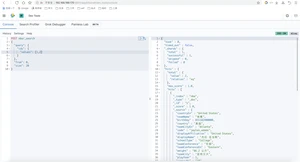
查询指定字段在指定范围内包含值(日期、数字或字符串)的文档
查找在nba打球在2年到10年以内的球员
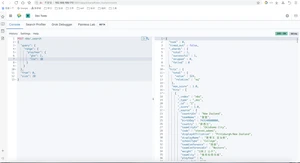
查找1999年到2020年出生的球员
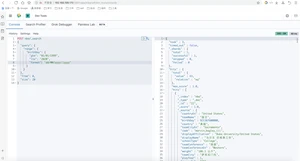
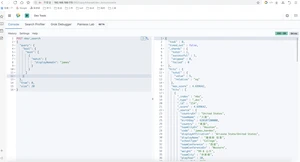
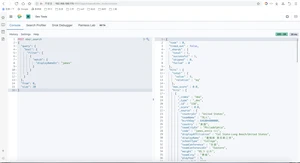
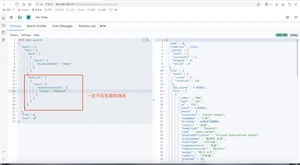
组合起来含义:一定不在东部的james
即使匹配不到也返回,只是评分不同
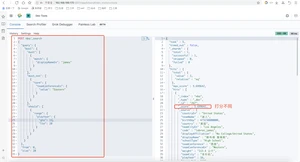
如果minimum_should_match=1,则变成要查出名字叫做James的打球时间在11年到20年西部球员
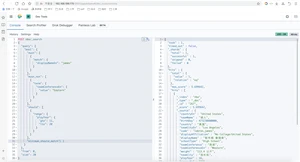
minimum_should_match代表了最小匹配经度,如果设置minimum_should_match=1,那么should语句中至少需要有一个条件满足
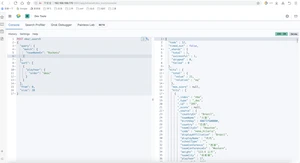
火箭队中按打球时间从大到小,如果年龄相同则按照身高从高到低排序的球员
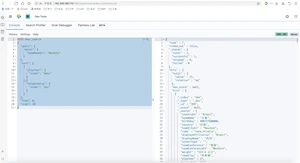
- 聚合查询是数据库中重要的功能特性,完成对一个查询得到的数据集的聚合计算,如:找出某字段(或计算表达式的结果)的最大值,最小值,计算和,平均值等。ES作为搜索引擎,同样提供了强大的聚合分析能力
- 对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合
- 而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行指标聚合。在ES中称为“桶聚合”
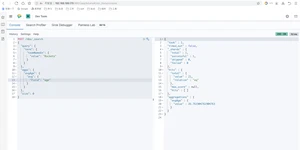
求出火箭队中球员打球时间不为空的数量
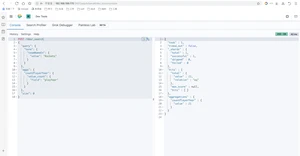
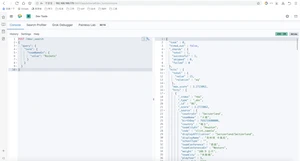
查出火箭队中年龄不同的数量
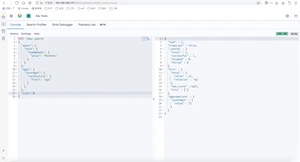
查出火箭队球员的年龄stats
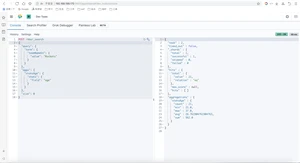
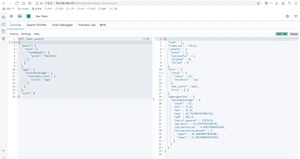
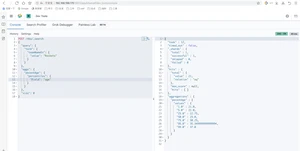
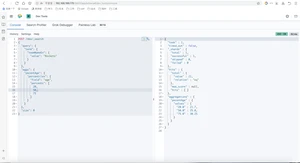
- 聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出字段(或计算表达式的结果)的最大值、最小值、计算和、平均值等。ES作为搜索引擎兼容数据库,同样提供了强大的聚合分析能力
