
Apache Arrow是一个开源的跨平台数据层开发框架,主要提供高效的、硬件加速的内存中数据计算能力。Apache Arrow的设计初衷是作为“新一代大数据系统的共享基础”,可以作为不同系统之间进行高效数据交换的媒介,同时提供快速、低延迟的数据访问接口。
Apache Arrow的主要目标是通过提供一个开放的标准,解决大数据领域常见的问题:大量的数据复制和序列化/反序列化操作所带来的性能问题,以及跨平台和跨语言环境下的数据兼容性问题。具体的,Apache Arrow的优势有以下几个方面:
- Apache Arrow的列式内存格式设计优化了数据的随机访问,让每次数据访问的复杂度达到了O(1),即无论数据的规模大小,数据的访问时间都保持常数。这种设计能够更好地利用现代硬件的特性,如CPU的缓存局部性、流水线和SIMD指令集,从而进一步提升数据处理的效率。同时列式存储可以高效地执行数据密集型的计算操作,如过滤、排序和聚合等。
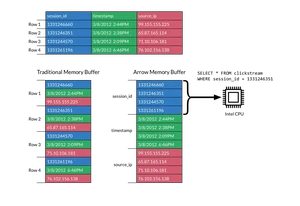
- Apache Arrow实现了一套标准的、跨语言的数据交换协议,采用了零拷贝(Zero-Copy)的设计理念,能够在不同语言、不同数据处理框架之间共享数据,而无需进行数据的转换和复制操作。
总的来说,Apache Arrow正在重新定义我们如何在大规模数据环境下进行高效、灵活的数据处理和计算。在接下来的文章中,我们将深入探讨Apache Arrow的各个方面,以便更好地理解其工作原理和实际应用。
Apache Arrow的数据模型设计主要基于列式存储,这种设计方式允许数据被组织和存储为一系列的列,而不是传统的行。在这种模型下,每一列的数据都存储在一起,而不是与其他列的数据混杂在一起。这种模型对于数据分析非常有效,因为数据分析通常是基于列的(比如计算一个字段的平均值或者统计某个字段的唯一值的个数)。
在Java SDK中,Arrow的ValueVector均为off-heap的,也就是说我们需要手动去管理对象的生命周期,避免内存泄漏的问题。
在Apache Arrow中,有一些关键的抽象概念,它们形成了Apache Arrow数据处理框架的基础。本文将之分为数据相关和内存相关。
其中数据相关概念包括、、、以及,下面将对它们进行详细的解释。
ValueVector代表一列相同类型的值,每个实例代表一个字段,其中包含了该字段的所有值。Apache Arrow提供了各种各样的的子类,用来表示各种类型的数据,比如用于表示整数,用于表示字符串等。类似的,还有等等
Field表示某一列的元数据,包括列名、列类型、是否允许为null,以及一个元数据映射。每个对象都与一个对象对应,对象描述了的元数据信息。
Schema是一系列的组合,它描述了表格的结构,也可以包含一个元数据映射。
VectorSchemaRoot是由和组合的关键抽象,它可以表示完整的表格数据。你可以理解为行存储中的。
下面是一个创建的例子:
输出:
在这个例子中,我们创建了一个包含两列的表格,分别是"age"和"name"。然后我们在这个表格中添加了3行数据。这个例子展示了如何使用Apache Arrow的Java SDK来创建和操作表格数据。
在实际应用中存在几个问题:
- 如果设计这样一个函数,在函数中就不能close任何资源,但是在函数外只能close 本身。
因此一个合理的实践可能是函数传入allocator,如,然后再函数外显式关闭和。
这里做了个实验,即如果只关闭,不关闭也是不会发生内存泄漏的,但是,这需要你非常小心地管理你的资源。
- 不可能将一个大表中所有数据都读进内存,当表特别大时,其只相当于一个batch的数据。因此流式处理数据,或包装成一个来返回可能是一个不错的选择。以下是一个流式处理的例子:
就像Immutable且不支持批处理的VectorSchemaRoot,可以通过API将VectorSchemaRoot的数据转移到一个Table中(注意是转移而非复制)
Table API 提供了一种以行为中心,基于列的方式处理内存中的大规模数据的高效方式。当你需要在 JVM 环境中处理大规模数据,并且希望能够高效地利用现代硬件的能力时,Table API 是一个非常好的选择。如果有必要(项目用到),后面可能单开一文总结下。
Arrow内存分配最底层的单位,包含内存的地址和偏移量,类似于ByteBuffer。其属于Direct Memory而非分配在heap上,以支持zero-copy的设计理念。
本身并不直接占有内存。的主要作用是跟踪和限制通过它分配的内存。在Apache Arrow中,内存分配是通过树形的分配器结构进行的,是这个结构的根。
由于Arrow主要使用non-heap memory,无法被JVM自行垃圾回收,因此其自行实现了垃圾回收机制。
Apache Arrow 中的内存管理模型使用了引用计数(reference counting)来跟踪和管理内存。当一个内存块被分配或者共享时,参考计数会增加,当内存不再被使用时,参考计数会减少。当参考计数减至零时,那么这块内存会被释放。
每个通过 Apache Arrow 分配器(Allocator)创建的数据结构都包含一个参考计数。例如,当你创建一个 Arrow 时,它的参考计数被设置为 1。如果你克隆这个 ,那么原始 和克隆的 都会指向同一块内存,而且这块内存的参考计数会增加到 2。当任何一个 不再被使用并调用 方法时,它会减少内存的参考计数。当所有的 都不再被使用时,参考计数会变为零,然后内存会被释放。
这个时候就来了一个八股文:引用计数和可达性分析相比有哪些优缺点?2333
Apache Arrow 提供了一种 IPC (进程间通信) 机制,使得在不同的进程,甚至不同的机器之间,可以无缝地共享和传输数据。Arrow IPC 机制能够在不进行数据复制的情况下,高效地传输大规模数据。
将 Arrow 序列化和反序列化在生产中十分常见,以下是一个简单的例子,针对小批量数据进行处理。
大规模数据通常需要分batch流式处理,上面介绍时候给出了流式读取处理的例子,另一种可行的方式返回一个,返回给函数调用者自行处理。
因为工作中要使用到Apache Arrow,本文学习并总结了Arrow最基础的知识,并局限于Java语言给出了一些实践。实际上,Arrow还有很多强大的进阶特性,如Compression、Arrow Flight,Dataset、Data manipulation、Avro、Arrow JDBC Adapter等,可能在后面的章节会讲。本人也由于能力有限,给出的实践可能并非高明,还望给位大佬多多指点。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/17482.html