- 对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合
- 而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行游标聚合。在ES中称为桶聚合
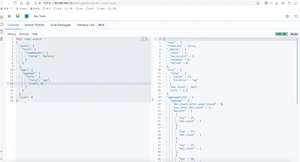
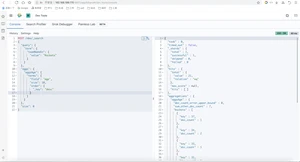
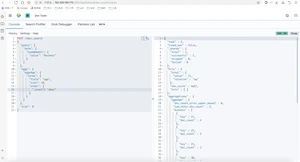
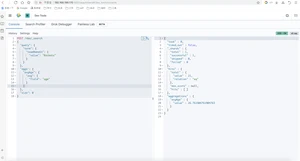
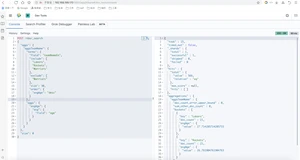
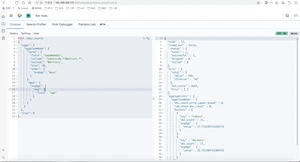
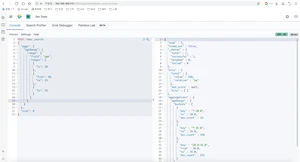
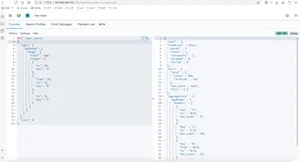
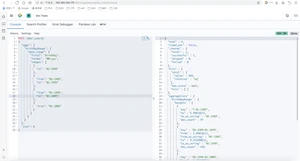
NBA球员按出生年分组
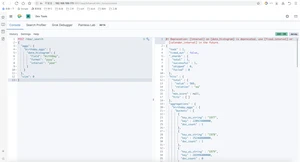
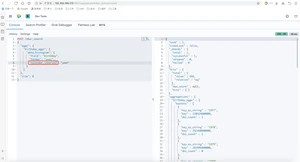
query_string查询,如果熟悉lucene的查询语法,我们可以直接用lucene查询语法写一个查询串进行查询,ES中接到请求后,通过查询解析器,解析查询串生成对应的查询。
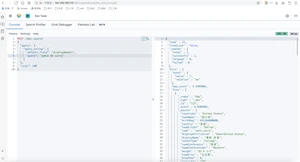
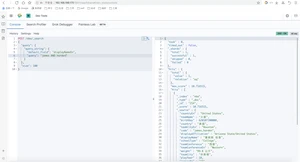
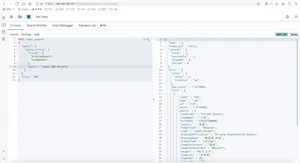
在开发中,随着业务需求的迭代,较老的业务逻辑就要面临更新甚至是重构,而对于es来说,为了适应新的业务逻辑,可能就要对原有的索引做一些修改,比如对某字段做调整,甚至是重构索引。而做这些操作的时候,可能会对业务造成影响,甚至是停机调整等问题。由此,es提供了索引别名来解决这些问题。索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任意一个需要索引名的API来使用。别名的应用为程序提供了极大地灵活性。
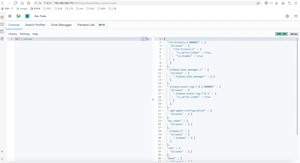
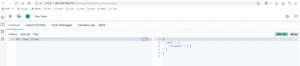
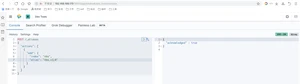
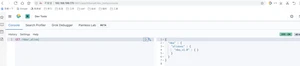
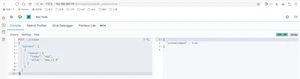
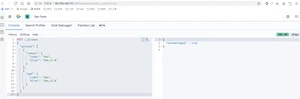
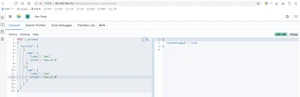
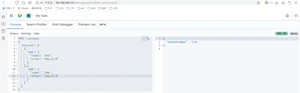
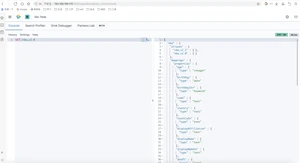
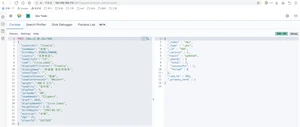
ElasticSearch是一个实时的分布式搜索引擎,为用户提供搜索服务,当我们决定存储某种数据时,在创建索引的时候需要将数据结构完整确定下来,于此同时索引的设定和很多固定配置将不能修改。当需要改变数据结构时,就需要重新建立索引,为此,Elastic团队提供了很多辅助工具帮助开发人员进行重建索引
- nba取一个别名nba_latest,nba_latest作为对外使用
- 新增一个索引nba_,结构复制于nba索引,根据业务要求修改字段
- 将nba数据同步至nba_
- 给nba_添加别名nba_latest,删除此处nba别名nba_latest
- 删除nba索引
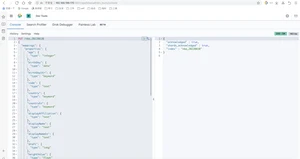
同步等待,接口将会在reindex结束后返回
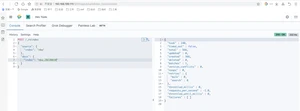
异步执行,如果reindex时间过长,建议加上“wait_for_completion=false”的参数条件,这样reindex将直接返回taskId
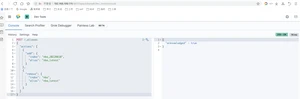
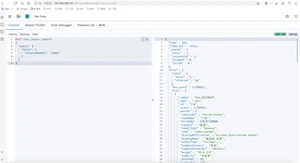
新的数据一添加到索引中立马就能搜索到,但是真实情况不是这样的
我们使用链式命令请求,先添加一个文档,再立刻搜索
强制刷新
修改默认更新时间(默认时间是1s)
将refresh关闭
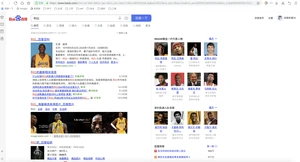
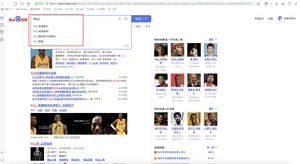
如果返回的结果集中很多符合条件的结果,那怎么能一眼就能看到我们想要的那个结果呢?比如下面网站所示的那样,我们搜索“科比”,在结果集中,将所有“科比”高亮显示?
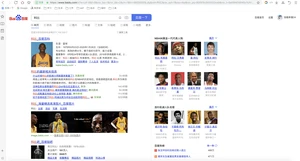
查询建议:是为了给用户提供更好的搜索体验。包括:词条检查,自动补全
- Term suggester
- Phrase suggester
- Completion suggester
如何对建议词进行排序,可用选项:
score:先按评分排序、再按文档频率排、term顺序
frequency:先按文档频率排,再按评分,term顺序排
suggest_mode建议模式,控制提供建议词的方式:
missing:仅在搜索的词项在索引中不存在时才提供建议词,默认值;
popular:仅建议文档频率比搜索词项高的词
always:总是提供匹配的建议词
term词条建议器,对给输入的文本进行分词,为每个分词提供词项建议
phrase短语建议,在term的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻成都,以及词频等
Completion完成建议
ElasticSearch 7.8.1集群搭建
Spring Boot整合ElasticSearch和Mysql 附案例源码
点我直达
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/17308.html